|
www.tlab.it
Automatic
and Customized
Settings
The choice of automatic (A)
or customized (B) settings relates to
the list of Keywords Key-words used in
all analyses performed with T-LAB. This choice is reversible until the
user performs operations that modify the dictionary of the
corpus.
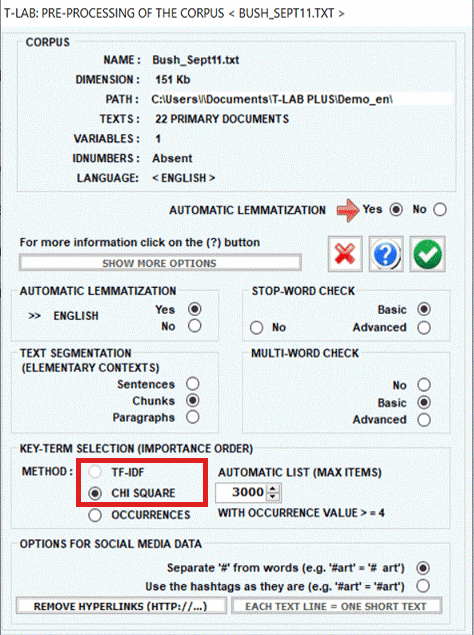
A) AUTOMATIC SETTINGS
When choosing automatic
settings the list of keywords includes up to a maximum of 5,000 lexical units
automatically selected by T-LAB, which belong to the category of content
words: nouns, verbs, adjectives and adverbs.
The selection criterion varies according to the kind of
file analysed.
If the corpus is a single text T-LAB simply selects the lexical units with
the highest occurrence values.
If the corpus is made up of two or more texts T-LAB uses the following algorithm:
· it selects the words with occurrence values higher than the
minimum threshold;
· it computes the TF-IDF or applies the
chi-square test to all the crosses of each
selected word for all the texts being analysed (N.B.: In the case
of chi square test, the maximum number of text allowed is 500);
· it selects the words with the TF-IDF or chi-square highest
values, that is those words that, in the corpus, make the
difference.
N.B.:
- In the case that the corpus consists of two or more texts, the
user can choose the selection criterion (CHI square or TF-IDF) in
the import stage (see below);
- when the automatic settings option is enabled, the
table with the list of Keywords includes a 'T-LAB' column which
indicates the importance of each item according to the selected
criterion (see below).
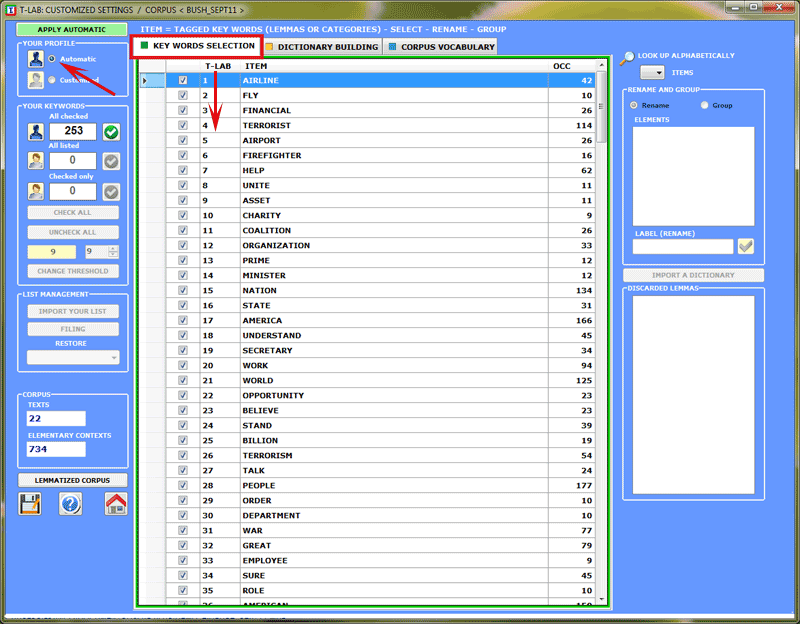
A) CUSTOMIZED SETTINGS
When choosing customized
settings the user is allowed to select, rename and
group the lexical units (i.e. words, lemmas or categories)
to be included in subsequent T-LAB analyses.
All the lexical
units with an occurrence value which is equal or superior
to the preset threshold are listed (list
1).
Some of these, that is those indicated with "v", belong to a
sub-list (list 2) create by T-LAB
(see automatic
settings).
Depending on the analyses to be performed, the user can
decide whether to use/modify the more extended list (1) or the
sub-list (2) of the T-LAB
key terms.
In both cases the operations available are the
following:
- change the threshold
value;
- select which lemmas are to
be excluded from analysis;
- restore one or more lemmas
for use;
By clicking either the list "(1)" or the list "(2)"
button the customized option of Analysis Settings is enabled
(see below).
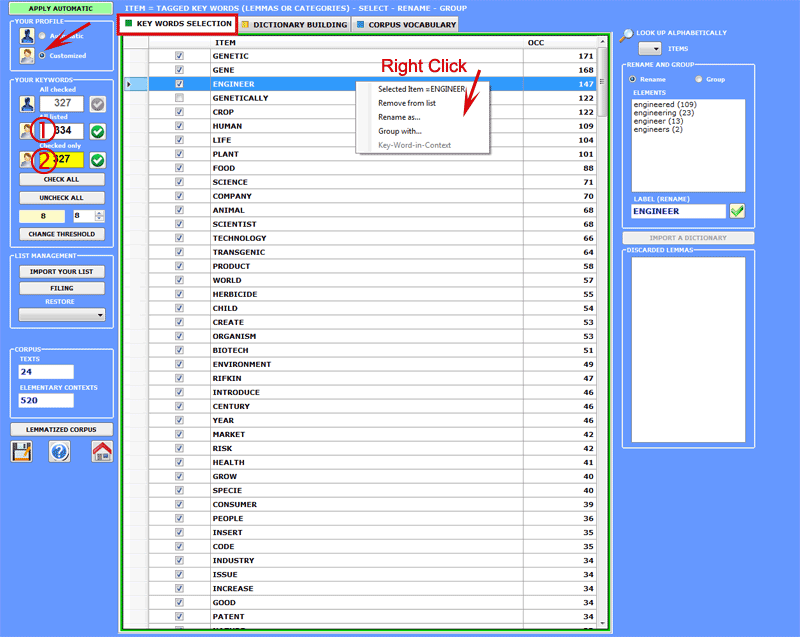
All options regarding interventions on individual
entries are accessed by right clicking the mouse on any item of the
table (see below).
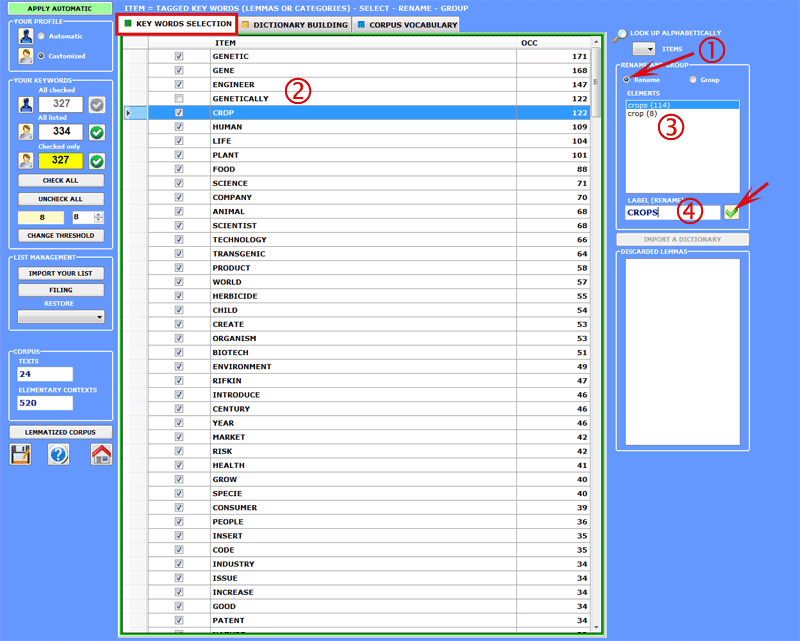
In order to change the label (i.e. rename) of a single lemma,
proceed as follows:
1. be sure that the "RENAME" option
is selected;
2. click on an item of the list;
3. select one word or type a new label in the appropriate box:
4. click on "RENAME".
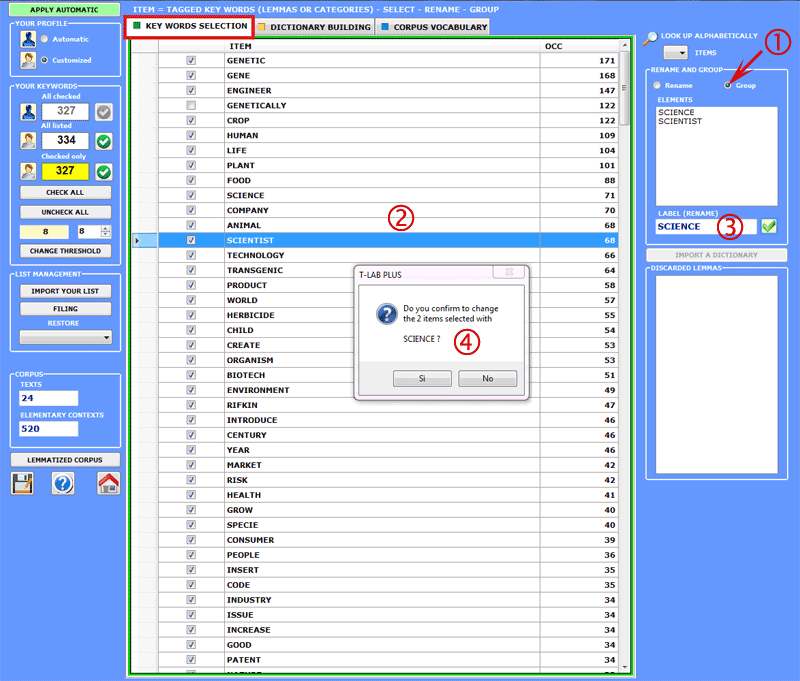
In order to group two or more lemmas, proceed as
follows:
1. be sure that the "GROUP" option is selected;
2. click on two or more items of the list;
3. select one lemma or type a new label in the appropriate box;
4. click on "REPLACE".
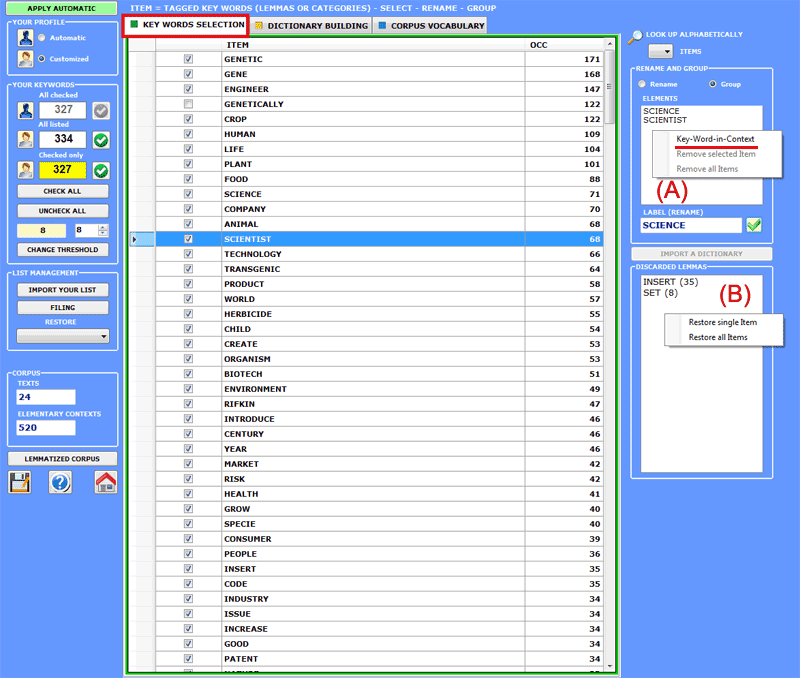
Additional options can be enabled
using the right click in the box with the items to be renamed /
grouped (A) or in the box with the discarded lemmas (B).
In particular, when - in the (A) case - the 'Key-Word-in-Context'
option is selected, the user can automatically access the
Concordances tool and check the occurrence contexts of the various
items (see below).
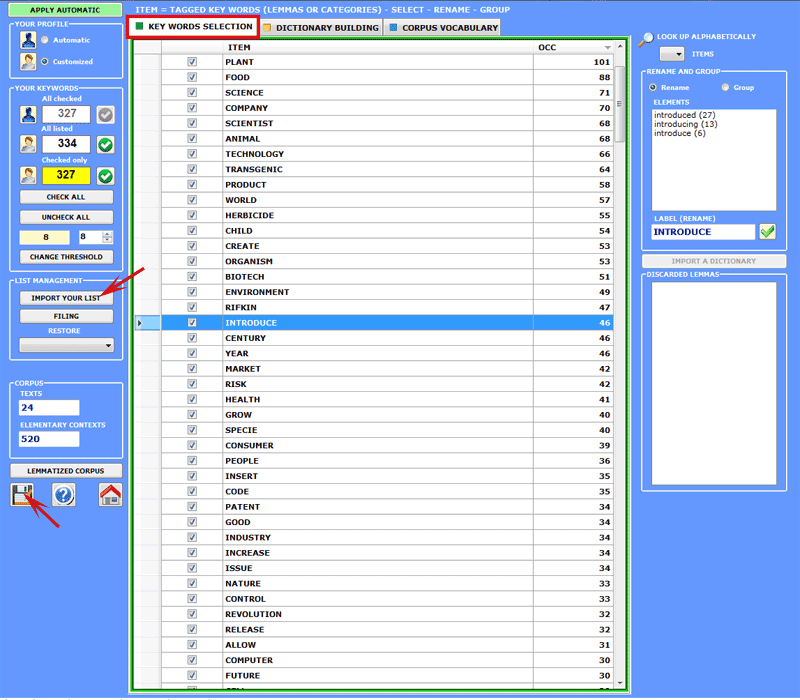
A specific button (see below) allows you to
import customized lists of
key-terms.
Each list to be imported, named MyList.diz, can include up a
maximum of 10,000 records (min = 20). Each record of your list must
be a single word with no spaces and no punctuation
marks.
A model of MyList.diz file is automatically created
by T-LAB
when saving any your word list (see the appropriate
button in the lower left).
The settings of each analysis
(up to a maximum of 10) can be saved and restored. That means that
the same corpus - without need of further
importation - can be analysed with several dictionaries and various
word selections (see the "Filing" and the
"Restore" options).
T-LAB allows
customized settings to be carried out and modified over several
sessions, even after operations like Dictionary building.
|


