|
www.tlab.it
Import-Export Identifiers
List
In T-LAB a
unique identifier is a categorical variable with a distinct value
for every document (or case).
A list of unique identifiers may consist of any type of
alphanumerical strings (e.g. Interviewee ID numbers, proper names,
geographical names, names of books etc.) up to 50 characters long
and without blank spaces.
As unique identifiers are singular, it's impossible to
perform any data analysis on them. Instead, they are used to
identify results in the software outputs.
In T-LAB, through the
import/export options, any unique identifier list can be modified
at any moment.
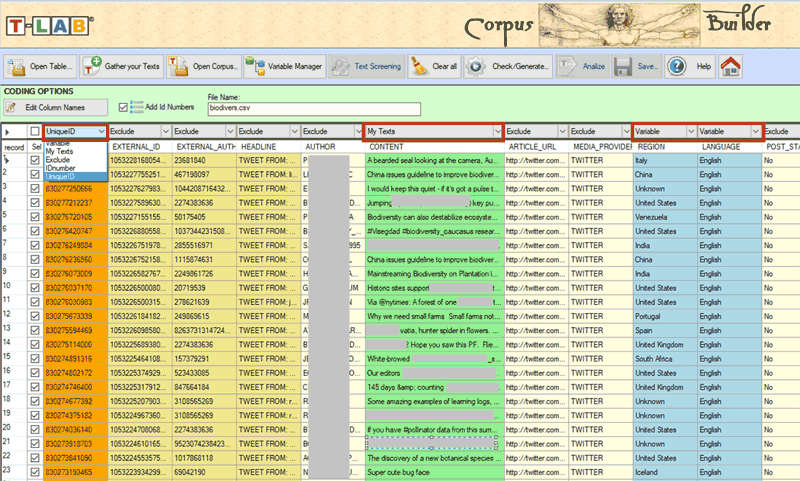
When importing data in tabular format, the unique
identifiers must be in the first column, like the following example
concerning Twitter messages.
In the other cases (i.e. document collections which
are not in tabular format) the recommend procedure is the
following:
1-Import your corpus first;
2-Export the list of the identifiers automatically created by
T-LAB.
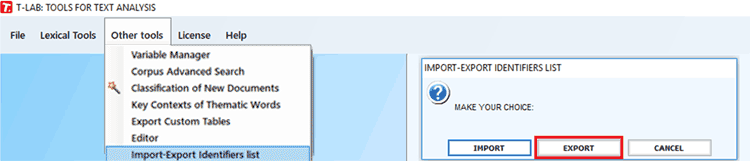
3-Edit and modify the CSV file created by T-LAB (i.e. just modify
the 'MyIdentifier' values according to your needs. See picture
below).

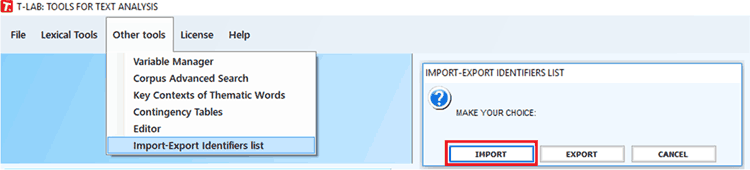
4- Import the CSV file which includes your reviewed unique
identifiers.
|


