|
www.tlab.it
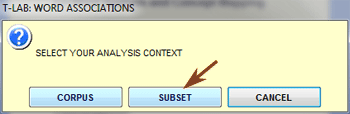
Corpus and Sub-sets
A corpus is a collection of one or more texts
selected for analysis.
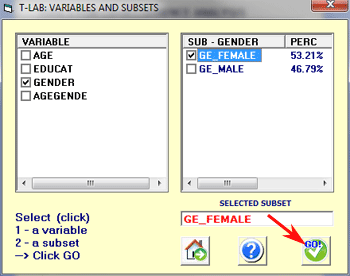
Each corpus subset is
defined by means of a category of a
variable.
T-LAB
makes it possible to explore and to analyse the
relationships between the analysis units of the whole corpus or its subsets.
Some corpus examples:
- a single text or document concerning any subject;
- a set of articles taken from the press, concerning the
same subject;
- one or more interviews carried out inside the same
research project;
- a set of answers to an open-ended question;
- one or more focus group transcripts.
Some subset examples:
- one or more chapters of a book;
- one or more newspaper articles published in the same
year;
- one or more interviews with the same people
category;
- a subset of answers to an open-ended
question.
N.B.: Further corpus subsets are the "thematic clusters" of documents or
elementary contexts obtained by using the corresponding T-LAB
tools.
In the case of a corpus made up of more than one text, in
order to make it a set correctly
analysable, it is required that all of its parts have two
features that make them comparable:
a) a thematic and/or contextual homogeneity of their
content;
b) a balanced relationship between their dimensions, both
in terms of occurrences and in terms of Kbytes.
In T-LAB
logic, the corpus is a database set up
in records and fields. More precisely, records are made up of
recorded entities (texts, text segments, words) and fields are made
up of labels used to classify the different entities (text authors,
reference contexts, word types, etc.).
See Corpus Preparation.
|


