|
www.tlab.it
Word Segmentation
This T-LAB tool can be used before importing any
Chinese or Japanese text (*) which has no
delimiters (i.e. blank spaces and/or punctuation marks) between
words.
(*) Either a single document or a corpus made up of various texts
which include variable values can
be processed.
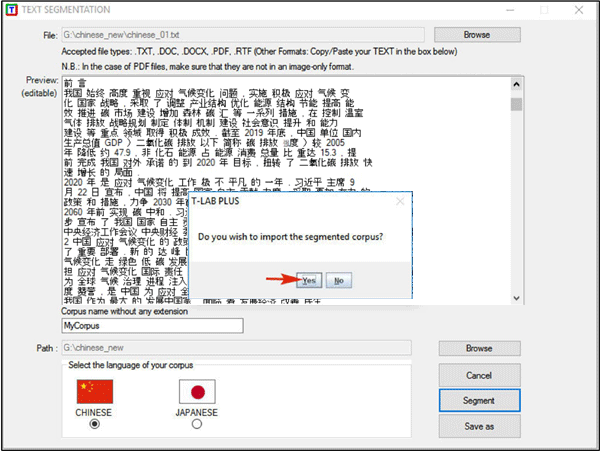
Its use is very simple (see the
below picture):
(1) select any file;
(2) choose the project name;
(3) select the language of your text;
(4) click on ‘Segment’.
As a result, blank spaces will be added between words.

Subsequently, if you want to proceed
with the importation process, just answer ‘yes’ to the
question "Do you wish to import the segmented corpus?" (see the
below picture).
N.B.: When you need to prepare a
corpus made up of various texts which include coding lines
(i.e.
categorical variables), we recommend you to proceed as follows:
1- ‘Gather’ the unsegmented texts (*) through the Corpus Builder tool and then ‘Save’ your
corpus file;
2 - Import the corpus just created
through the Word Segmentation tool, then proceed as explained
above.
(*) This means that, in order to prepare your corpus, you don’t
need to segment each single file in
advance.
|


