|
www.tlab.it
Thematic Document
Classification
This function is only enabled when the corpus under
analysis includes from 20 (min) to 99,999 (max) primary
documents.
The analysis process can be performed through an
unsupervised clustering (i.e bottom-up approach), which is the
default option, or a supervised classification (i.e. top-down
approach). When choosing the latter (i.e. supervised
classification), a dictionary of categories must be imported,
either created by means of a previous T-LAB analysis or made up by the user.
You can use this function to construct document clusters
and explore their characteristics by means of operations (including
algorithms) similar to those described in the section of the help
dedicated to Thematic Analysis of Elementary
Contexts.
The specificity of this function is that the table
analysed consists of one line for each document in the corpus, each
of which is represented as a vector of values indicating the
occurrences of the words found in it.
N.B.: When doing an unsupervised clustering and the
number of analysed documents doesn't exceed 3,000, it is possible
to obtain similarity measures (i.e. cosine) between each pair of
them (see below). However only the similarities with a cosine
coefficient greater or equal to 0.05 are recorded.
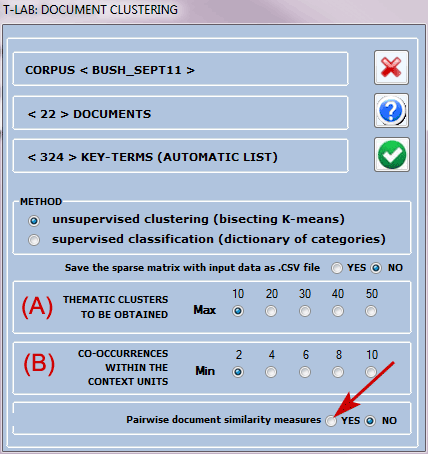
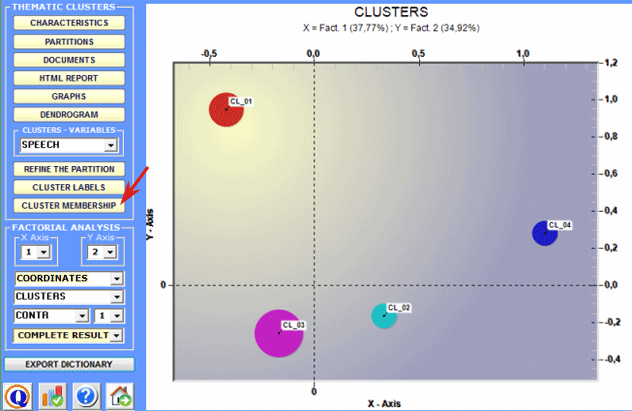
Accordingly the following outputs are different:
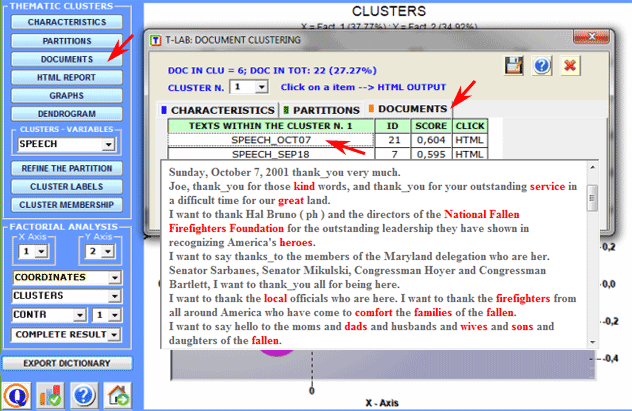
The documents belonging to each cluster are ordered by
their decreasing relevance value (see above) and can be browsed in
HTML format.
In this case the relevance value (score) assigned to each document
(i) in the cluster (k) is obtained by applying the following
formula:
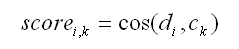
Where:
i - refers to document i;
k - refers to cluster k;
cos - is the cosine symbol;
di - is the normalized vector of TFj,i IDFj , where
j refers to word in document i;
ck - is the normalized vector of TFj,k IDFj, where
j refers to word in cluster k;
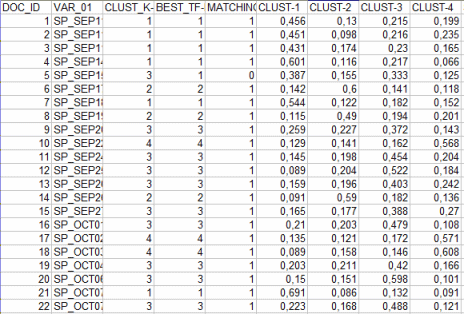
By using the scores obtained by the above formula,
transformed into percentage values, the file
"Document_Membership_Degree.xls" (see below) - containing the
clusters to which the documents are assigned, either by the
bisecting K-Means (mutual exclusive memberships) or the TF-IDF (mixed or fuzzy memberships) - is made
available by T-LAB.
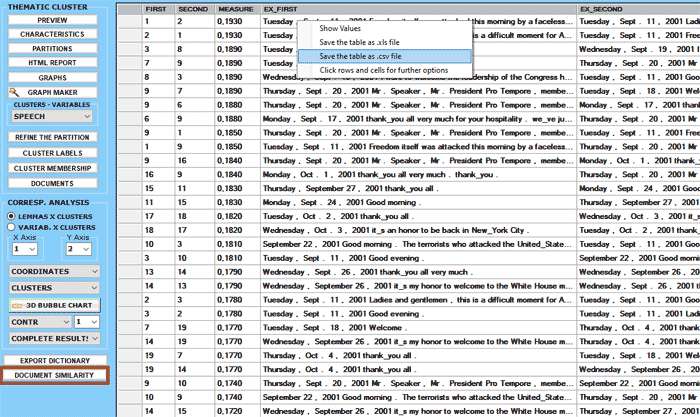
When the Document Similarity
button is enabled, by clicking it is possible to check how each
document is similar to the others.
As in other cases, the similarity measure is the cosine coefficient
and this can vary according to how many features (i.e. words) have
been used for the thematic classification.
Below is a short description of how this tool works.
When you exit this function, the software displays
messages to remind you that you can use other T-LAB tools to explore the clusters
obtained.
If you select "Save", the < DOC_CLUST> variable (document cluster)
remains available for all subsequent analyses of the corpus
performed with other T-LAB
tools.
|