|
www.tlab.it
Corpus Vocabulary
This T-LAB
tool allows us to check the Vocabulary of the corpus and its
subsets (see option '1' below).
Moreover some measures of lexical
richness are provided.
The Vocabulary table is a list
including all distinct words (i.e. word types), the frequency of
their occurrences (i.e. word tokens), their corresponding lemma (or label) and some categories used by
T-LAB (see
Glossary/Lemmatization).
The user can select (see option '2'
below) the lexical units which belong to each category, view the
corresponding table and save it as a .xls file (see option '3'
below).
In addition, by right clicking any item, you can check
its concordances (Key-Word-in-Context) (see option '4'
below).
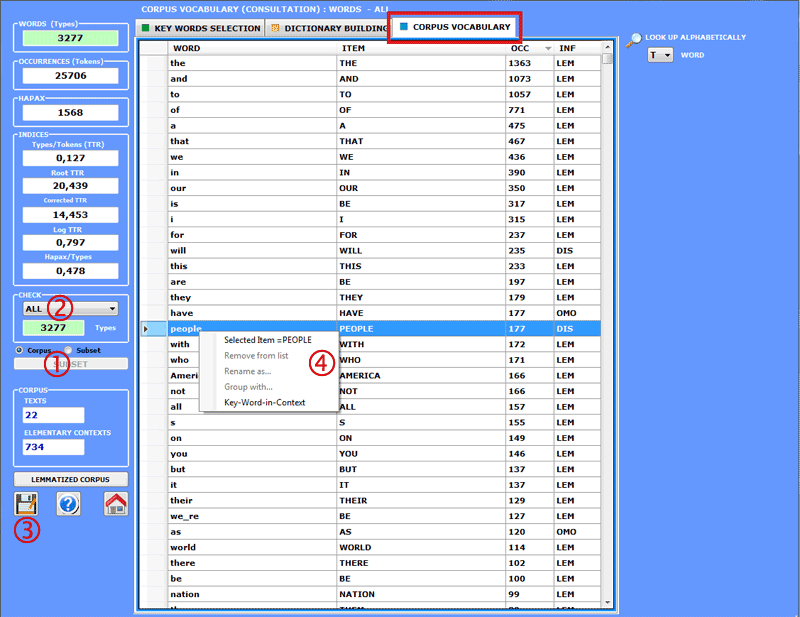
The measures of lexical richness are
five:
Type/Token ratio (i.e. TTR);
Root TTR (Guiraud, 1960), obtained by dividing the number of types
by the square root of the number of the tokens;
Corrected TTR (Carroll, 1964), obtained by dividing the number of
types by the square root of twice the number of the tokens;
Log TTR (Herdan, 1960), obtained by dividing the logarithm of the
number of types by the logarithm of the the number of the
tokens;
Hapax/Types ratio.
N.B.:
- Hapax (i.e. Hapax Legomena) are words which occur only once in a
corpus;
- When analysing a corpus subset, all measures of lexical richness
do not include stop words (e.g. articles
and prepositions).
|


