|
www.tlab.it
Dictionary-Based
Classification
 N.B.: The pictures shown in this section have been obtained by
using a previous version of T-LAB. These pictures look slightly different
in T-LAB 10. In particular,
starting from the 2021 version, a new feature allows one to easily
test any model on labeled data (e.g. data which includes themes
obtained from a previous qualitative analysis) and obtain outputs
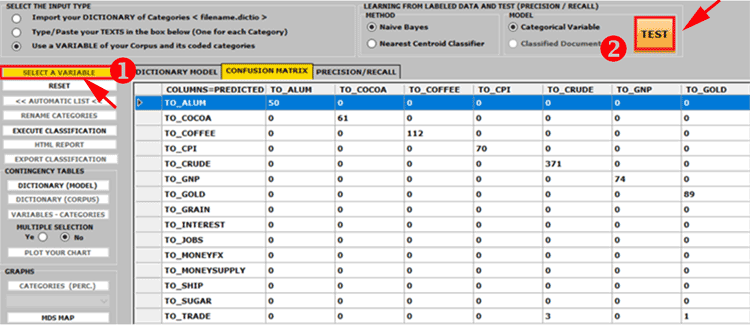
like confusion matrices and precision/recall metrics (see picture
below).
N.B.: The pictures shown in this section have been obtained by
using a previous version of T-LAB. These pictures look slightly different
in T-LAB 10. In particular,
starting from the 2021 version, a new feature allows one to easily
test any model on labeled data (e.g. data which includes themes
obtained from a previous qualitative analysis) and obtain outputs
like confusion matrices and precision/recall metrics (see picture
below).
This T-LAB tool
allows the user to perform an automated
classification of lexical units
(i.e. words and lemmas, including multi-word phrases) or context units
(i.e. sentences, paragraphs and short documents) present in a text
collection (i.e. a corpus) according to a set of categories
costructed by the researcher.
Depending on the type of categories used, such a
classification may be considered a classical content analysis or a lexicon-based sentiment analysis. Moreover, as the analysis
process can create new variables and category dictionaries which
can be exported and re-imported in further analysis projects, such
a tool allows the user to explore the same corpus from varied
perspectives as well as analyse two or more text collections by
using the same models.
Here are some examples of possible
uses of this tool:
- automated coding of open-ended surveys;
- top-down analysis of political speeches;
- sentiment analysis of customer comments;
- verification of psychotherapy processes;
- validation of methods for qualitative content analysis.
Below is a short description of the four main phases of
the analysis process, which are, however, independent one from the
other. In fact, the researcher can also use this tool just for
customizing his dictionaries or for exploring his data set.
A) - PREPROCESSING PHASE
The starting points and the corresponding input types of the pre-processing phase can be
three:
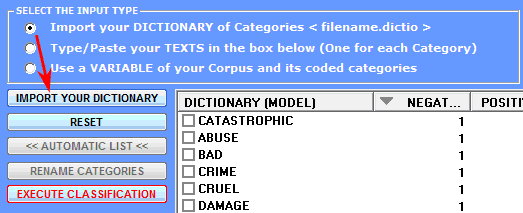
1 - a ready-made dictionary
in the appropriate format is already available (see all related
information in the 'E' section of this document). In this case just
click the 'Import your Dictionary' button (see below);
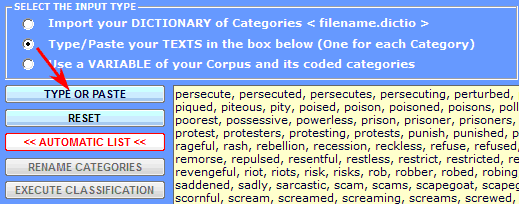
2 - a dictionary has to be distilled from sample texts or word
lists made up by the user. In this case just type or
copy/paste the sample texts into the appropriate box (one sample
for each category, one after the other, max 100,000 characters
each);
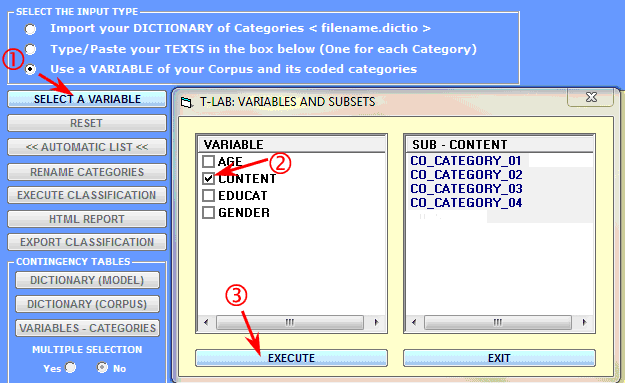
3 - a dictionary has to be distilled from the
categories of a variable resulting
from a previous content analysis. In this case just click the
'Select a Variable' button and make the appropriate choices (see
below).
According to the above three cases, before performing the
classification of selected textual units, T-LAB works in the following ways:
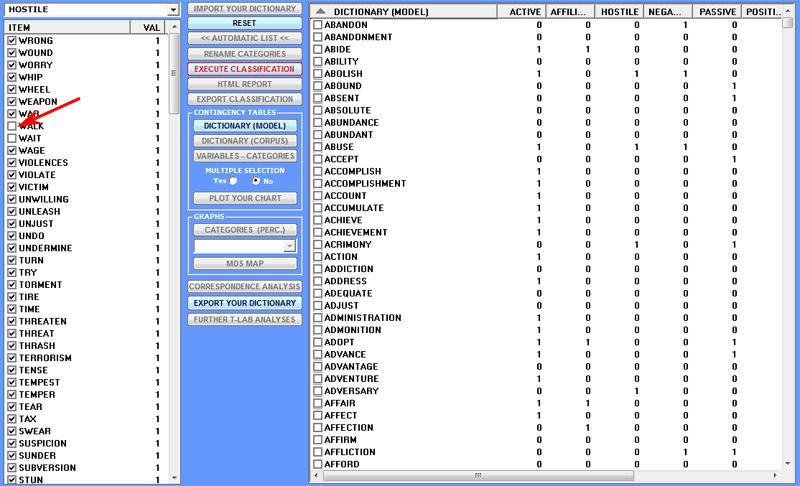
1 - the ready-made dictionary is transformed into a
contingency table. Subsequently the user can explore such a table
in various ways (see the 'C' section of this document); moreover,
by selecting each category, he can remove one or more of the
corresponding items (see the below picture).
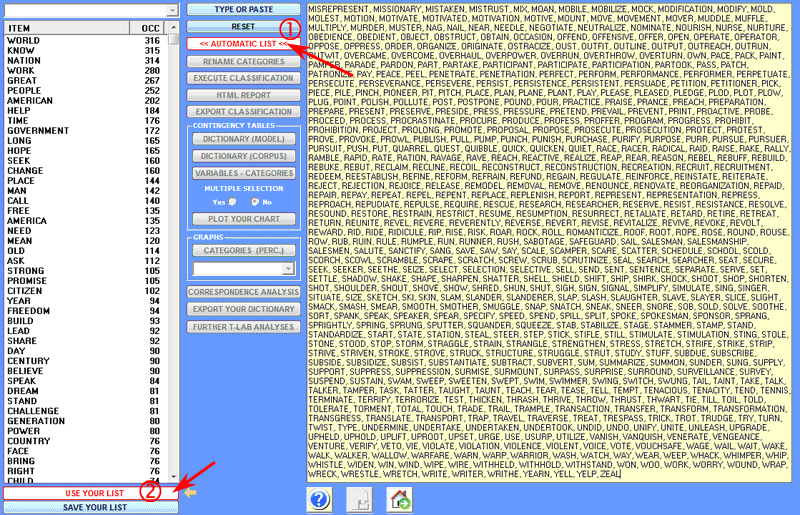
2 - when sample texts are inserted in the appropriate
box, after clicking the 'Automatic List' button (see '1' below),
T-LAB performs a specific kind
of lemmatization which uses only the vocabulary of the selected
corpus (see the list of available items on the left of image
below), then it transforms each text into a word list the items of
which can be selected and deselected. Subsequently, in order to
validate each word list (i.e. each category of your dictionary),
just click the 'Use Your List' button (see '2' below). All the
above operations must be repeated for each category of the
dictionary, then the user can perform all operations described in
the 'C' section of this document.
3 - when a variable resulting from a previous content
analysis is selected, T-LAB
makes available the corresponding term-category contingency table
and the user can perform all operations of 'Data Exploration' (see
the 'C' section of this document).
B) - CLASSIFICATION PROCESS
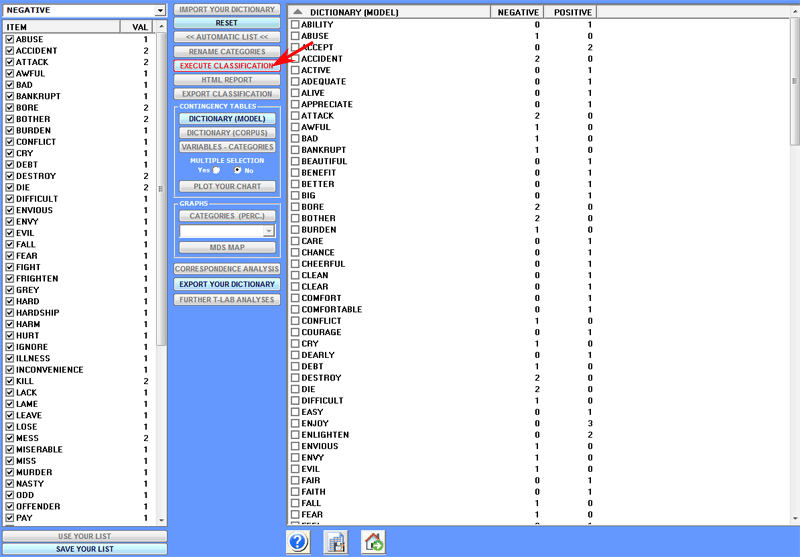
After clicking the 'Execute Classification' button (see
the above picture), depending on the type of corpus under analysis,
the user can make the following choices:

At this stage, if the user decides to classify words, no further choices are available;
in fact, in such a case, the occurrences of each word (i.e. the
word tokens) are simply counted as occurrences of the corresponding
category. For example, if a category of our dictionary is
'religion' and this includes words like 'faith' and 'prayer', when
analysing a document which contains the above two words,
T-LAB simply groups their
occurrences (e.g. 2 occurrences of 'faith' and 3 occurrences of
'prayer' = 5 occurrences of 'religion').
Differently, when the user decides to classify context units (i.e. 'elementary contexts'
like sentences and paragraphs or 'documents'), T-LAB considers both the dictionary categories
and the context units to be classified as co-occurrence profiles
(i.e. term vectors) and then calculates their similarity measures.
To this purpose, the co-occurrence profiles can be filtered by a
'T-LAB list' (i.e. all key-words which occurrence values are
greater than or equal to the minimum threshold of 4) or a by
'user's list' (e.g. all key-words resulting from a customized
settings) which, however, can sometimes be equal. Moreover in such
cases T-LAB allows the user to
exclude from the analysis any context unit that doesn't contain a
minimum number of key-words included in the list which is being
used (see above the 'co-occurrences within context units'
parameter).
In detail, when classifying context units,
T-LAB performs the following
steps:
a) normalization of the 'seed vectors' corresponding to
the 'k' categories (i.e. column profiles) of dictionary used;
b) normalizations of term vectors corresponding to the context
units analysed;
c) computation of the Cosine similarity and Euclidean distance
between each 'i' context unit and each 'k' seed vector of the
dictionary used;
d) assignment of each 'i' context unit to the 'k' class or category
for which the corresponding seed is the closest. (N.B.: In all
cases there must be a correspondence between the maximum Cosine
similarity and the minimum Euclidean distance of each 'context
unit'/'category' pair, otherwise T-LAB considers the 'i' context
unit as 'unclassified').
In other words, in the above case T-LAB uses a sort of K-means clustering where
the 'k' centroids have a priori patterns and they are not updated
during the analysis process.
Being a top-down classification, in such a case the quality of the
analysis results will depend on two main factors:
1 - the 'relevance' of the dictionary used for the analysed
corpus;
2 - the 'discriminant' capacity of the categories used.
In fact, if the optimum of the above characteristics is reached,
both the 'precision' and the 'recall' parameters (see
http://en.wikipedia.org/wiki/Precision_and_recall ) have values
between 80% and 95%.
Please note that, at the moment, T-LAB doesn't take into account negations. So,
when doing sentiment analysis, a sentence like 'Do not hate your
enemy' can be classified as 'negative'. Advanced users can manage
this issue during the corpus importation (see the use of stop-word
and multiword lists). For example, the word phrase 'do not hate'
can be transformed into 'do_not_hate' and consequently included in
the 'positive' category'.
C) - DATA EXPLORATION
Any data exploration activity uses contingency tables where both the dictionaries and
the results of the classification process can be
represented.
Depending on the textual units classified - respectively
(a) 'words', (b) 'elementary contexts' or (c) 'documents' - the
cells of such tables contain the following values:
a) number of occurrences of each word (i.e. the 'i' row) which,
within the analysed corpus or a subset of it, has been assigned to
a predefined category (i.e. the 'j' column). So, in such a case,
words belonging to two or more predefined categories have the same
values repeated in the corresponding columns;
b) number of elementary contexts, which contain the word in the 'i'
row, assigned to a given category (i.e. the 'j' column);
c) number of occurrences of each word (i.e. the 'i' row) within the
documents assigned to each category (i.e. the 'j' column).
By clicking their respective check-boxes, it is possible
to check the occurrence contexts of each listed word (N.B.: this
option is available only for the 'b' case above, for which you
click the appropriate cell) as well as to create customized charts
concerning each item of the tables (N.B.: In the examples below
some categories of the Harvard IV-4 dictionary have been applied to
the analysis of inaugural addresses of US presidents).
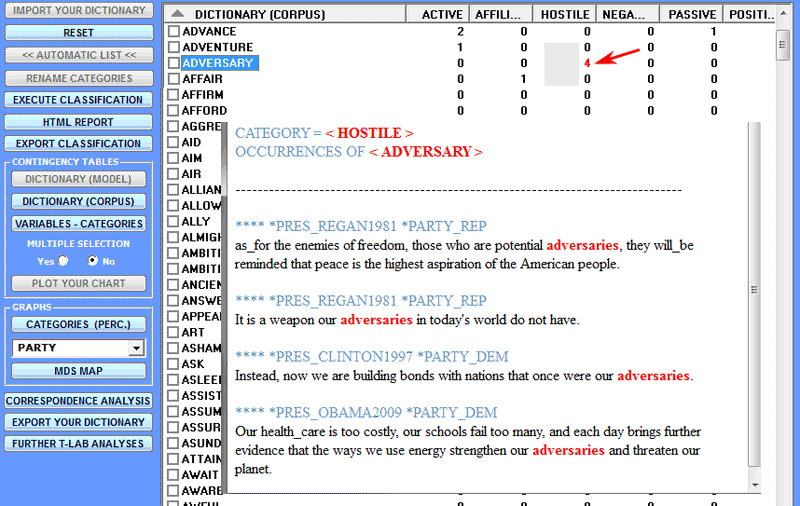
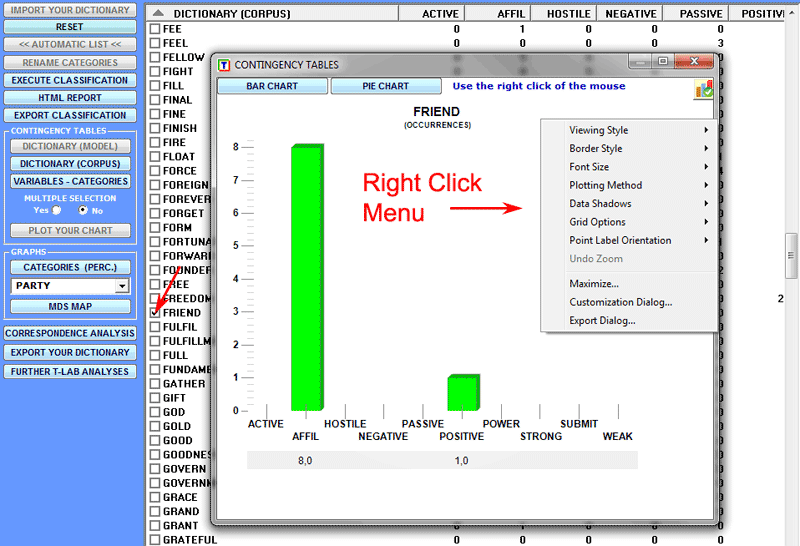
In order to plot charts with multiple data series, just
choose 'Multiple Selection' ('Yes' option), select up to 20 items
and click the 'Plot your chart' button (see below).
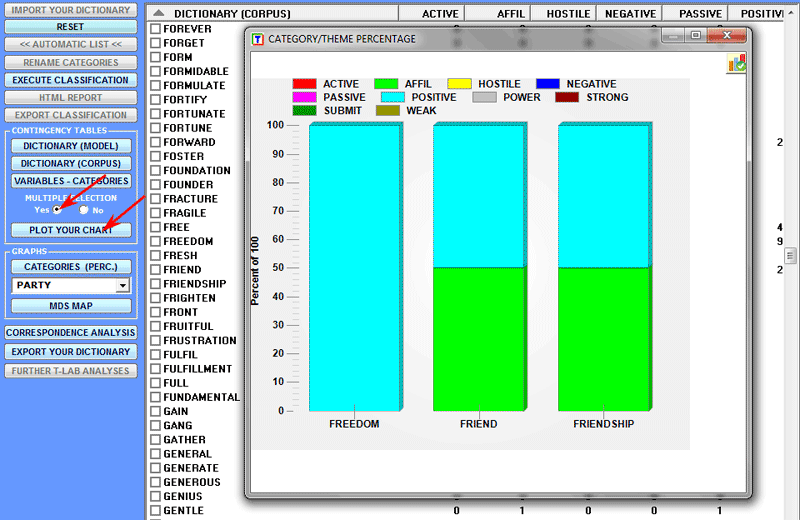
The above two options are also available for tables with
variable values.
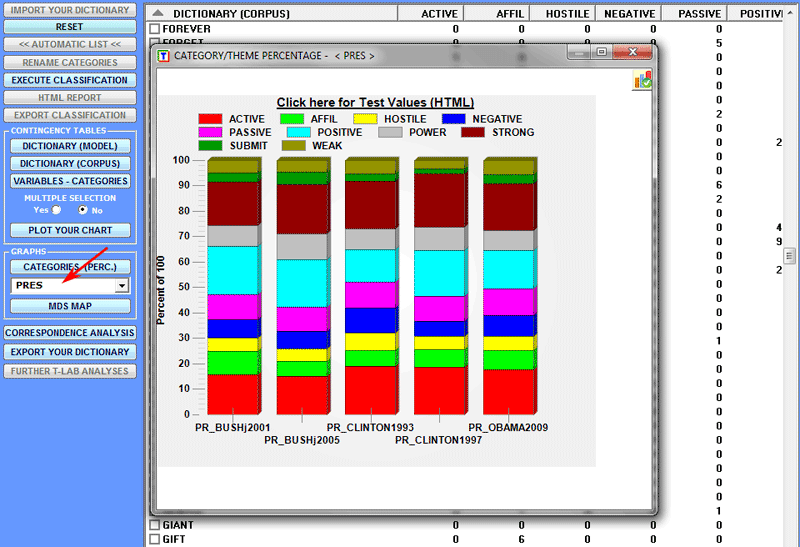
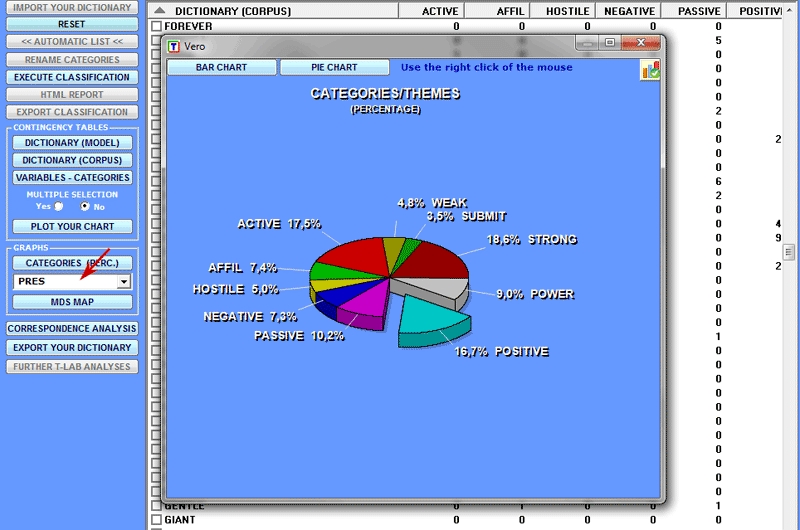
The percentage of categories can be appreciated in various ways
(see below)
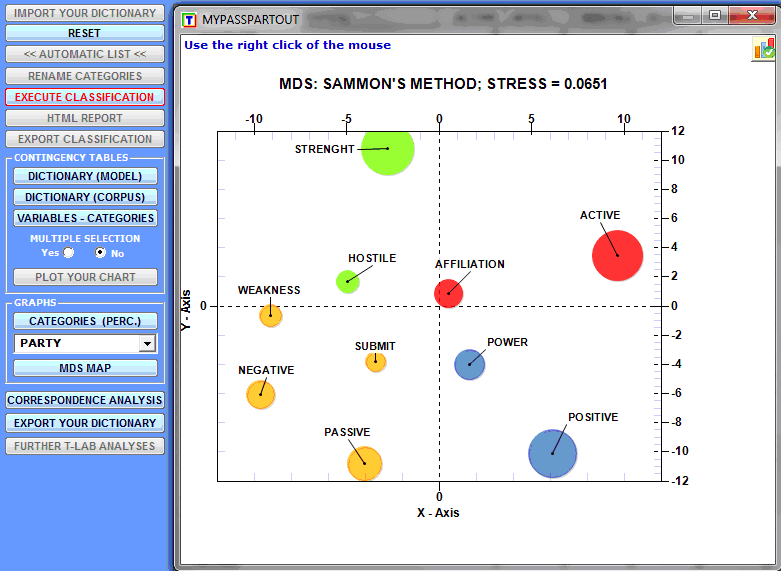
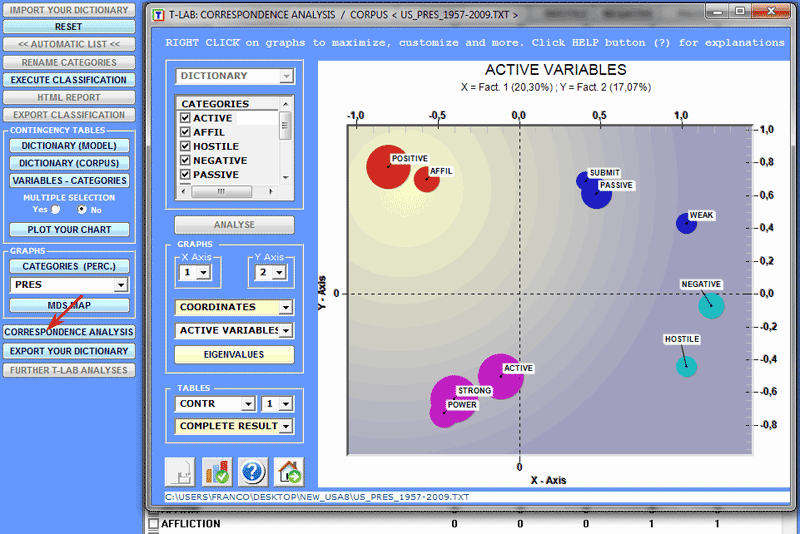
It is also possible to explore the data structure by
using the 'MDS' or the 'Correspondence Analysis' tool (see
below).
Only in the case where context units have been classified
it is possible to obtain and export two more outputs; moreover, in
such a case, it is possible to save the analysis results in a new
variable and pursue the data exploration with other T-LAB tools.
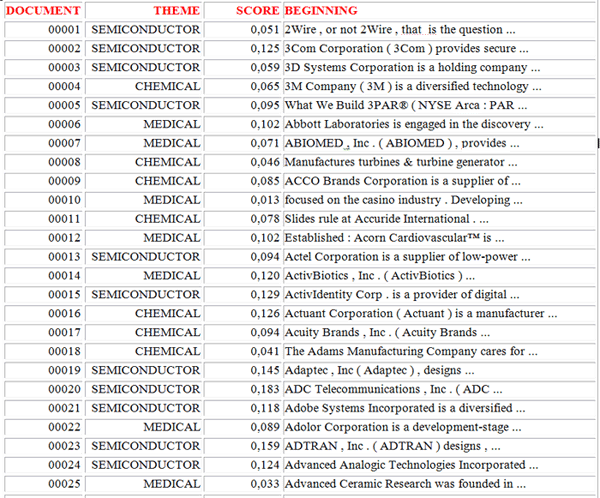
For example, by clicking the 'HTML Report' button it is possible to
visualize some results of the classification process where the
'elementary contexts' or the 'documents' are assigned to their
respective category with a Cosine similarity score (see the images
below concerning a corpus of documents containing short
descriptions of companies).
 . .
Similar data can be exported in .XLS files (see below)
with all the information regarding the elementary contexts
('Context_Classification.xls') or the documents
('Document_Classification.xls') which have been correctly
classified;
(1) - Context_Classification.xls
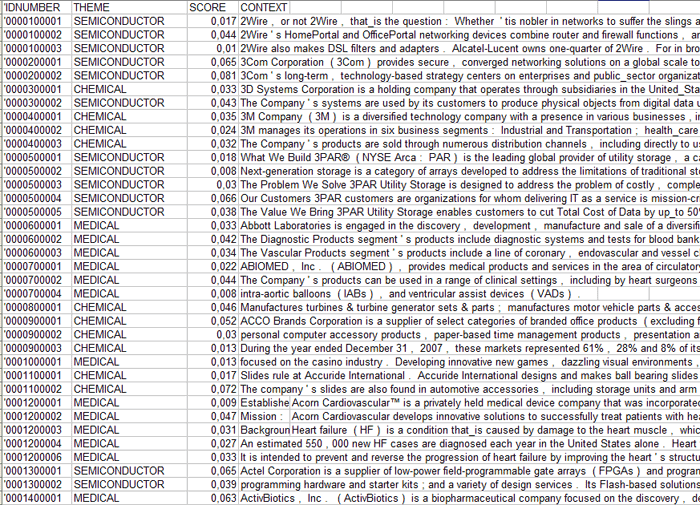
(2) - Document_Classification.xls
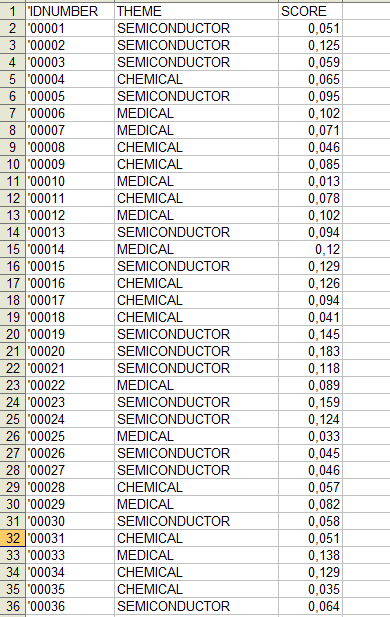
D) - FURTHER ANALYSIS STEPS
When the classification process is over, two further
options are available:
- 'Export Your Dictionary', which creates a ready-made
dictionary to be imported by other T-LAB tools for Thematic Analysis;
- 'Further T-LAB Analyses', which, depending on the structure of
the corpus analysed, on the kind of classification performed and on
the number of categories used, makes a new variable for further
T-LAB tools available (see
below).
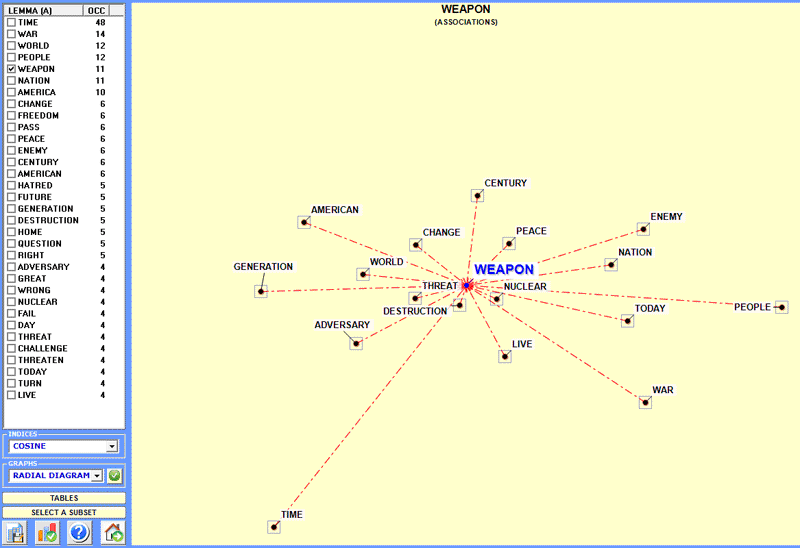
Below is an example obtained by analysing a 'subset' of classified
contexts by means of the Word
Associations tool (see the T-LAB main menu).
E) - INPUT AND OUTUT FORMAT OF T-LAB DICTIONARIES
Here is all the information about the format
of dictionaries which can be imported by this
T-LAB tool:
- they are plain text files with a '.dictio' extension (e.g.
Mycategories.dictio);
- all dictionaries created by T-LAB thematic tools, including those
created by the Dictionary-Based Classification, are ready to be
imported and no further user intervention is required;
- other dictionaries, either 'standard' or customized must be saved
by following the guidelines below:
1- they can include up to 100,000 records (i.e. lines),
each consisting of strings separated by semicolons (e.g.
economic;loan);
2- for each line, the first string must be a 'category', the second
a 'word' (or lemma), the third - if present - must be a positive
real number (i.e. a integer) from '1' to '999' which represents the
'weight' of each word within the corresponding category;
3- the maximum length of a string (word, lemma or category) is 50
characters: neither blank spaces no apostrophes can be
included;
4- when multi-word phrases are included, blank spaces must be
replaced by the underscore ('_') character (e.g.
Federal_Government);
5- the number of categories used can vary from 2 (minimum) to 50
(maximum). When the number of categories is higher than 50 it is
advisable to use a different format and import the dictionary by
the Dictionary Building tool (see the
'Lexical Tools' sub-menu of T-LAB). In such a case there must be
univocal correspondence between each single word and the
corresponding category.
The following are two excerpts from T-LAB .dictio files, with two
or three strings per line respectively:
a) case with two strings (i.e. categories and words
only)
…
negative;catastrophic
negative;bad
…
positive;outstanding
positive;supportive
…
b) case with three strings (i.e. categories, words and
numbers)
…
negative;catastrophic;10
negative;bad;7
…
positive;outstanding;9
positive;supportive;8
|


