|
www.tlab.it
Concordances
This T-LAB tool allows
us to check the occurrence contexts of each lexical
unit.
The KWIC (key-word in context)
search can be carried out using two criteria: by word and by lemma
(see option '2' below), both within the entire corpus or within a subset of it (see option '1' below).
It is also possible to define the
occurrence (min. and max.) range (see option '3' below).
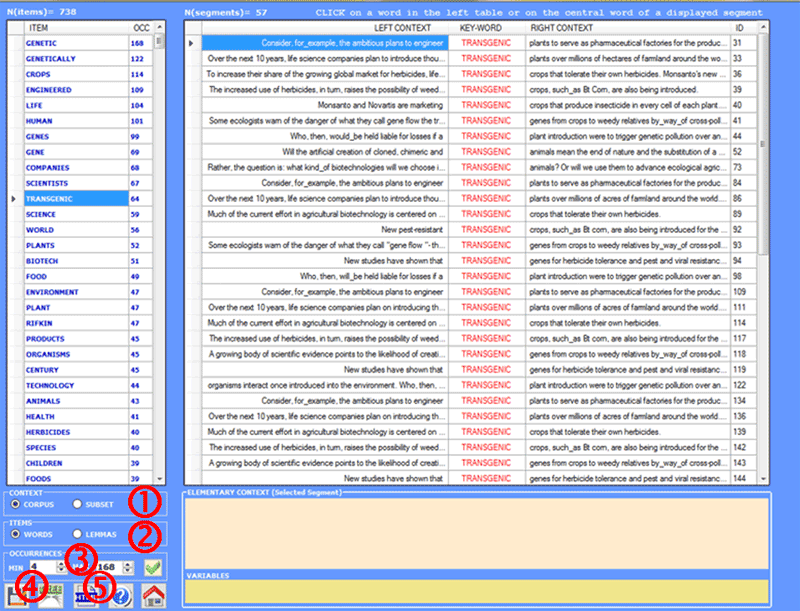
With a simple click on the
corresponding column, you can, for each corpus lexical unit, verify
what its occurrence contexts (the elementary
contexts) are; furthermore, it is possible to create a dynamic
Word Tree (see above option '4') or to
save a HTML file with all the selected contexts (see option '5'
above).
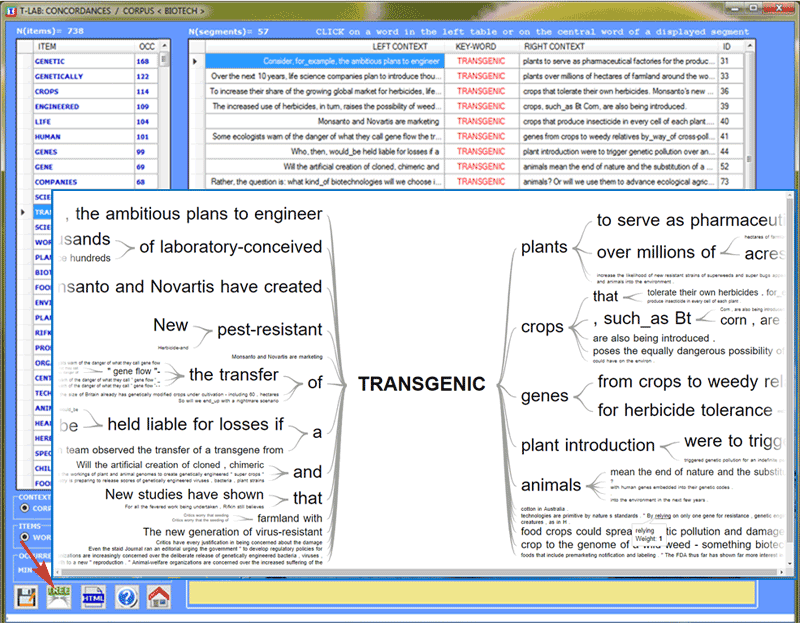

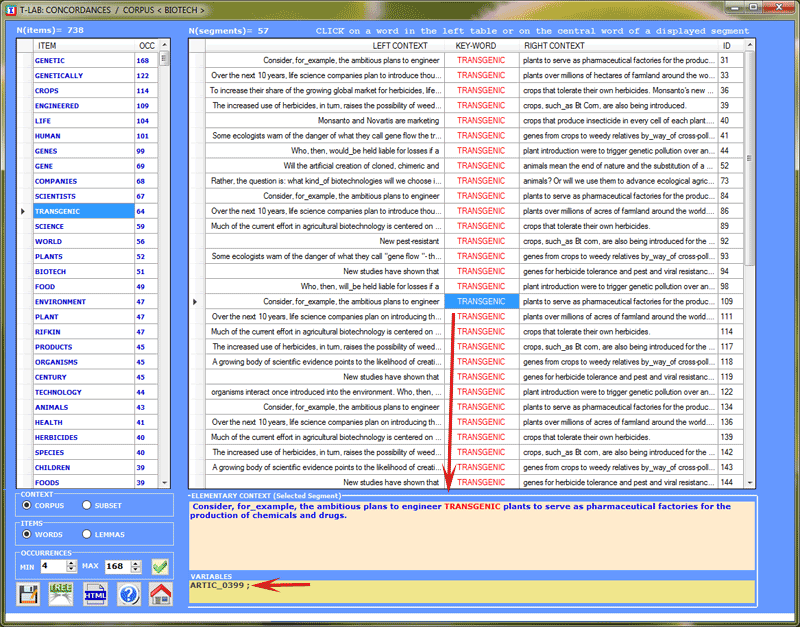
Moreover, by clicking the centre of displayed
segment it is possible to visualise all its content and to check
the variable categories used in its coding lines (see
below).
|


