|
TF-IDF
This measure, proposed by G. Salton (1989), allows
us to evaluate the weight of a term (lexical unit) within a
document (context unit).
Its formula is the following:
w i,j =
tf i,j x idf i (Term Frequency x Inverse
Document Frequency)
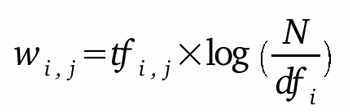
Where:
tf i,j = number
of occurrences of i (term) in j
(document)
df i = number of documents
containing i
N = total number of
documents
Term Frequency (tf
i,j ) value can be normalized as follows:
tf i,j
= tf i,j / Max
(f i,j )
where Max (f i,j ) is the
maximum frequency of i(any term) in the j
(document).
|


