|
www.tlab.it
Key Contexts of Thematic
Words
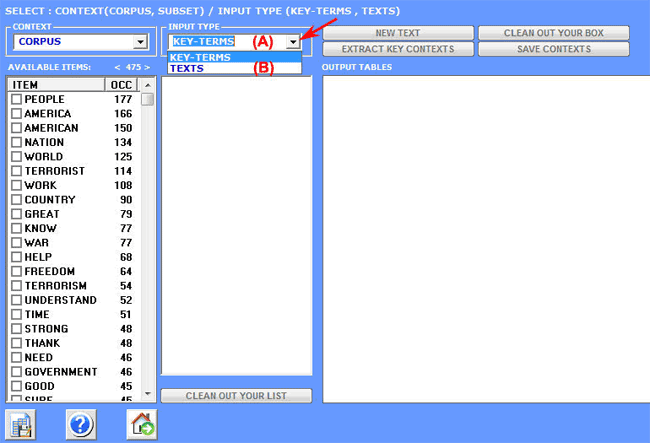
According to the type of
input, this T-LAB can be used
for two different purposes:
A) to extract lists of meaningful context units (i.e. elementary
contexts or short documents) which allow us to deepen the thematic
value of specific key terms;
B) to extract the context units which are the most similar to
sample texts chosen by the
user.
Here are some explanations
for the two above cases.
Case (A)
Unlike Concordances, which allows the extraction of
all elementary contexts in which the selected key words are just
present (occurrences), and unlike Word Associations,
which allows the extraction of all elementary contexts in which the
selected key words are in matching pairs (co-occurrences), this
tool allow us to extract the elementary contexts in which each
selected key word is associated with other words (multiple
co-occurrences) defining its thematic field.
It works in the following way:
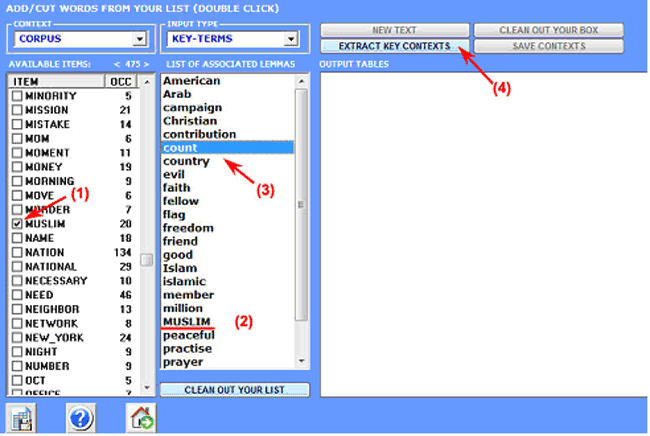
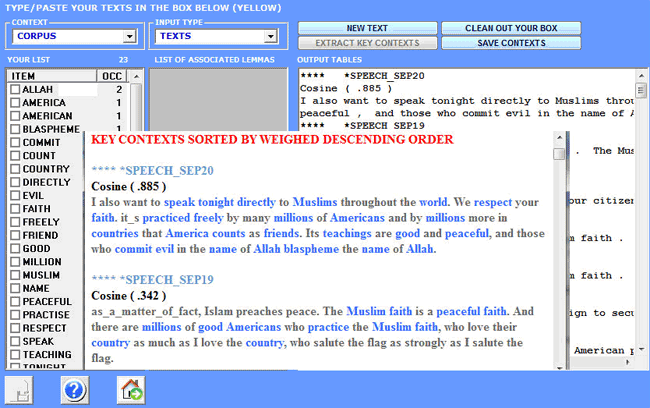
1- the user chooses a
thematic word "X" (see "Muslim" below);
2- T-LAB proposes a list of words (max. 50)
whose co-occurrence values with "X" are the most
significant;
3- the user
can remove irrelevant items from the list provided (just double
click each item);
4- after clicking 'Extract Key Contexts'
T-LAB assumes that the user
list is a query vector and computes its association indexes (i.e. cosine coefficients)
with all the elementary contexts of the corpus or of the selected
corpus subset.
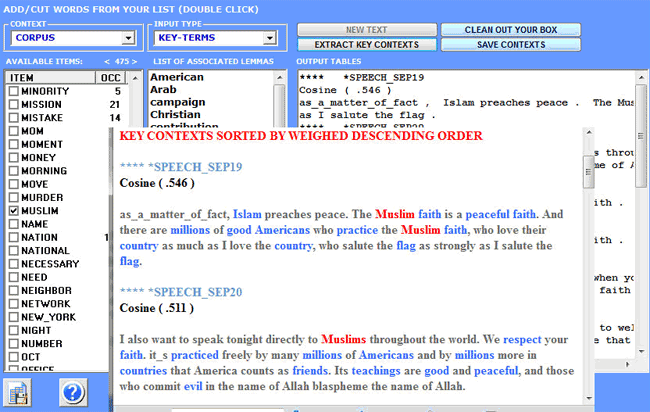
The output provided, both in HTML and TXT format, contain a
list of the most significant key-contexts of "X", listed according
to the descending order of their association indexes.
The 1-4 steps can be reiterated for "n" thematic words.
Case (B)
It works in the following way:
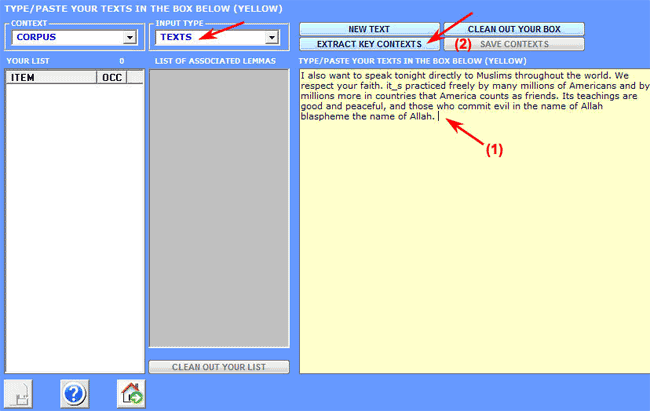
1- the user copy/paste a
text (Max 5,000 characters) in the appropriate box;
2- after clicking the 'extract key
contexts' button, T-LAB
transforms the input text into a query vector and computes its
association indexes (i.e. cosine
coefficients) with all the elementary contexts of the corpus or of
the selected corpus subset.
The output provided, both in HTML and TXT format, contain a
list key-contexts which are the most similar to the input text.
N.B.: In such a case the similarity measure doesn't take into
account multi-words the strings of which, either with or without
the underscore ('_') character, do not correspond to the analysed
text.
The above 1-2 steps can be reiterated for "n" sample texts.
.
|


