|
www.tlab.it
Specificity
Analysis
 N.B.: The pictures shown in this section have been obtained by
using a previous version of T-LAB. These pictures look slightly different
in T-LAB 10. In particular,
starting from the 2021 version, a quick access gallery of pictures
which works as an additional menu allows one to switch between
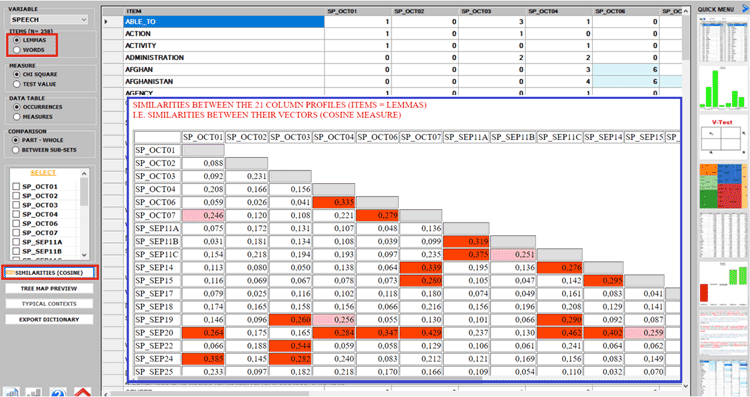
various outputs with a single click. Moreover the user is enabled
to easily evaluate similarities (i.e. Cosine) and differences (i.e.
Inter-Textual Distance) between corpus subsets (from 2 to 150), and
so also to detect duplicate and near-duplicate documents (see
pictures below).
N.B.: The pictures shown in this section have been obtained by
using a previous version of T-LAB. These pictures look slightly different
in T-LAB 10. In particular,
starting from the 2021 version, a quick access gallery of pictures
which works as an additional menu allows one to switch between
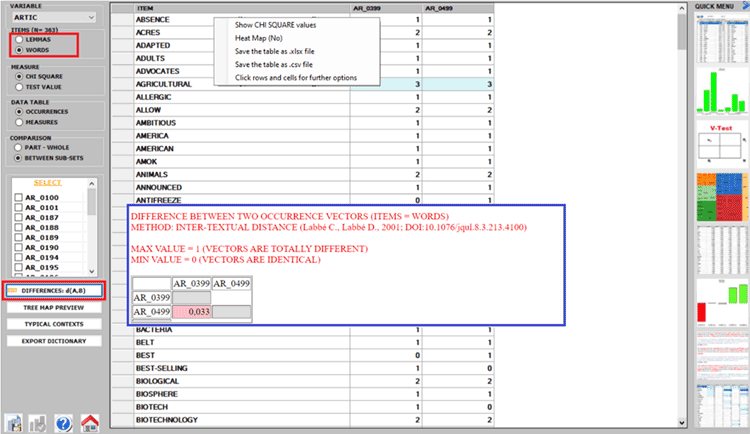
various outputs with a single click. Moreover the user is enabled
to easily evaluate similarities (i.e. Cosine) and differences (i.e.
Inter-Textual Distance) between corpus subsets (from 2 to 150), and
so also to detect duplicate and near-duplicate documents (see
pictures below).
This T-LAB tool
enables us to check which lexical units (words, lemmas or
categories) are typical or exclusive in a text or a corpus subset defined by a categorical variable,
as well as to check the 'typical contexts' of each analysed subset
(e.g. the 'typical' sentences used by any specific political
leader).
In detail:
The typical lexical units,
defined for over-using or under-using, are detected by means of the
chi-square or the test
value computation.
The typical elementary
contexts are detected by computing and summing the
normalized TF-IDF values assigned to the
words which each sentence or paragraph consists of.
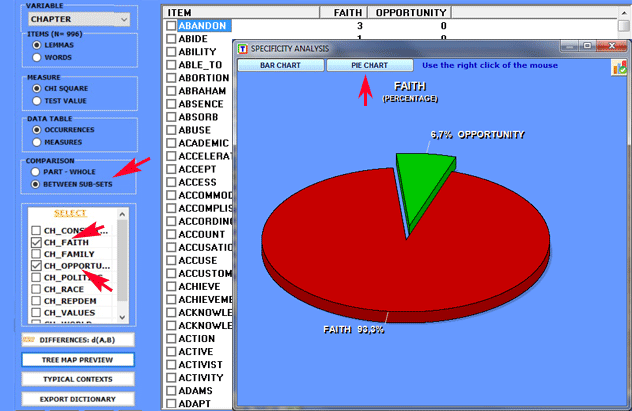
Specificity Analysis allows us to carry out two types of
comparisons:
1- between a part (e.g. the
subset "A") and the whole (e.g. the
corpus under analysis, "B");
2- between pairs of corpus
subsets ("A" and "B").
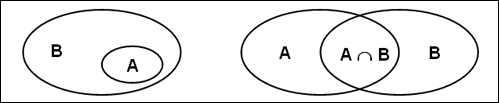
In either instance Specificities involving both the
intersection (tipical words) and the
differences (exclusive words) can be
analysed.
The computation modalities are shown in the corresponding
glossary entry.
The considered lexical units can be all (automatic
settings) or only those selected by the user (customized settings).
The four types of possible comparisons are as
follows:
1.1 - part/whole: "typical" lexical units
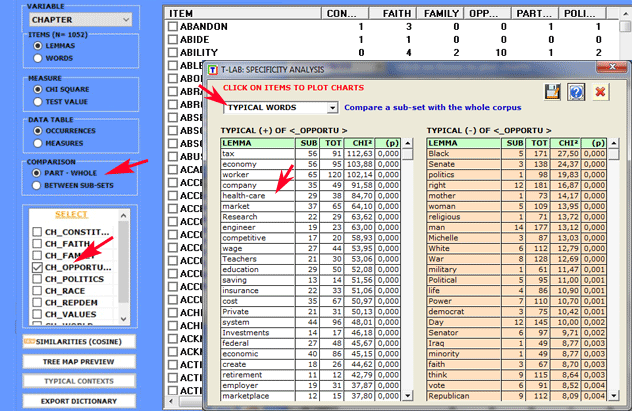
Table reading keys are as
follows:
- LEMMA = specific lexical units (over/under used);
- SUB = occurrences of each LEMMA in the subset;
- TOT = occurrences of each LEMMA in the corpus or in the two
compared subsets (see 2.1 below);
- CHI2 = CHI square value (or VTEST = Test Value);
- (p) = probability associated with the chi square value
(def=1).
By clicking on the listed items it is possible to create
various charts (see below).
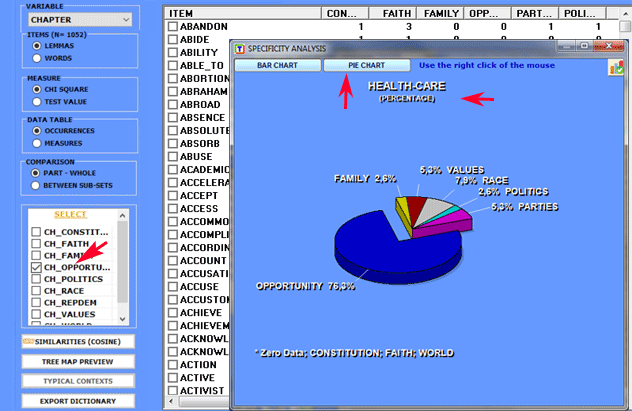
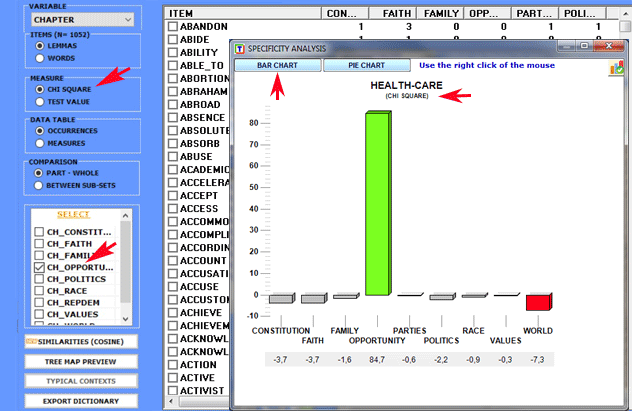
1.2 - part/whole: "exclusive" lexical units
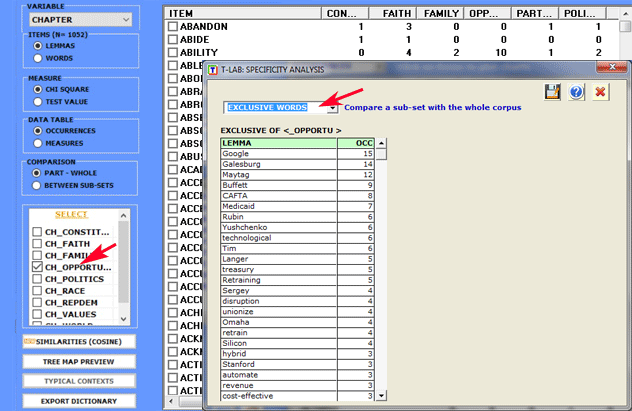
2.1 - subset/subset: "typical" lexical units
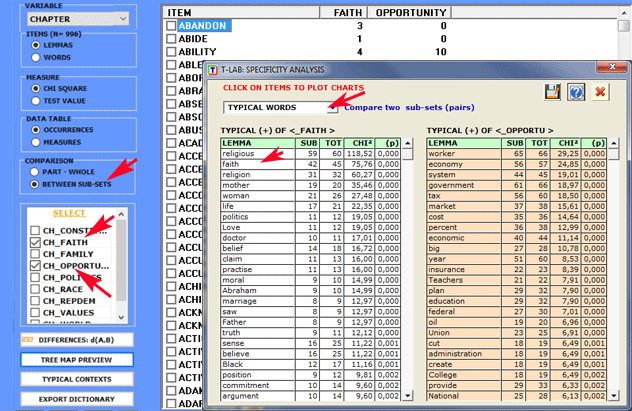
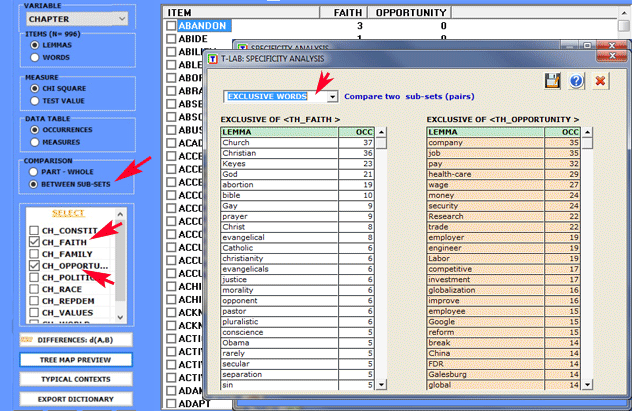
2.2- subset/subset: "exclusive" lexical units
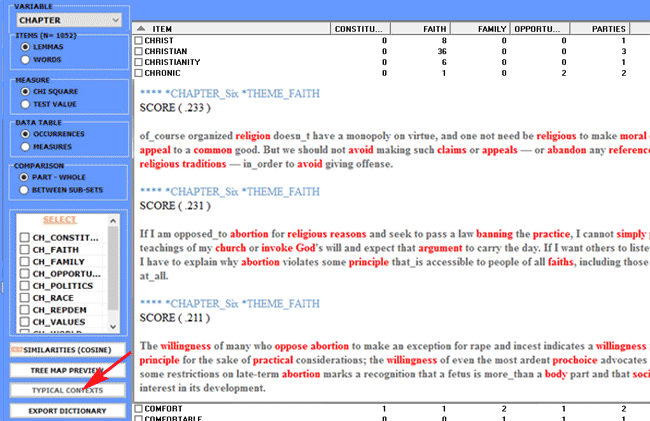
For each targeted subset it is also possible to check its
'typical' elementary contexts, the specificity of which is a result of the
computation of normalized TF-IDF values.
More specifically, the 'score' assigned to each elementary context
(see the picture below) results from the sum of TF-IDF values
assigned to the words which it consists of.
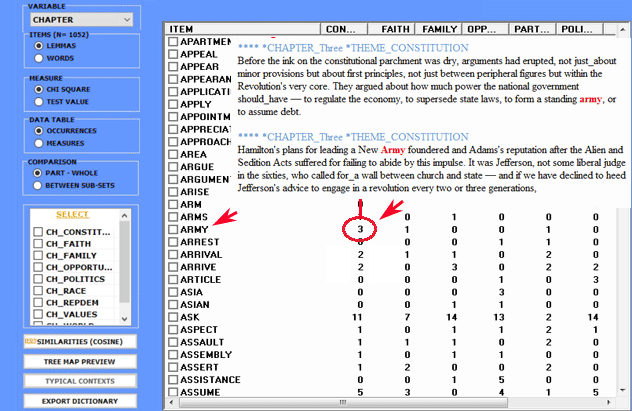
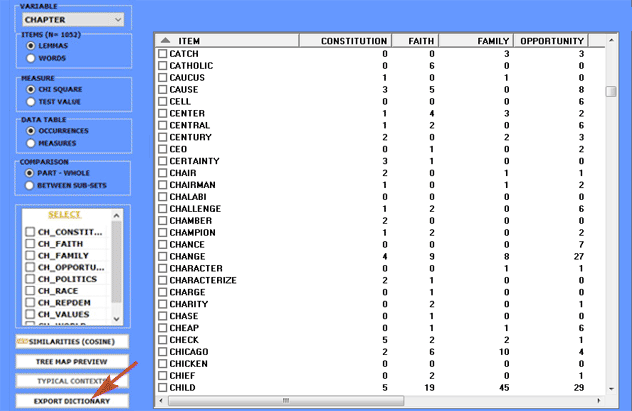
All contingency tables can be easily exported and allow us to
create various charts.
Moreover, by clicking on specific cells of the table (see below),
it is possible to create a HTML file including all elementary
contexts where the word in row is present in the corresponding
subset.
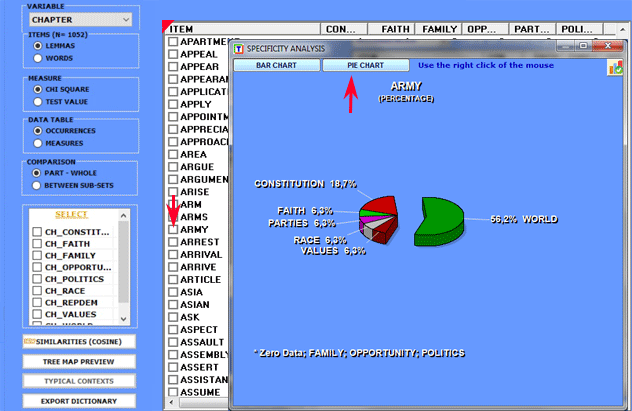
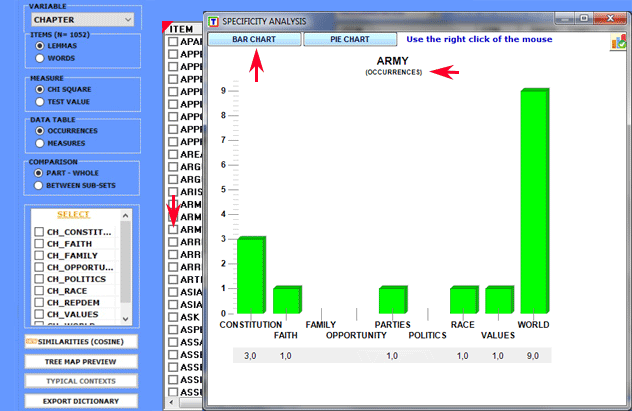
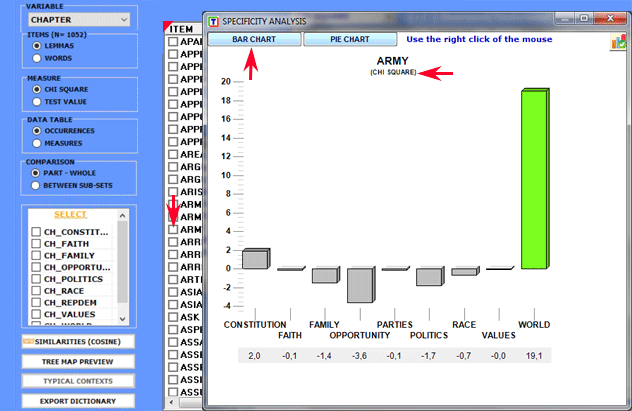
Eventually, by clicking the appropriate button (see below), a
dictionary file with the .dictio
extension is created which is ready to be imported by any
T-LAB tool for thematic analysis. Such a dictionary includes all
typical words of the selected categorical variable.
|


