|
www.tlab.it
Co-Word Analysis and Concept
Mapping
 N.B.: The pictures shown in this section have been obtained
by using a previous version of T-LAB. These pictures look slightly different
in T-LAB 10. Also: a) when the
'automatic selection of key terms' is selected, different colours
are used for different groups of items in the MDS map; b) the visualization technique called
t-SNE (t-Distributed Stochastic Neighbor Embedding) has been added;
c) there is a new button (Graph Maker)
which allows the user to create several dynamic charts in HTML
format; d) by right clicking on the
keyword tables, additional options become available; e) a quick
access gallery of pictures which works as an additional menu allows
one to switch between various outputs with a single click. N.B.: The pictures shown in this section have been obtained
by using a previous version of T-LAB. These pictures look slightly different
in T-LAB 10. Also: a) when the
'automatic selection of key terms' is selected, different colours
are used for different groups of items in the MDS map; b) the visualization technique called
t-SNE (t-Distributed Stochastic Neighbor Embedding) has been added;
c) there is a new button (Graph Maker)
which allows the user to create several dynamic charts in HTML
format; d) by right clicking on the
keyword tables, additional options become available; e) a quick
access gallery of pictures which works as an additional menu allows
one to switch between various outputs with a single click.
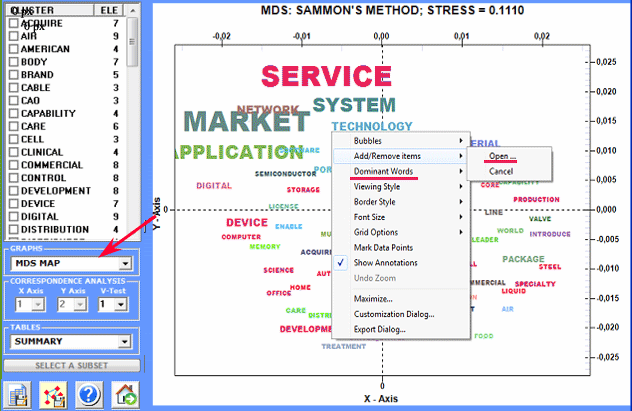
Some of these new features are highlighted in the below
image.
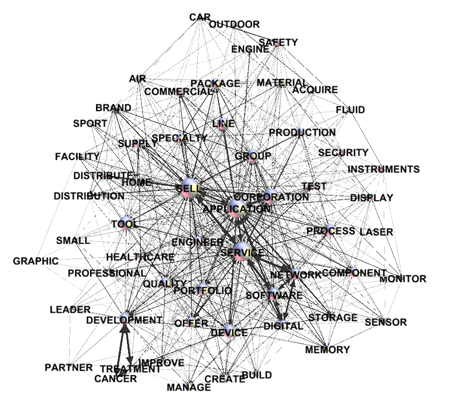
This T-LAB tool allows us to find and map two kinds
of relationships concerning word co-occurrences:
A - between single key-words (lemmas or categories), if their
number does not exceed 500 elements (min 10);
B - between/within little clusters (i.e. Thematic
Nuclei), if the number of key-words
selected exceeds 100 elements (max 3,000).
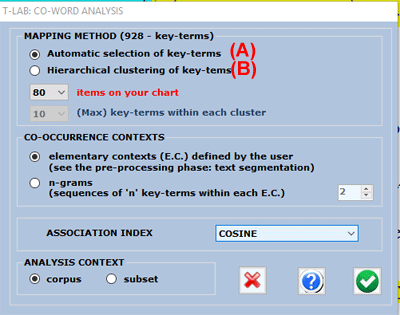
The user may choose which association index to be used and, for option B
only, he may also choose both the maximum number of clusters to be
obtained (from 50 to 100) and the maximum number of key-terms
within each cluster.
The computation process includes the following
steps:
1-
building a co-occurrence matrix (word x word);
2- computing the selected association indexes (Cosine, Dice,
Jaccard, Equivalence, Inclusion, Mutual Information);
3-
hierarchical clustering of the
dissimilarity matrix;
4- building a second dissimilarity matrix (cluster x
cluster);
5- graphic representation by multidimensional scaling
and correspondence
analysis.
N.B.:
- in "A" cases ((see the below image), the user can review the
key-term selection and T-LAB doesn't carry out steps 3 an
4;
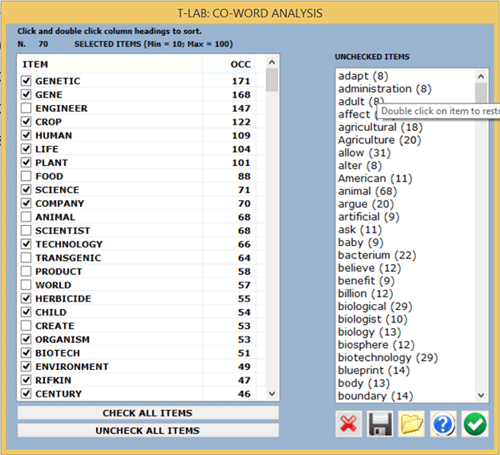
- the quality of results depends on a thorough selection of key-words;
- as the multiwords
unclassified by T-LAB are specific cases of co-occurrence and the
"B" option treats them like little clusters (e.g. "Twin" +
"Towers"), the user is advised to resolve these cases during the
pre-processing phase. Anyway, without
repeating the corpus importation, it is possible to make changes by
means of the Dictionary Building
function (e.g. by assigning the label "Twin_Towers" to the two
different items "Twin" and "Towers");
- by clicking on the appropriate buttons all data
tables can be checked (see the picture below).
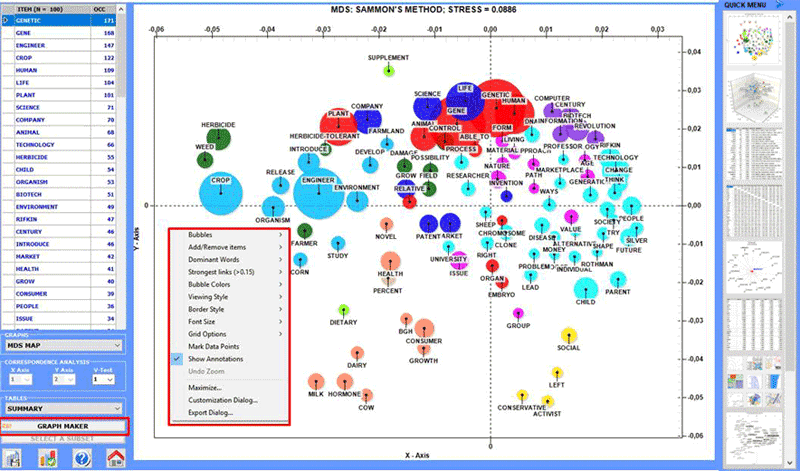
When the automatic analysis is over, four kinds of
charts are available (see below) and each of them can be customized
by using the appropriate dialog box (just right click on the
chart).
1 - MDS Map
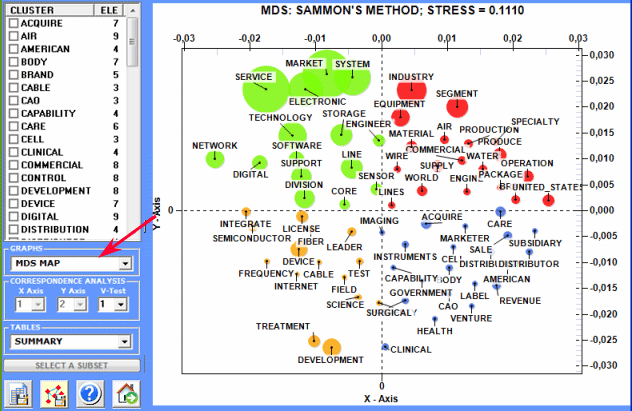
2 - Factorial Analysis of Correspondences

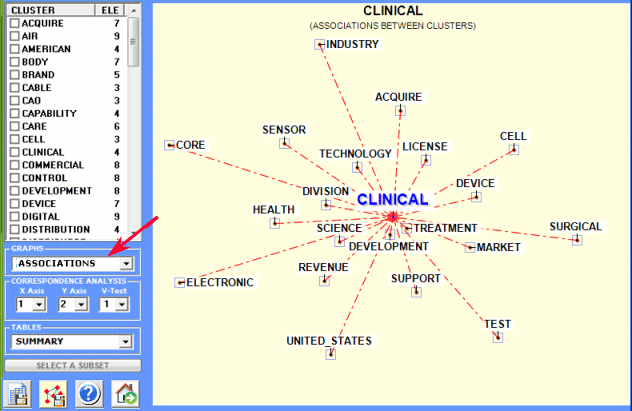
3 - Association Diagram
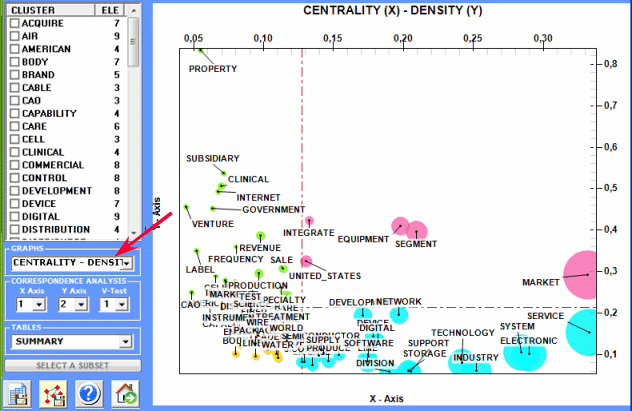
4 - Diagram of Centrality-Density measures (after a
cluster analysis only)
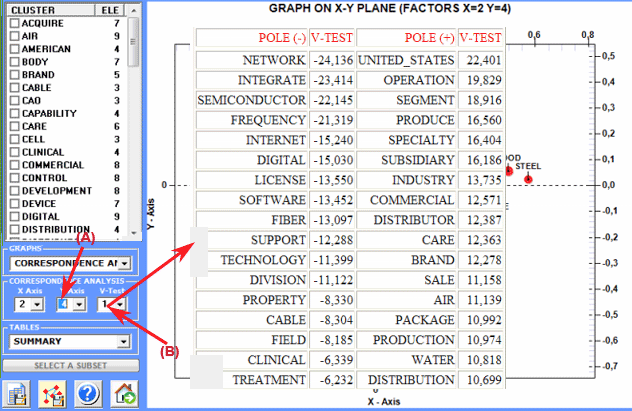
In particular, the results obtained by Correspondence Analysis can be mapped using the
coordinates of the first ten axes (see "A" below).
As T-LAB allows us to verify the Test Values of each factor (see "B" below), this
kind of output can be useful for an accurate interpretation of the
relationships between cluster and/or key-words.
The charts can be explored and customized in the
following ways:
|
ACTION
|
RESULT
|
|
click on a table item or on a chart
point
|
diagram of corresponding associations
|
|
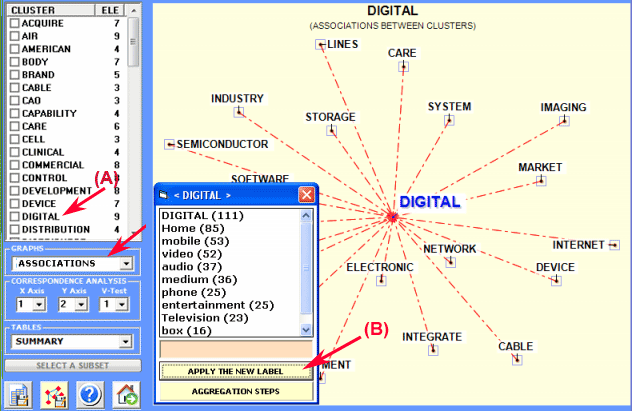
click on a label of "CLUSTER"column
(see "A" below)
|
list of cluster elements
|
|
click on "apply the new label" (see "B"
below)
|
new label assigned to the cluster
|
|
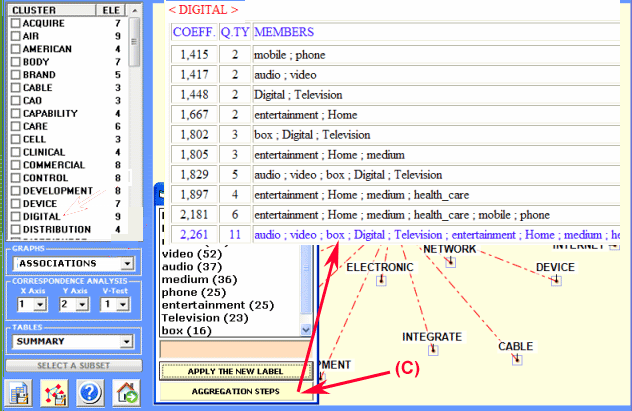
click on "aggregation steps" (see "C"
below)
|
word aggregation within the cluster
|
|
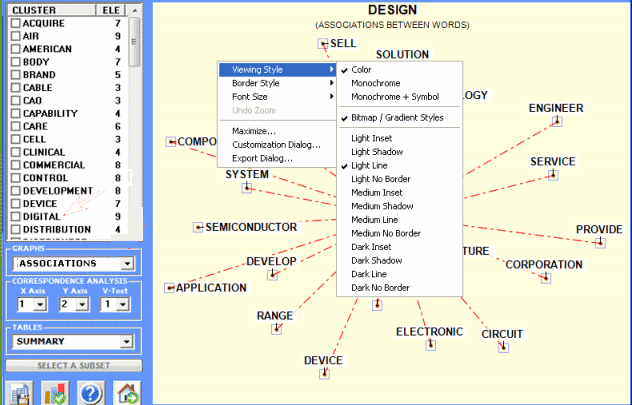
right click on the chart
|
open the dialog menu
|
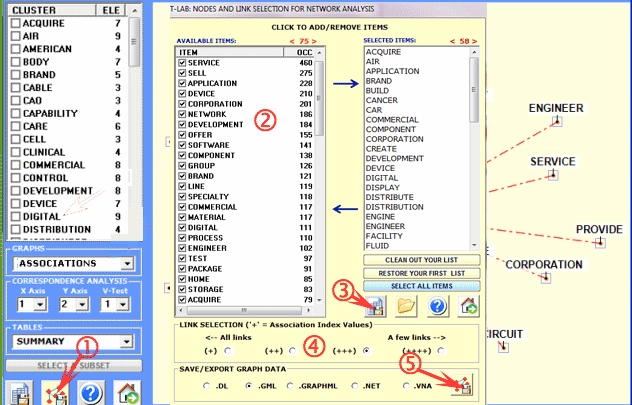
A further option allows us to select the items
(i.e. the 'nodes') for Network
Analysis (see the image below, step 1 and 2), to export the
corresponding adjacency matrix (step 3), select the links on the
basis of their range of probability value (step 4) and export
different types of files (step 5) which can be edited by software
such as Gephi, Pajek, Ucinet, yEd and others.
N.B.: In T-LAB 10 the
following window has been replaced by the Graph Maker tool.
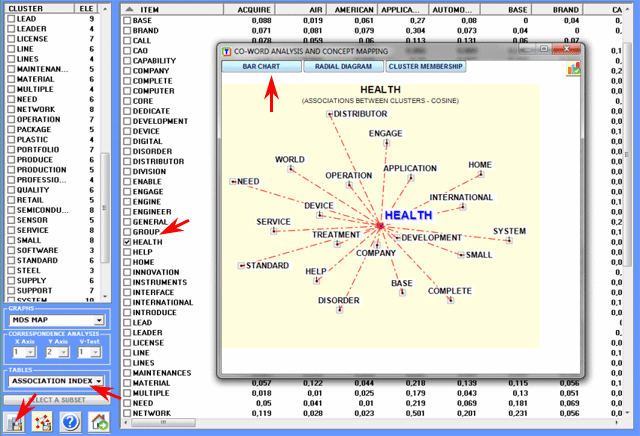
There are available three tables which can be
exported by this T-LAB tool:
1 - "Cluster Membership" table (see below)
deals with the hierarchical aggregation of words within each
cluster;
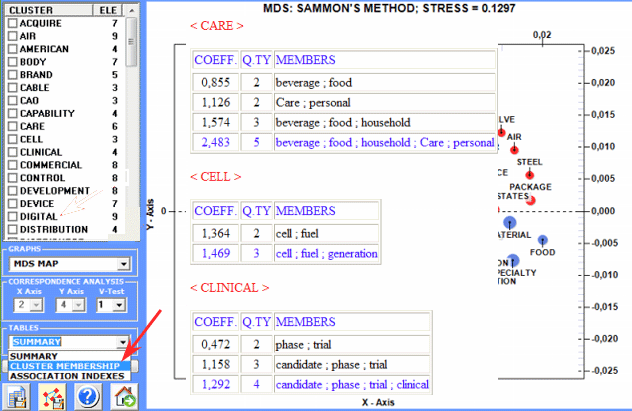
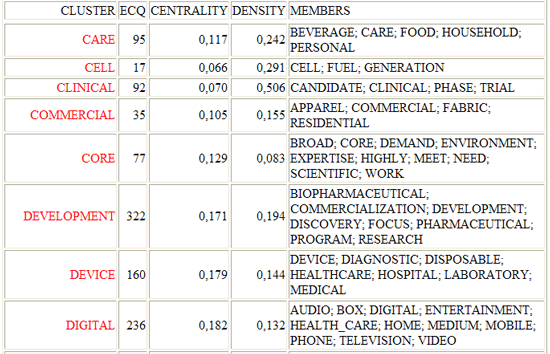
2 - "Summary" table (see below)
includes the following measures:
- ECQ = Quantity of Elementary Contexts in
which two or more word clusters are co-occurring;
- Centrality = average of association indexes concerning
cluster relationships;
- Density = average of word association indexes within each
cluster.
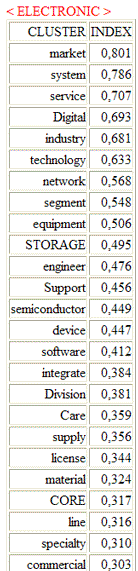
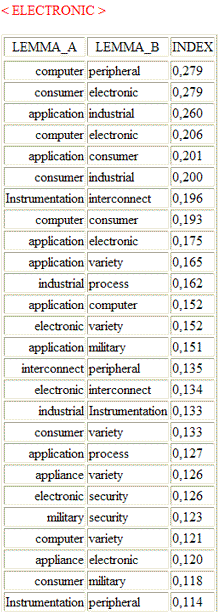
3 - "Association Indexes" table (see
below) includes similarity measures of the between and the within
cluster relationships.
|
Between
|
Within
|
|
|
N.B.:
- when a
Cluster Analysis has not been carried out, the "Cluster Membership"
table is not available, consequently the "Summary" is simplified
and the "Association Indexes" table refers to word co-occurrences
only;
- when exiting from this analysis, the dictionary of
Thematic Nuclei (i.e. the list of labels assigned to each word
cluster) can be exported and, after a thorough revision, can be
imported by means of the Dictionary
Building function. In this way the user will be able to perform
certain second order analyses (i.e. analysis concerning "themes" or
"concepts").
|


