|
www.tlab.it
Modellizazione dei Temi
Emergenti
Questo strumento T-LAB
consente di individuare, esaminare e
modellare i principali temi che emergono dai testi per poi -
eventualmente - utilizzarli in ulteriori analisi, sia esse di tipo
qualitativo (ad. es. per costruire griglie per l'analisi di
contenuto) o di tipo quantitativo.
I temi emergenti, che sono descritti tramite il loro vocabolario
caratteristico, cioè tramite insiemi di parole chiave (lemmi o categorie) co-occorrenti
all'interno delle unità di contesto esaminate, possono essere
infatti utilizzati per classificare
quest'ultime (sia esse documenti o contesti elementari) e
ottenere nuove variabili da utilizzare
in ulteriori analisi T-LAB.

Una finestra di dialogo T-LAB
(vedi sopra) consente di impostare due parametri di
analisi.
In particolare:
- il parametro (A) consente di definire il numero di temi da
ottenere. (Si noti che quanto maggiore è questo numero tanto più
consistenti saranno le relazioni di co-occorrenza all'interno di
ciascun tema; inoltre, se necessario, alcuni temi, ad esempio
quelli ridondanti o difficili da interpretare, potranno essere
eliminati successivamente);
- il parametro (B) consente di escludere dall'analisi qualsiasi
unità di contesto che non contenga un numero minimo di parole
chiave incluse nella lista utilizzata.
Solo quando si sceglie di personalizzare tutti i
parametri di analisi (vedi sopra l'opzione 'Sì'), verrà visualizzata la finestra seguente e
saranno disponibili ulteriori opzioni. (Si noti che nell'immagine
seguente il numero di unità di contesto è determinato dal parametro
"B" menzionato in precedenza).

La procedura automatica di
analisi effettua i seguenti passi:
a -costruzione di una matrice documenti per parole, dove i
documenti sono sempre contesti elementari corrispondenti alle unità
di contesto (cioè frammenti, frasi, paragrafi) in cui il corpus è
stato suddiviso;
b - analisi dei dati tramite un modello probabilistico che usa la
Latent Dirichlet Allocation e il Gibbs Sampling (per ulteriori
informazioni si vedano le corrispondenti voci di Wikipedia:
http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation;
http://en.wikipedia.org/wiki/Gibbs_sampling;
c - descrizione di ogni tema mediante i valori di probabilità
associati alle sue parole caratteristiche, sia esse "specifiche" o "condivise" da due o più temi..
Al termine del processo di analisi, l'utilizzatore può
agevolmente effettuare le seguenti operazioni:
1 - esplorare le caratteristiche di ogni singolo
tema;
2 - esplorare le relazioni tra i vari temi;
3 - rinominare o eliminare specifici temi;
4 - verificare la coerenza semantica dei vari temi;
5 - testare il modello ed assegnare i temi alle unità di contesto,
sia esse documenti e/o contesti elementari;
6 - applicare il modello e creare una nuova variabile tematica da
utilizzare con altri strumenti T-LAB;
7 - esportare un dizionario delle categorie che potrà essere
utilizzato in ulteriori analisi.
Nel dettaglio:
1 - Esplorare le caratteristiche di ogni
singolo tema
Il primo output che può essere consultato e salvato è
costituito da una tabella con una sintesi di tutti i temi. E,
quando lo si desideri, la stessa tabella può essere visualizzata
usando il pulsante 'Anteprima' (vedi
sotto).
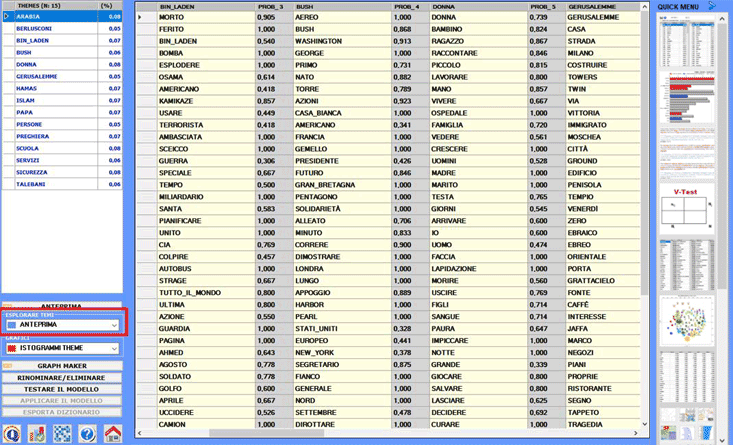
Altri tipi di output sono accessibili selezionando una
delle opzioni evidenziate nell'immagine seguente.
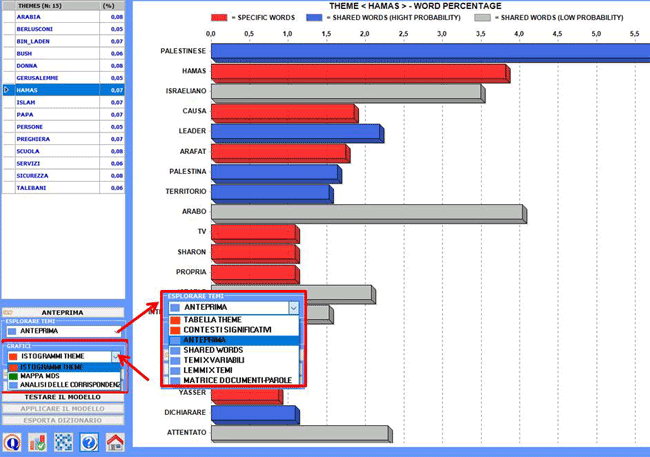
N.B.: In questo tipo di grafico (vedi sopra) "hight
probability" indica una probabilità >=.75.
Quando viene selezionato un tema, facendo clic
sull'opzione "Tabella Theme", è possibile verificare le sue
caratteristiche; inoltre - facendo clic su qualsiasi parola nella
tabella mostrata - diventa disponibile l'opzione per "eliminare" specifiche parole dal tema (vedi
immagine seguente).
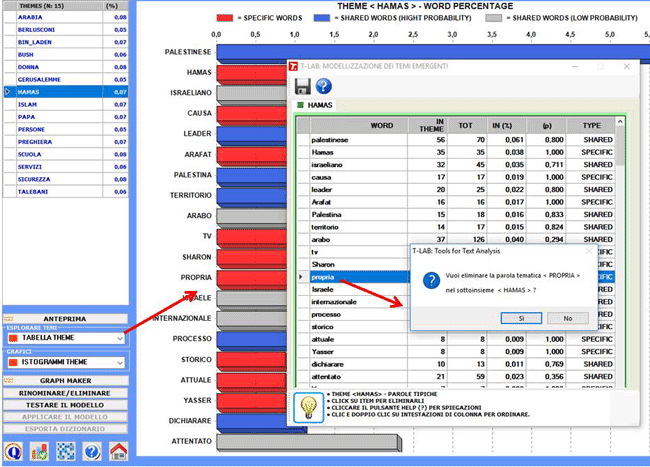
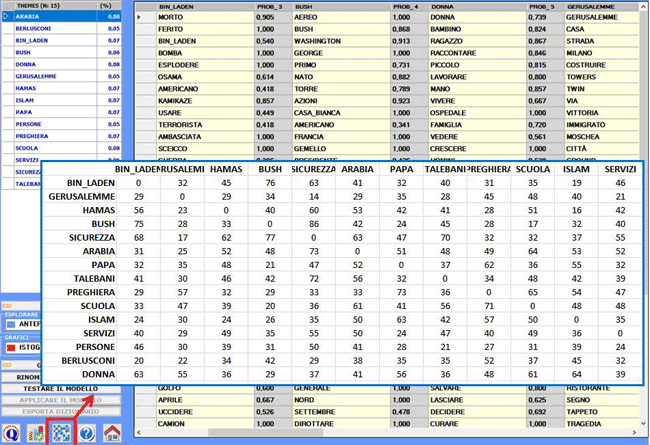
Le chiavi di lettura di questo tipo di tabella sono le
seguenti:
IN THEME = occorrenze (tokens) di ogni parola all'interno del tema
selezionato;
TOT = occorrenze (tokens) di ogni parola all'interno del corpus o
del sottoinsieme analizzato;
IN (%) = peso percentuale di ogni parola all'interno del tema
selezionato;
(p) = valore di probabilità associato a ogni relazione parola x
tema;
TYPE = contrassegnato con "specific"
quando la parola (con p = 1) appartiene solo al tema selezionato, e
come "shared" negli altri casi (cioè
quando la parola, in diverso modo, è presente in più di un
tema).
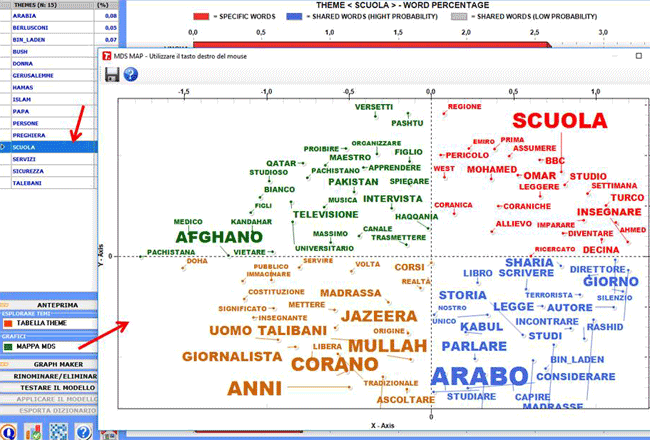
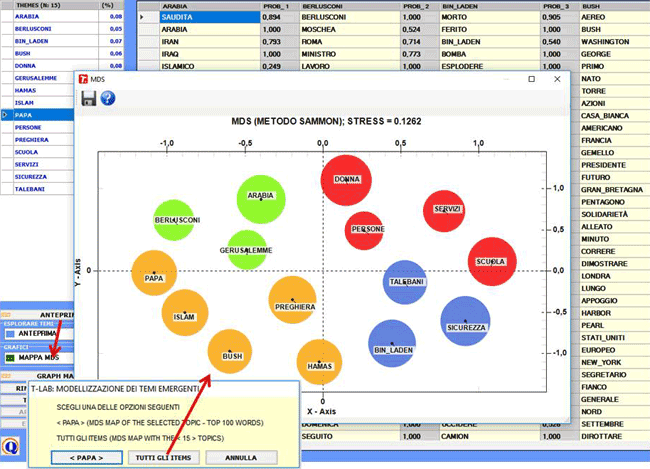
Quando viene selezionato un tema, facendo clic
sull'opzione "Mappa MDS" si possono
facilmente esplorare le relazioni semantiche tra le parole che
risultano più caratteristiche (vedere l'immagine
seguente).
Inoltre, utilizzando lo strumento 'Graph Maker', diventano disponibili ulteriori
opzioni grafiche (vedi le immagini seguenti).
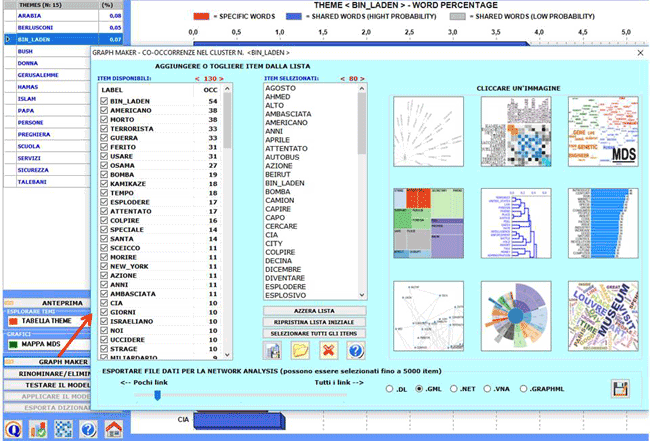
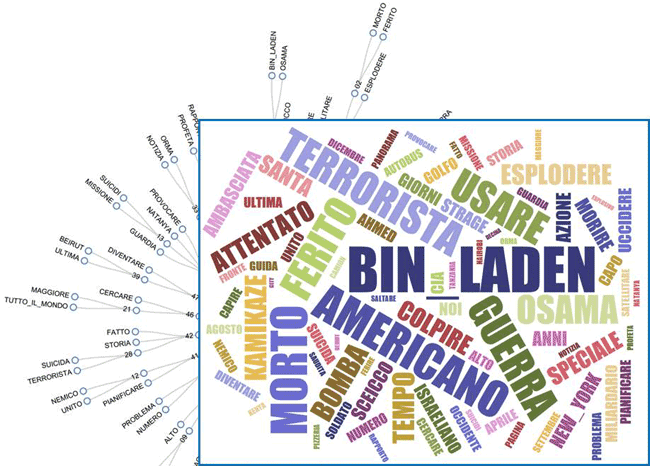
Quando viene selezionato un tema, facendo clic
sull'opzione 'contesti significativi', viene creato un file HTML in
cui vengono visualizzati i primi 20 segmenti di testo, che
corrispondono maggiormente alle caratteristiche del tema in
questione (vedere l'immagine seguente).
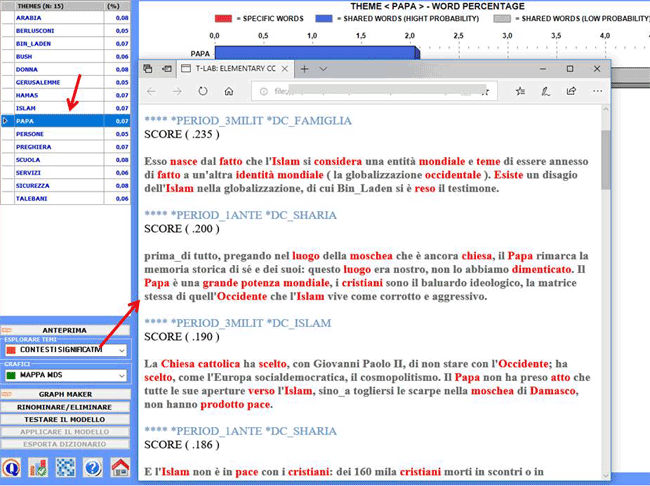
2 - Esplorare le relazioni tra i vari
temi
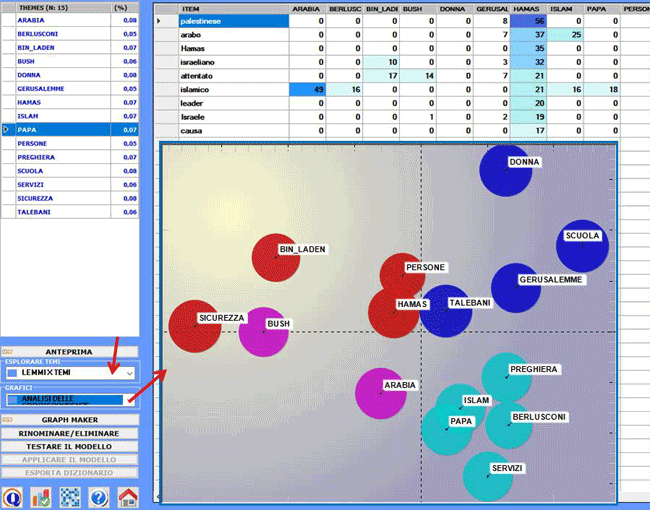
Tramite lo strumento Analisi delle
Corrispondenze è possibile creare ed esplorare due tipi di
tabelle di contingenza:
2.1) una tabella parole per temi (vedi sotto)
2.2) una tabella che incrocia i temi con le modalità
variabile selezionata

Sono anche disponibili altre due opzioni grafiche che
consentono di mappare le relazioni tra i vari temi / topic:
2.3) una Mappa MDS
2.4) grafici di rete ottenuti esportando / importando la
tabella di adiacenza creata da T-LAB (vedi sotto)
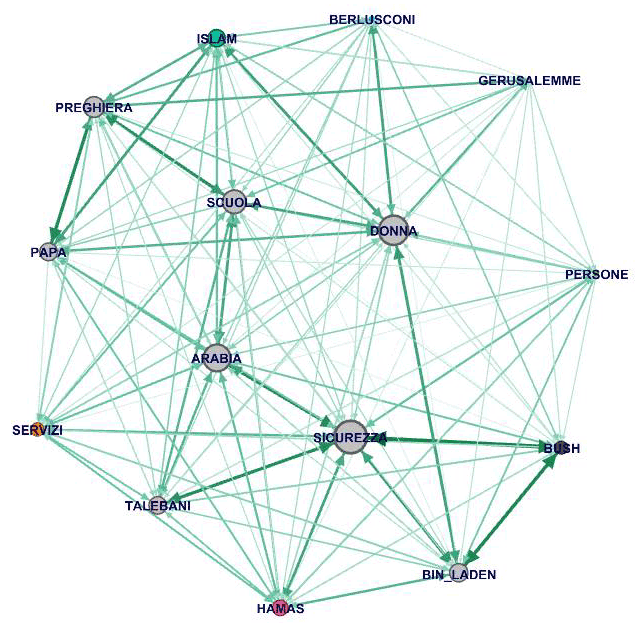
N.B.: Questo grafico è stato creato utilizzando il
software open-source Gephi (https://gephi.org/ ) per importare una
tabella esportata tramite T-LAB.
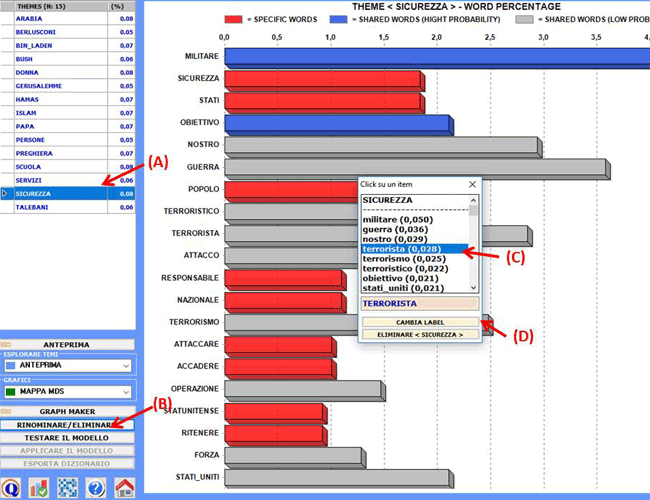
3 - Rinominare o eliminare
specifici temi
Per rinominare o eliminare specifici temi è sufficiente selezionare
gli item corrispondenti (vedi sotto "A") e cliccare sul pulsante
"rinominare/eliminare" (vedi sotto
"B").
Quando compare il box con le varie opzioni (vedi sotto), a seconda
dei propri obiettivi, l'utilizzatore può cambiare la label del tema
(sia scegliendo tra le parole disponibili che digitandone una
nuova; vedi sotto "C") oppure eliminare il tema selezionato con un
click sull'apposito pulsante (vedi sotto "D").
4 - Verificare la coerenza semantica dei
vari temi

Quando viene cliccato il pulsante 'Indici di Qualità', T-LAB calcola le similarità tra le prime dieci
(top 10) parole caratteristiche di ogni tema.
Più specificatamente:
- le prime 10 parole sono quelle con il più alto valore di
probabilità;
- le misure di similarità sono calcolate usando il coefficiente del
coseno;
- come nel caso dello strumento Associazioni di Parole, il coefficiente del
coseno è calcolato verificando le co-occorrenze di ogni coppia di
parole all'interno dei segmenti di testo definiti come contesti
elementari.
Come risultato, T-LAB crea un
file HTML in cui i 'k' temi solo elencati con il rispettivo indice
di 'coerenza semantica'.
N.B.: Poiché le misure di similarità variano con il variare delle
parole selezionate, si raccomanda di ripetere la procedura ogni
volta che qualcuna delle prime dieci parole di un qualche tema
venga eliminata dall'utilizzatore.
5 - Testare il
modello
Al termine dell'analisi dei dati (vedi sopra i punti "a" e "b"
relativi alla procedura di analisi) ogni unità di contesto (es. un
documento o un contesto elementare) risulta costituito da un una
"mistura" di temi (o topics). Diversamente, il processo di
classificazione utilizzato in questa fase consente di associare
ogni unità di contesto al tema che più lo caratterizza. Ne risulta
che, a questo punto, ogni tema diventa di fatto un cluster di unità
di contesto.
Per questa ragione, quando viene selezionata l'opzione
"Testare il modello" T-LAB
produce due file XLS (vedi sotto) che consentono all'utilizzatore
di verificare l'appartenenza di ogni unità di contesto a uno
specifico tema.
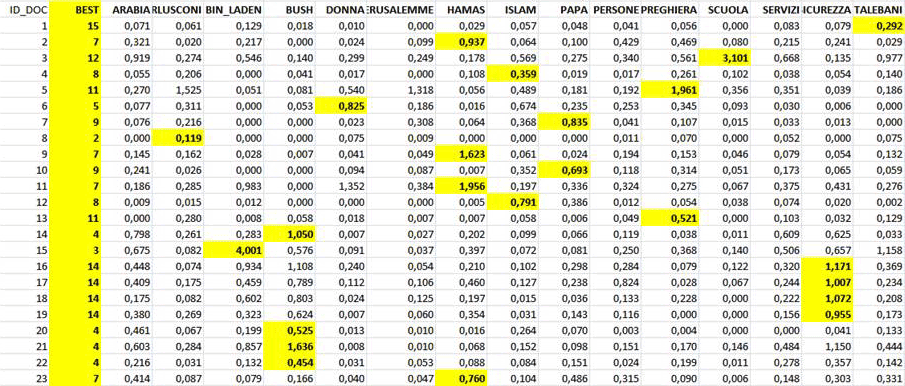
N.B.: Nella tabella sopra riportata, ogni documento ha un
valore di probabilità associato ad ogni tema.

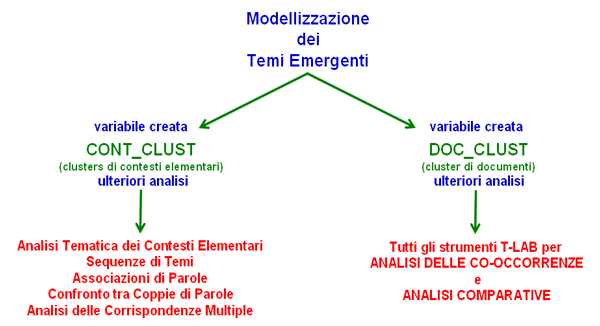
6 - Applicare il modello
Dopo aver applicato e
salvato il modello, poiché i temi sono archiviati da
T-LAB
come modalità di due nuove variabili che si riferiscono a cluster
di contesti elementari (CONT_CLUST)
e/o a cluster di documenti (DOC_CLUST), le relazioni tra gli stessi temi e/o
tra le loro caratteristiche possono essere ulteriormente esplorati
con diversi strumenti di analisi (vedi sotto).
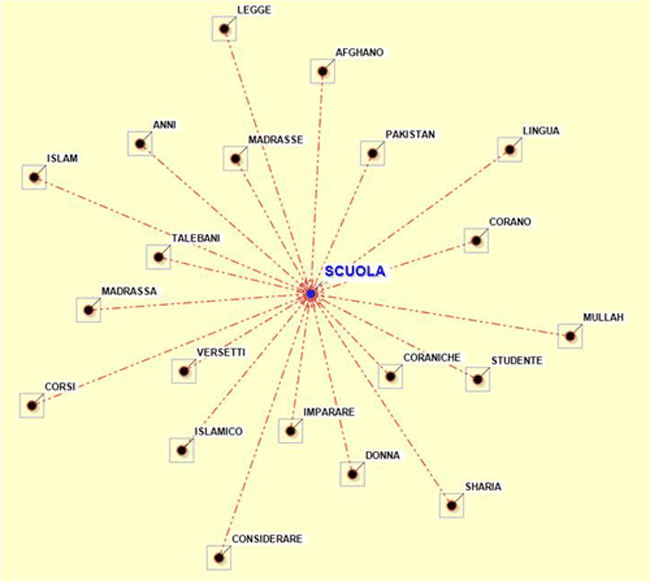
Ad esempio, utilizzando lo strumento Associazioni di Parole e selezionando il
sottoinsieme (cioè il tema) "Religione" è possibile creare il
grafico seguente.
7 - Esportare un
dizionario
Quando viene selezionata questa opzione, T-LAB crea un file dizionario con estensione
.dictio pronto per essere importato
tramite uno degli strumenti per l'analisi tematica. In tale
dizionario ciascun categoria è descritta tramite le sue parole
caratteristiche.
|


