|
www.tlab.it
Corpus e
Sottoinsiemi
Corpus: collezione di
uno o più testi selezionati per un lavoro di analisi.
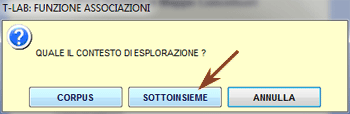
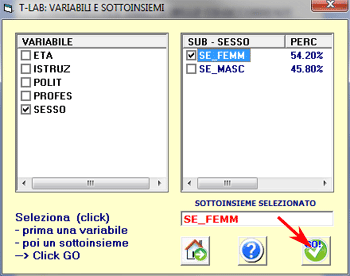
Sottoinsieme: una
parte del corpus definita tramite l'uso di variabili e modalità.
T-LAB consente
- in modo automatico - di esplorare e di analizzare le relazioni
tra le unità di analisi di tutto il corpus o di suoi sottoinsiemi.
Qualche esempio di corpus:
- un singolo testo o documento che tratti un qualunque
argomento;
-
un insieme di articoli tratti dalla stampa e che
affrontano lo stesso argomento;
-
una o più interviste realizzate entro un progetto
di ricerca;
-
uno o più libri dello stesso autore o che
affrontano temi simili;
-
una mailing-list scaricata da internet;
-
un insieme di risposte a una "domanda aperta" di un
questionario;
- una o più trascrizioni di focus group.
Qualche esempio di sottoinsieme:
- nel caso di un corpus costituito da articoli pubblicati
in vari anni (es ANNO = variabile usata), tutti gli articoli di un
determinato anno (es 2001 = modalità della variabile anno);
- nel caso di risposte a domande aperte, tutte le risposte
di una determinata categoria di persone (es FEM = modalità della
variabile SESSO);
- nel caso di un corpus suddiviso per aree tematiche (es
TEMA = variabile), tutte le parti che si riferiscono allo stesso
tema (es SCUOLA = modalità della variabile TEMA).
N.B.: Sottoinsiemi del corpus sono anche i
"cluster tematici" di documenti
o di contesti elementari ottenuti utilizzando i corrispondenti
strumenti T-LAB.
Nel caso di un corpus costituito da più testi,
perché questo sia un insieme
utilmente analizzabile,
si richiede che le sue parti abbiano due
caratteristiche che li rendano comparabili:
a) una qualche omogeneità tematica e/o del contesto
in cui sono stati prodotti, in modo da ottenere dati tra loro
confrontabili;
b) un equilibrato rapporto tra le loro dimensioni,
sia in termini di occorrenze sia in termini di Kbytes, per non
incorrere in "anomalie" di tipo statistico.
Entro la logica di T-LAB, il corpus è un database organizzato in record e campi. Più precisamente, i record sono costituiti
dalle entità archiviate (testi, frammenti di testi, parole) e i
campi sono costituiti dalle caratteristiche utilizzate per
classificare le varie entità (gli autori dei testi, i contesti di
riferimento, i tipi di parole, etc.).
Vedi Preparazione del
Corpus
|


