|
www.tlab.it
Classificazione Tematica dei
Documenti
Questa funzione è abilitata solo quando il corpus in
analisi comprende da un minimo di 20 a un massimo 99.999 documenti
primari.
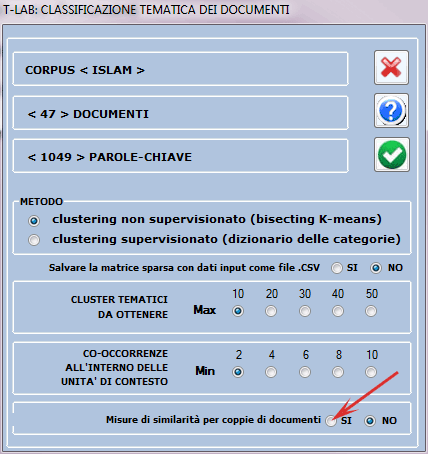
Il processo di analisi può essere effettuato tramite un
metodo di clustering 'non supervisionato' (nel caso specifico, un
algoritmo di bisecting K-Means) o tramite una classificazione
supervisionata (vale a dire approccio top-down). Quando si sceglie
il secondo (cioè classificazione supervisionata), viene richiesto
di importare un dizionario delle categorie, sia esso creato tramite
una precedente analisi T-LAB
che costruito dall'utilizzatore.
Il suo uso consente di costruire cluster di documenti e
di esplorare le loro caratteristiche attraverso operazioni/opzioni
simili a quelle descritte nella sezione dell'help dedicata
all'Analisi Tematica dei Contesti
Elementari.
La sua specificità consiste nel fatto che la tabella
analizzata è costituita da tante righe quanti sono i documenti del
corpus, ciascuno dei quali è rappresentato come un vettore con
valori che indicano le occorrenze delle parole in esso
presenti.
Inoltre, quando i documenti analizzati non superano i
3000, è possibile ottenere misure di similarità (indice del coseno)
tra ciascuno di essi e tutti gli altri (vedi sotto).N.B.: In questo
caso la soglia minima dell'indice di similarità è fissata a
0.05.
Gli output che differenziano questa funzione sono quindi
i seguenti:
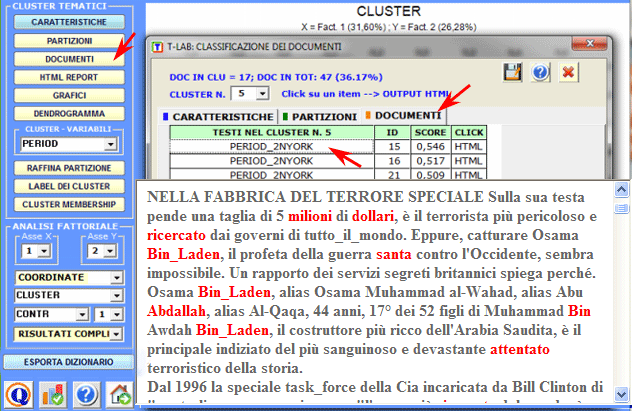
I documenti appartenenti ad ogni cluster sono ordinati
secondo il valore decrescente del loro score (vedi sopra) e possono
essere esplorati nel formato HTML.
In questo caso il valore di
rilevanza (score) assegnato ad ogni documento (i) del cluster (k) è
ottenuto applicando la seguente formula:
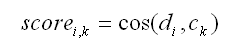
Dove:
i - si riferisce al documento
i;
k - si riferisce cluster k;
cos - è il simbolo di coseno;
di - è il vettore normalizzato del TFj,i IDFj, dove
j si riferisce a una parola del documento i
ck - è il vettore normalizzato del TFj,k IDFj, dove j
si riferisce una parola del cluster k
Usando gli score ottenuti dalla suddetta formula,
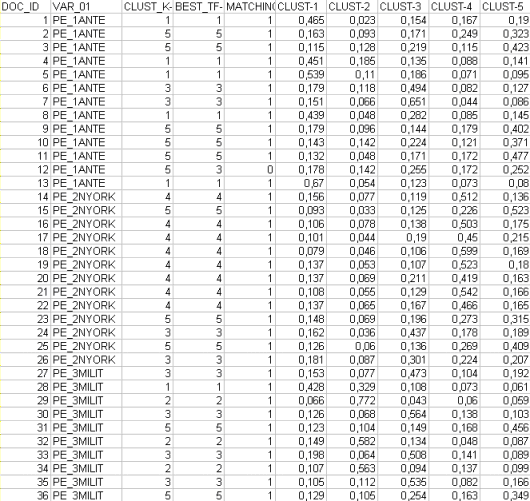
T-LAB rende disponibile il file
"Document_Membership_Degree.xls " (vedi sotto) che contiene i
cluster a cui sono stati assegnati i vari documenti, sia mediante
il metodo bisecting K-Means (appartenenza esclusiva di ogni
documento a un cluster) che mediante il valore del TF-IDF
(appartenenza "mista" - in formato percentuale - di ogni documento
ai vari cluster).
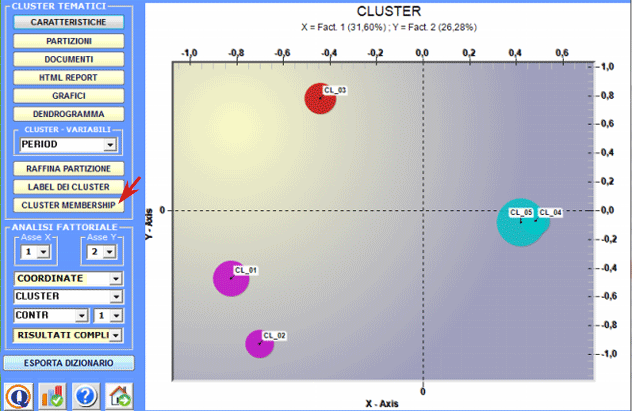
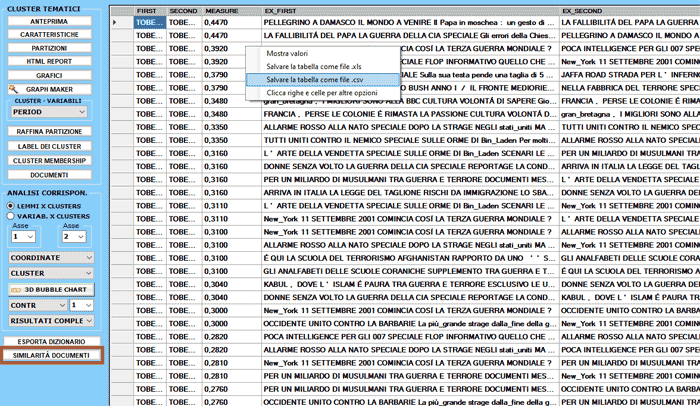
Quando il pulsante Similarità
Documenti è abilitato, cliccando su di esso è possibile
verificare in che misura ogni documento è simile a ciascuno degli
altri. In questo caso la misura di similarità è il coefficiente del
coseno e il suo valore varia in funzione di quante parole sono
state utilizzate per la classificazione tematica.
L'immagine seguente descrive le opzioni disponibili per
questo tipo di verifica.
All'uscita di questa funzione, alcuni messaggi ricordano che è
possibile esplorare i cluster ottenuti con altri strumenti
T-LAB.

Scegliendo l'opzione "SALVA", la variabile <
DOC_CLUST> (cluster di documenti)
resta disponibile in tutte le successive analisi dello stesso
corpus realizzate con altri strumenti T-LAB.
|


