|
www.tlab.it
Singular Value
Decomposition
La Singular Value Decomposition (SVD - vedi
Wikipedia https://en.wikipedia.org/wiki/Singular-value_decomposition)
è una tecnica per la riduzione delle dimensioni, che - in Text
Mining - può essere utilizzata per verificare le dimensioni
latenti (o componenti) che determinano le somiglianze
semantiche tra parole (cioè unità lessicali) o tra documenti
(cioè unità di contesto).
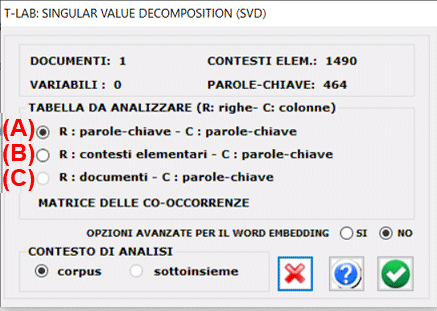
T-LAB ci consente di
eseguire una Singular Value Decomposition di tre tipi di tabelle
dati. Nel primo caso (vedi 'A' sotto), la tabella dati è una
matrice delle co-occorrenze con - in riga e in colonna - le parole
chiave selezionate. Nel secondo caso (vedi 'B' sotto), la tabella
dati contesti elementari X parole chiave conterrà valori di
presenza / assenza (cioè '1' e '0'). Nel terzo caso (vedi "C"
sotto), la tabella dati documenti X parole chiave conterrà valori
di occorrenza.
N.B.: Si noti che, quando vengono analizzate matrici di
co-occorrenze, le cui righe e colonne sono termini chiave (vedere
'A' di seguito), T-LAB fornisce
vettori densi di alta qualità (cioè word embeddings).
La procedura di analisi consiste dei seguenti
passaggi:
1 - costruzione della tabella dati da analizzare (fino a 300.000
righe x 5.000 colonne);
2 - normalizzazione TF-IDF e applicazione della norma euclidea
(i.e. trasformazione di tutti i vettori a lunghezza '1');
3 - estrazione delle prime 20 'dimensioni latenti' attraverso
l'algoritmo di Lanczos.
N.B.:
- Nel caso della matrici di co-occorrenze (vedi 'A' sopra),
la normalizzazione dei dati è ottenuta mediante la misura del
coseno;
- Quando sono selezionate le opzioni avanzate per
il word embedding, T-LAB
calcola i valori PPMI (Positive Pointwise Mutual Information) e
rende possibile l'utilizzo delle prime 50 dimensioni della
SVD.
I risultati dell'analisi sono sintetizzati in
tabelle e grafici.
Nel dettaglio:
Due tabelle - le cui righe possono essere unità lessicali o unità
di contesto - hanno tante colonne quante sono le dimensioni
estratte (cioè 20).
Nel caso della tabella LEMMI (cioè unità lessicali),
viene visualizzata un'ulteriore colonna in cui vengono riportati
punteggi di importanza (vedi 'score' nella tabella
seguente).
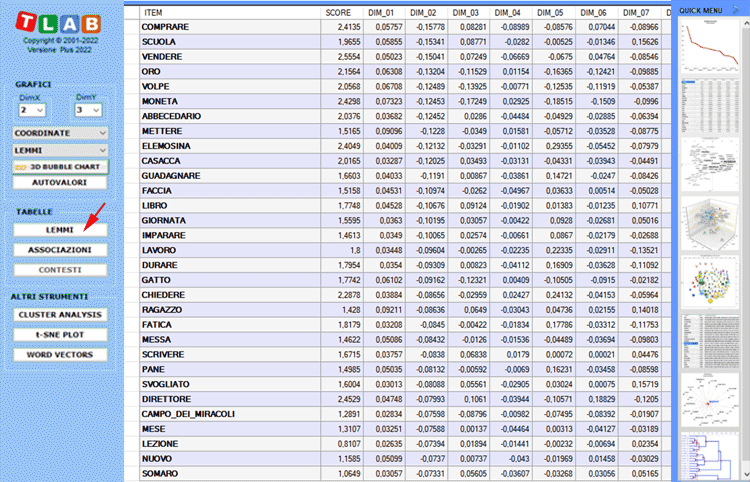
N.B.: Il punteggio di importanza di ciascun lemma
è calcolato sommando i valori assoluti delle sue prime 20
coordinate (cioè gli autovettori), ciascuno moltiplicato per l'
autovalore corrispondente.
Qualsiasi tabella può essere ordinata in ordine crescente
o decrescente facendo clic su qualsiasi intestazione di
colonna.
Per esportare qualsiasi tabella, basta usare il tasto destro
del mouse quando vengono visualizzati i relativi dati.
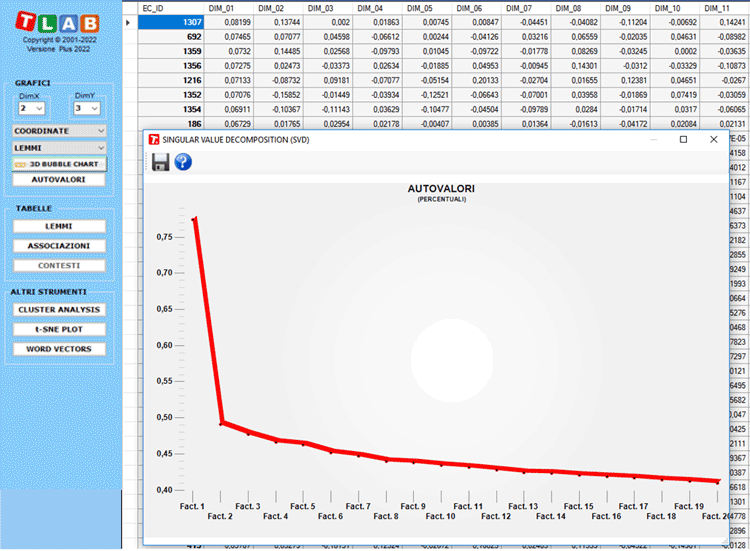
Si noti che, la prima volta che viene esportata una tabella di
questo tipo, vengono esportati anche gli autovalori. In questo modo
l'utente può agevolmente valutare il peso relativo di ogni
dimensione, cioè la percentuale di varianza spiegata da ciascuna
delle 20 dimensioni.
Facendo clic sul pulsante Associazioni, viene
visualizzata un'ulteriore tabella con le misure di somiglianza
(cioè i coefficienti del coseno) relative ad ogni parola. Inoltre,
quando si fa clic su una qualsiasi riga di tale tabella, viene
visualizzato un grafico con i dati corrispondenti.

I grafici principali mostrano le relazioni tra i
termini chiave (cioè i lemmi) sulle dimensioni selezionate (vedi
sotto).
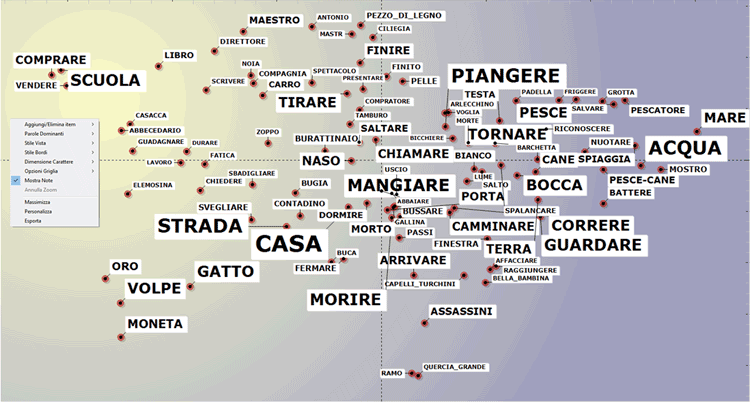
Per impostazione predefinita, il grafico di cui sopra
include i 100 lemmi più importanti. Tuttavia, l'utilizzatore può
personalizzare sia il numero di lemmi sia le caratteristiche del
grafico.
|


