|
www.tlab.it
Associazioni di
Parole
 N.B.: Le immagini di questa sezione fanno riferimento a una
versione precedente di T-LAB.
In T-LAB 10 l'aspetto è
leggermente diverso. Inoltre: a) una nuova opzione permette
all'utilizzatore di visualizzare una Mappa
MDS con le parole più rilevanti; b) un nuovo strumento
(Graph Maker) consente di creare ed
esportare vari tipi di grafici dinamici in formato HTML; c) il
tasto destro sulle tabelle con le
parole chiave rende disponibili opzioni supplementari; d) una
galleria di immagini funziona come un menu aggiuntivo e consente di
passare da un output all'altro con un solo clic.
N.B.: Le immagini di questa sezione fanno riferimento a una
versione precedente di T-LAB.
In T-LAB 10 l'aspetto è
leggermente diverso. Inoltre: a) una nuova opzione permette
all'utilizzatore di visualizzare una Mappa
MDS con le parole più rilevanti; b) un nuovo strumento
(Graph Maker) consente di creare ed
esportare vari tipi di grafici dinamici in formato HTML; c) il
tasto destro sulle tabelle con le
parole chiave rende disponibili opzioni supplementari; d) una
galleria di immagini funziona come un menu aggiuntivo e consente di
passare da un output all'altro con un solo clic.
Alcune di queste nuove funzionalità sono evidenziate nell'immagine
seguente.
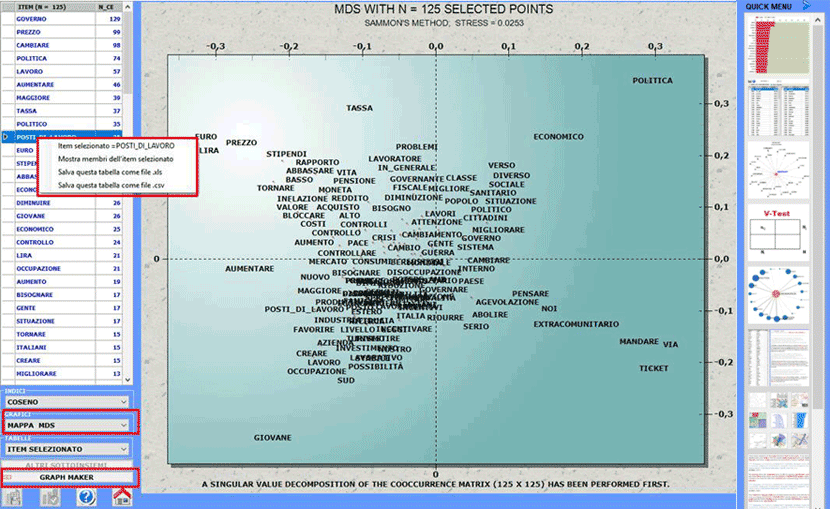
Questo strumento T-LAB consente di verificare le relazioni di
co-occorrenza e di similarità che,
all'interno del corpus o di un suo sottoinsieme, determinano il
significato locale delle parole chiave
selezionate dall'utilizzatore.
Tale verifica può essere effettuata tramite opzioni
predefinite (A) o tramite opzioni selezionate dall'utilizzatore
(B).
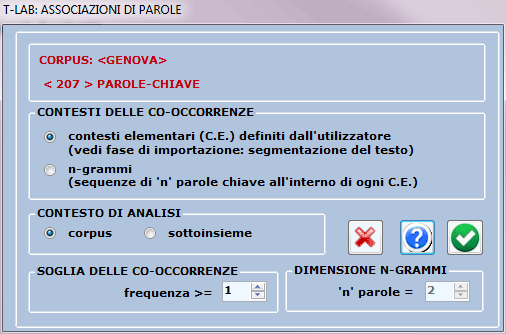
Nel primo caso (A: opzioni predefinite) le co-occorrenze delle parole sono calcolate
all'interno dei contesti elementari
selezionati in fase di importazione del corpus (es., frasi,
frammenti, paragrafi, etc.); diversamente, nel secondo caso (B:
opzioni selezionate dall'utilizzatore) le co-occorrenze possono
essere anche calcolate all'interno di sequenze di parole di
lunghezza variabile (cioè n-grammi) ed è
anche possibile decidere la soglia minima (cioè la frequenza) delle
co-occorrenze da considerare.
La finestra di lavoro (vedi sotto) è resa disponibile
subito dopo aver effettuato il calcolo delle co-occorrenze tra
tutte le parole incluse nella lista selezionata
dall'utilizzatore.
Sulla sinistra di questa finestra è riportata una
tabella con la lista delle parole chiave e valori numerici che
indicano la quantità di contesti elementari o n-grammi in cui
ciascuna parola risulta presente.
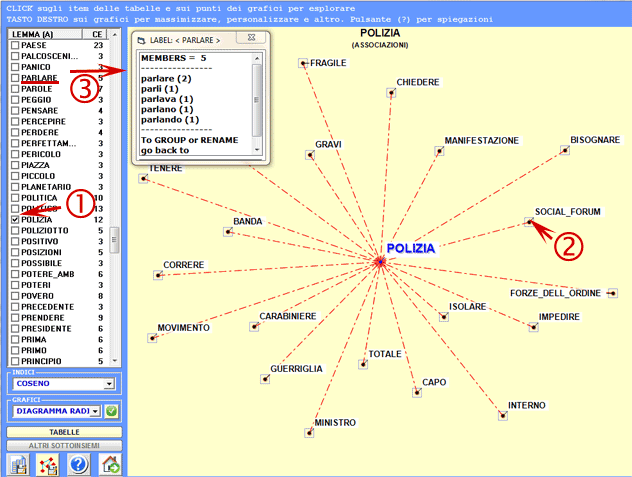
Un semplice click sugli item della tabella (opzione
'1') o sui punti dei grafici (opzione '2') consente di verificare
le associazioni relative a ciascuna parola target. Diversamente un
click sulle label incluse nella tabella (opzione '3') consente di
verificare gli item inclusi in ogni lemma.
Di volta in volta, la selezione delle parole
associate è effettuata tramite il calcolo di un Indice di Associazione (vedi corrispondente
sezione del glossario) o tramite un indice di somiglianza del
secondo ordine (vedi spiegazione al termine di questa sezione). Nel
primo caso gli indici disponibili sono sei (Coseno, Dice, Jaccard,
Equivalenza, Inclusione e Informazione Mutua) e il loro calcolo è
piuttosto rapido; diversamente, nel caso degli indici del secondo
ordine - e soprattutto quando il corpus è di notevoli dimensioni -
l'analisi dei dati può richiedere minuti. Inoltre va tenuto conto
del fatto che, nel caso degli indici del secondo ordine, i
risultati sono tanto più affidabili quanto più numerose le parole
incluse nella lista.
Ad ogni interrogazione, T-LAB produce grafici e tabelle.
Sia le tabelle che i grafici possono essere
esportate tramite l'uso di appositi pulsanti.
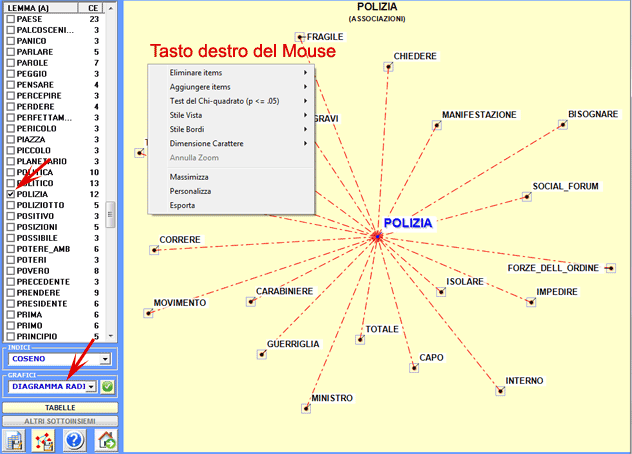
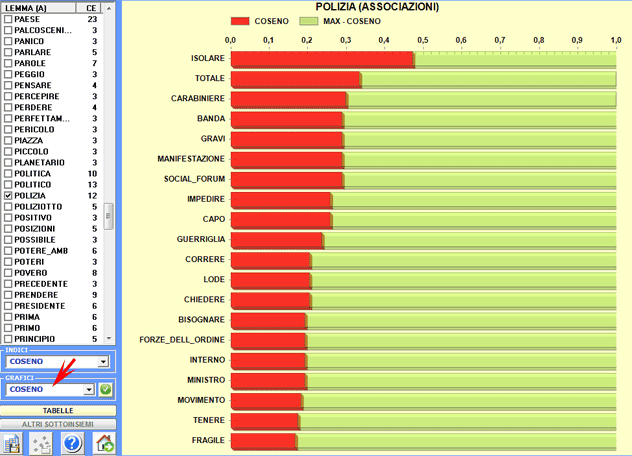
Nei diagrammi radiali,
il lemma selezionato è posto al centro. Gli altri sono distribuiti
intorno ad esso, ciascuno a una distanza proporzionale al suo grado
di associazione. Le relazioni significative sono quindi del tipo
uno-ad-uno, tra il lemma centrale e ciascuno degli altri.
Ogni click su un item produce un nuovo grafico e, tramite l'uso del
tasto destro del mouse, è possibile aprire una finestra di dialogo
che consente vari tipi di personalizzazione (vedi
sotto).
Le tabelle
contengono dati che consentono di verificare le relazioni tra
occorrenze e co-occorrenze delle parole (Max. 50) che risultano più
associate a quella selezionata.
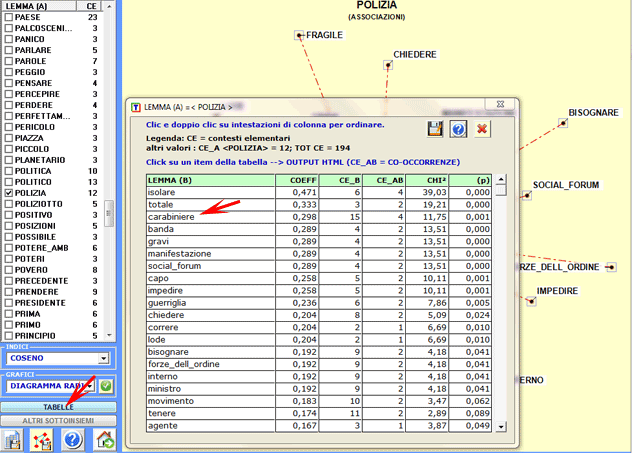
Le chiavi di lettura sono le seguenti:
- LEMMA (A) = lemma selezionato (quello al centro del
grafico);
- LEMMA (B) = lemmi associati a quello selezionato;
- COEFF = valore dell'indice selezionato;
- TOT CE = totale dei contesti elementari (CE) o degli
n-grammi analizzati;
- CE_A = totale dei CE in cui è presente il lemma
selezionato (A);
- CE_B = totale dei CE in cui è presente ogni lemma
associato (B);
- CE_AB = totale dei CE in cui i lemmi "A" e "B" sono
associati (co-occorrenze);
- CHI2 = valore del chi quadro che esprime la
significatività delle co-occorrenze;
- (p) = probabilità associata al valore del chi
quadro (def=1).
Nel caso del chi quadro, per ogni coppia di
lemmi ("A" e B") la struttura della tabella analizzata è la
seguente
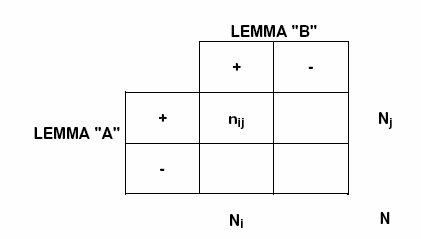
Dove nij = CE_AB, Nj = CE_A, Ni = CE_B, N = TOT
CE.
Un click su ogni item della tabella (es. "carabiniere") consente di
visualizzare e di salvare un file con tutti i contesti elementari in cui esso è presente
insieme alla parola centrale (es. co-occorrenze di "carabiniere" e
"polizia").

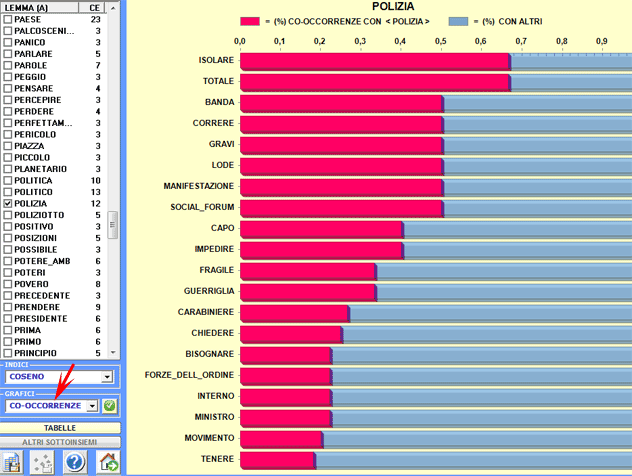
Ulteriori grafici (Istogrammi) consentono di apprezzare le
differenze tra i valori del coefficiente utilizzato e tra le percentuali delle co-occorrenze (vedi
sotto).
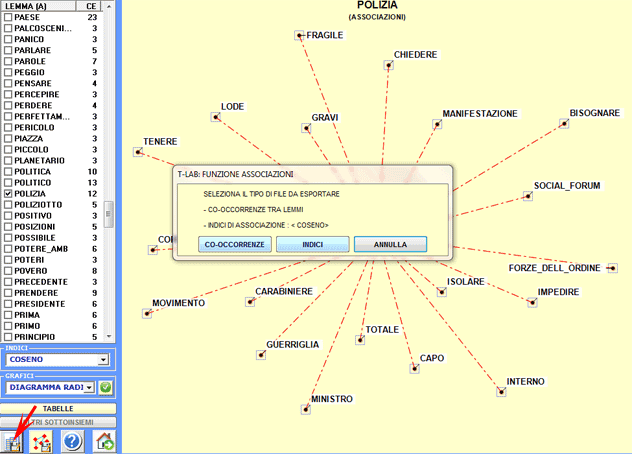
Cliccando sul pulsante in basso a sinistra
l'utilizzatore può esportare vari tipi di tabelle (vedi immagine
seguente) .
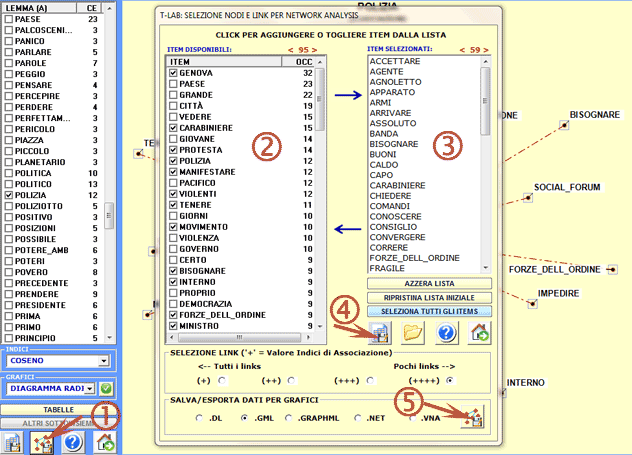
Una ulteriore finestra T-LAB (vedi immagine seguente, step 1)
consente di creare file grafici che possono essere editati con
software per la network analysis quali Gephi, Pajek, Ucinet, yEd ed
altri. In questo caso, i nodi della
rete sono costituiti dalle parole associate con la parola target.
Le opzioni disponibili sono le seguenti: selezionare gli item (cioè
i 'nodi') da inserire nei grafici (vedi sotto, step 2 e 3),
esportare la corrispondente matrice di adiacenza (vedi sotto, step
4), esportare il tipo di file grafico prescelto (vedi sotto, step
5).
N.B.: In T-LAB 10 la
finestra seguente è stata sostituita con lo strumento Graph Maker.
Ad esempio, file .gml esportati da T-LAB possono consentire di realizzare grafici
come quelli riportati alla fine di questa sezione.
Le modalità di calcolo dei vari indici di 'associazione'
(o prossimità) sono illustrate nella corrispondente sezione del
Manuale/Help (vedi glossario). Come si
potrà verificare, tutti questi indici sono ottenuti attraverso una
normalizzazione dei valori di co-occorrenza concernenti coppie di
parole; quindi - nei calcoli del 'primo ordine' - due parole mai
co-occorrenti hanno un indice di associazione pari a
'0'.Diversamente, gli indici del secondo
ordine evidenziano fenomeni di similarità concernenti l'uso (e quindi il
significato) delle parole che non dipendono direttamente dalle loro
co-occorrenze; infatti, in questo caso, due parole mai
co-occorrenti possono avere un indice di associazione anche molto
elevato.
Utilizzando alcuni concetti della linguistica strutturale, possiamo
affermare che mentre gli indici del 'primo ordine' rilevano
fenomeni concernenti l'asse sintagmatico (combinazione e prossimità
'in praesentia', cioè parole 'l'una accanto all'altra' in una
specifica frase), gli indici del 'secondo ordine' rivelano fenomeni
concernenti l'asse paradigmatico (associazione e similarità 'in
absentia', cioè relazioni di quasi-sinonimia tra due o più termini
usati dallo stesso autore). In effetti, all'interno dei testi
analizzati, le parole con una elevata similarità del secondo ordine
sono spesso quasi-sinonimi.
Per capire il modo in cui T-LAB calcola gli indici del 'secondo ordine',
è utile ricordare che gli indici del 'primo ordine' possono essere
utilizzati per costruire matrici di prossimità come la seguente
(A).
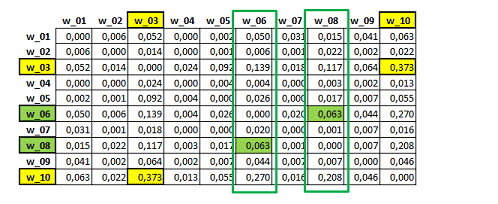
Matrice 'A' - Similarità del Primo Ordine
In questa matrice simmetrica (A), il valore 0.373 (in giallo)
corrisponde al più elevato indice del 'primo ordine' ed indica
l'associazione tra le parole 'w_03' e 'w_10'. Più specificamente,
si tratta di un indice di equivalenza ottenuto dividendo il
quadrato delle loro co-occorrenze per il prodotto delle loro
occorrenze (360^2/627*553).
A partire dalla matrice di cui sopra (A), T-LAB costruisce una seconda matrice (B)
ottenuta calcolando i coseni risultanti dal confronto di tutte le
colonne contenenti gli indici del primo ordine (vedi matrice 'A').
Come di può verificare, nella seguente tabella 'B' il valore di
'similarità' più elevato riguarda la relazione tra le parole 'w_06'
e 'w_08'. Ciò significa che i rispettivi vettori (vedi le due
colonne evidenziate in verde nella matrice 'A'), dopo essere stati
opportunamente normalizzati, risultano essere tra loro molto simili
(coseno = 0.905), anche se l'associazione del 'primo ordine' tra le
parole due parole in questione risulta piuttosto bassa
(0.063).
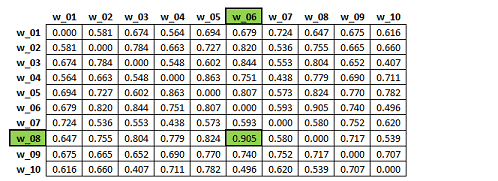
Matrice 'B' - Similarità del Secondo Ordine
Detto in altri termini, un indice del 'primo ordine' è ottenuto
applicando una formula che include valori di co-occorrenza e
occorrenza, mentre un indice del 'secondo ordine' è ottenuto
moltiplicando due vettori normalizzati.
Al di là delle modalità di calcolo, va sottolineato il
fatto che nei due casi ('A' e 'B') vengono rilevati due diversi
fenomeni. Nel primo caso ('A'), infatti, il focus è sulle
co-occorrenze; diversamente, nel secondo caso ('B') - e
indipendentemente dalle loro co-occorrenze - il focus è sulle
somiglianze tra 'profili' i cui dati fanno riferimento all'uso
delle parole da parte degli autori dei testi analizzati.
Tanto per fare un esempio, nell'analisi di Pinocchio del primo
ordine il termine 'fata' risulta prevalentemente associato (vedi
co-occorrenze) con 'buona' e 'capelli turchini'; diversamente,
nell'analisi del secondo ordine, il termine che risulta più simile
a 'fata' è 'mamma', anche se le co-occorrenze tra questi due
termini ('fata' e 'mamma') sono - all'interno della fiaba di
Collodi - pressoché irrilevanti (cioè solo 3).
Le tabelle visualizzate da T-LAB consentono di verificare sia le
similarità del secondo ordine (vedi sotto colonna SIM-II°) che gli
indici del primo ordine (EQU-I°, cioè indice di
equivalenza).
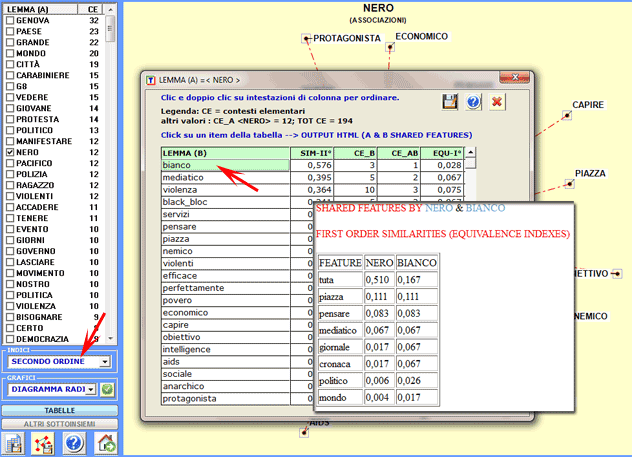
Inoltre, cliccando su ogni item di questa tabella, è
possibile visualizzare file HTML che consentono di verificare quali
'caratteristiche' ('features') determinano la somiglianza tra ogni
coppia di parole. Ad esempio, la tabella seguente mostra che la
somiglianza del secondo ordine tra 'nero' e 'biano' è in primo
luogo determinata da caratteristiche condivise quali 'tuta',
'piazza', etc.
In alcuni casi e per specifici obiettivi può risultare
particolarmente interessante confrontare le reti semantiche di
specifiche parole target ottenute esportando le rispettive
prossimità del primo ordine e similarità del secondo ordine. Ad
esempio, i grafici seguenti sono stati ottenuti esportando file
.gml prodotti da T-LAB e successivamente importati nel software
Gephi (vedi https://gephi.org/
). In entrambi i casi, la parola target è 'cliente', all'interno di
un corpus costituito da una mailing list concernente il commercio
elettronico. Come si può rilevare, nel primo caso ('A' -
associazioni del primo ordine) le relazioni tra i nodi rinviano a
specifici sintagmi quali 'pagamento con bonifico bancario', 'sito
web', 'costi di spedizione', 'tramite carta di credito', etc.;
diversamente, nel secondo caso ('B' - associazioni del secondo
ordine), le relazioni tra i nodi con più elevato scambio sembrano
rinviare a un paradigma di tipo gestionale.
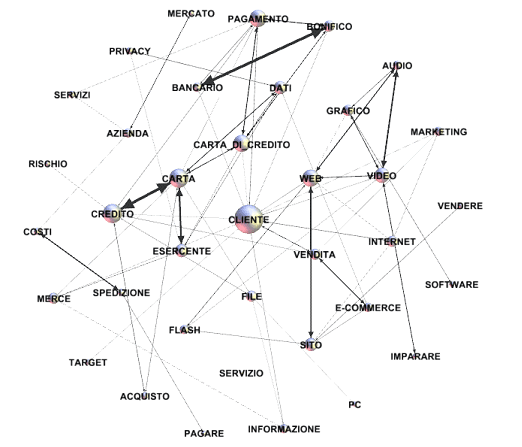
(A) - Associazioni del Primo Ordine
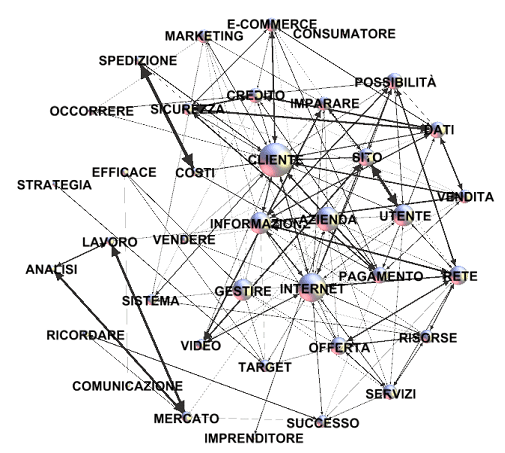
(B) - Associazioni del Secondo Ordine
|


