|
www.tlab.it
Segmentazione delle
parole
Questo strumento T-LAB può essere utilizzato prima di importare
qualsiasi testo (*) cinese o
giapponese che non abbia delimitatori
(cioè spazi e / o segni di punteggiatura) tra le parole.
(*) Il testo da processare può essere costituito da un singolo
documento o da una collezione di documenti che includono variabili
categoriali.
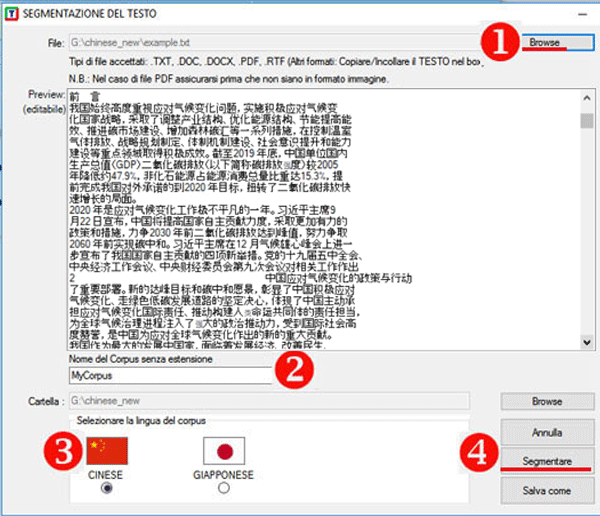
Il suo utilizzo è molto semplice
(vedi immagine seguente):
(1) selezionare un qualsiasi file;
(2) scegliere il nome del progetto;
(3) selezionare la lingua del testo;
(4) cliccare su 'Segmentare'.
Come risultato, verranno aggiunti spazi vuoti tra le parole.
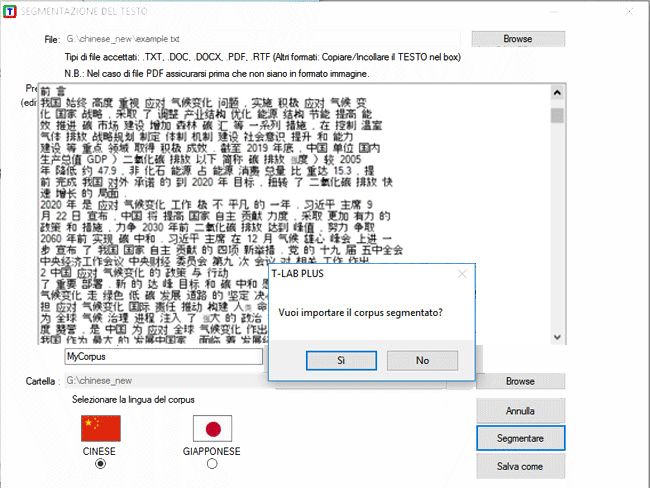
Successivamente, se si vuole
procedere con l' importazione, basta rispondere 'Sì' alla domanda
"Vuoi importare il corpus segmentato?" (vedi immagine
seguente).
N.B.: Quando si desidera preparare
un corpus costituito da vari testi che comprendono le linee di
codifica (cioè variabili categoriali), si consiglia di procedere
nel seguente modo:
1- 'Assemblare' i testi non segmentati (*) mediante lo strumento
Corpus Builder e 'Salvare' il file
corpus;
2 - Importare il corpus appena creato
mediante lo strumento Segmentazione delle Parole; quindi procedere
come spiegato in precedenza.
(*) Ciò significa che, quando si prepara il corpus, non è
necessario segmentare ogni singolo file in anticipo.
|


