|
www.tlab.it
Classificazione di Nuovi
Documenti
N.B .: Questa sezione dell'help è disponibile
solo in inglese.
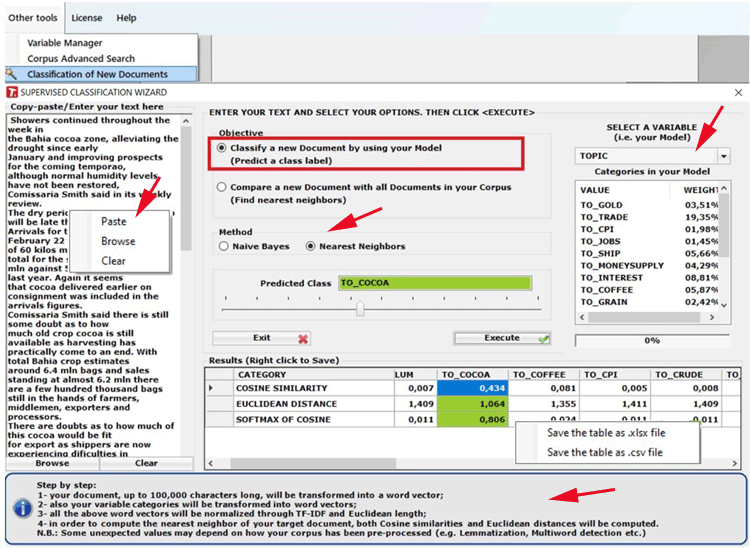
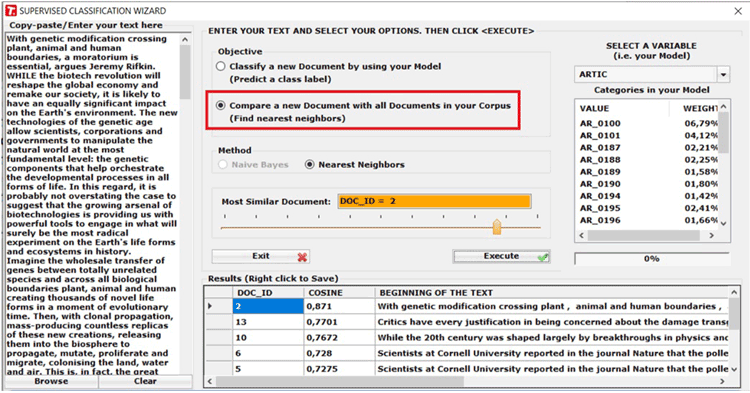
This tool, which is very easy to use, allows one to
easily classify new documents according to a pre-existing model
(i.e. any categorical variable) and also to compare any new
document with all documents included in a corpus already
analysed.
To this purpose, the following steps are required:
- enter a new document in the appropriate box;
- select a categorical variable to be used as a 'model';
- choose the desired 'objective' and a 'method';
- click 'execute'
All results can be exported by using the right click
options (see the below pictures).
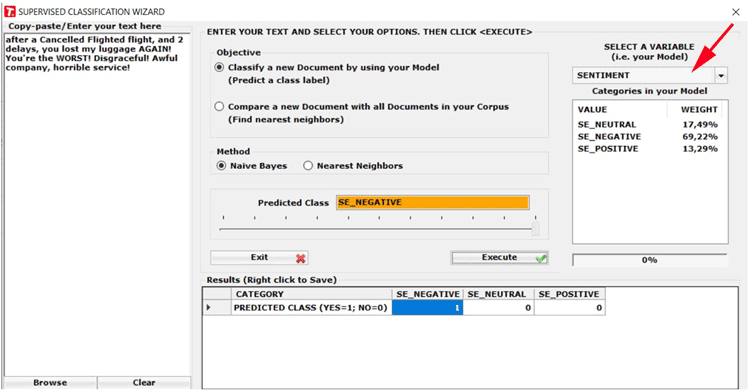
When using this tool for sentiment analysis purpose, your
corpus must include an appropriate categorical variable (see the
below below).
N.B.: When the user wishes to classify a dataset of new
documents by using a supervised method, the dataset must be
imported by T-LAB and then analysed by using a previously generated
dictionary. To this purpose, the Thematic
Document Classification can be used, both for generating a
dictionary of categories (i.e. unsupervised method) and for
performing a supervised classification.
|


