|
Multidimensional Scaling
(MDS)
Insieme di tecniche statistiche che consentono di
analizzare matrici di similarità e di rappresentare le relazioni
tra i dati entro uno spazio di dimensioni ridotte.
In T-LABun tipo di MDS (metodo Sammon) è usato
per rappresentare le relazioni tra unità lessicali o tra nuclei
tematici (vedi Co-Word Analysis e
Modellizzazione dei Temi
Emergenti).
I dati in analisi sono costituiti da matrici
quadrate in cui sono riportati valori di prossimità (dissimilarità)
derivati dal calcolo di un indice di
associazione.
I risultati ottenuti, analogamente a quelli
dell'analisi delle corrispondenze,
consento di interpretare sia le relazioni tra gli "oggetti"
(vicinanza/distanza), sia le dimensioni che organizzano lo spazio
in cui essi sono rappresentati.
La bontà dell'adattamento, cioè il grado di
corrispondenza tra le distanze risultanti dalla mappa MDS e quelle
della matrice input, è misurata dalla funzione di Stress. Minore è il valore di stress (es. <
0.10), maggiore è la bontà dell'adattamento.
La formula dello stress è la seguente:
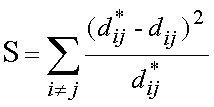
dove 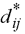 indica le distanze tra i punti (ij) nella matrice
input e indica le distanze tra i punti (ij) nella matrice
input e 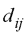 indica le distanze tra gli stessi punti nella mappa MDS.
indica le distanze tra gli stessi punti nella mappa MDS.
|


