|
www.tlab.it
Esportare Tabelle
Personalizzate
 N.B.: Le immagini di questa sezione fanno riferimento a una
versione precedente di T-LAB.
In T-LAB 10 l'aspetto è
leggermente diverso, ma le funzionalità del software sono le
medesime. N.B.: Le immagini di questa sezione fanno riferimento a una
versione precedente di T-LAB.
In T-LAB 10 l'aspetto è
leggermente diverso, ma le funzionalità del software sono le
medesime.
Questa opzione consente di creare, esplorare ed
esportare tre tipi di tabelle:
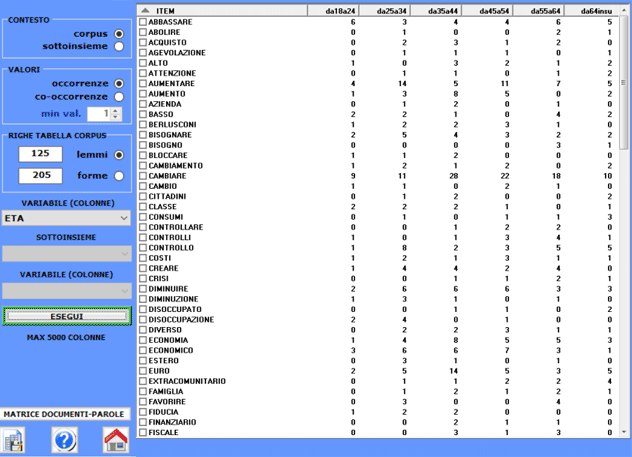
a) quelle con le occorrenze delle varie unità lessicali entro i
sottoinsiemi del corpus definiti da qualche variabile (matrici
rettangolari);
b) quelle con le co-occorrenze delle varie unità lessicali (matrici
quadrate) all'interno del corpus o di suoi sottoinsiemi;
c) quelle con le occorrenze delle varie unità lessicali all'interno
di tutti i documenti (matrici sparse
con gli indici dei vari elementi).
Le dimensione massime di tali tabelle sono
rispettivamente: a) 10.000 righe per 150 colonne; b) 5.000 righe di
5.000 colonne; b) 30.000 documenti per 10.000 unità
lessicali.
L'uso della funzione è molto intuitivo.
Nei casi più semplici, si richiede di selezionare
la variabile le cui modalità costituiranno le colonne della tabella
output.
Nei casi più complessi, si richiede di selezionare
una variabile e un sottoinsieme.
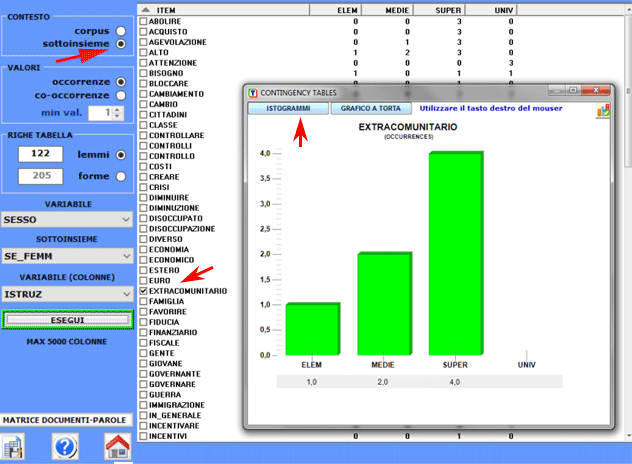
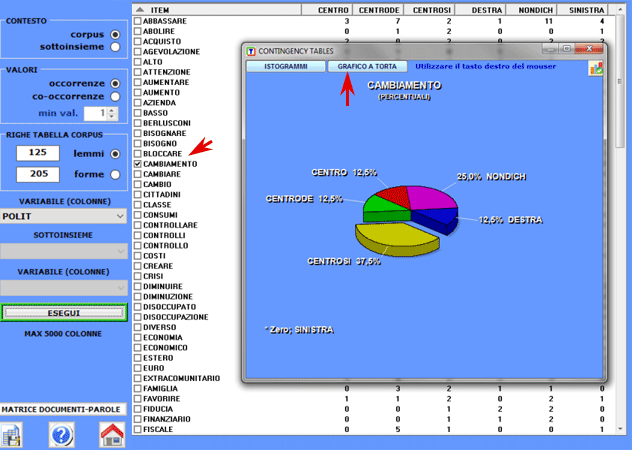
Tutte le tabelle di tipo 'a' e 'b' consentono di
realizzare vari tipi grafici.
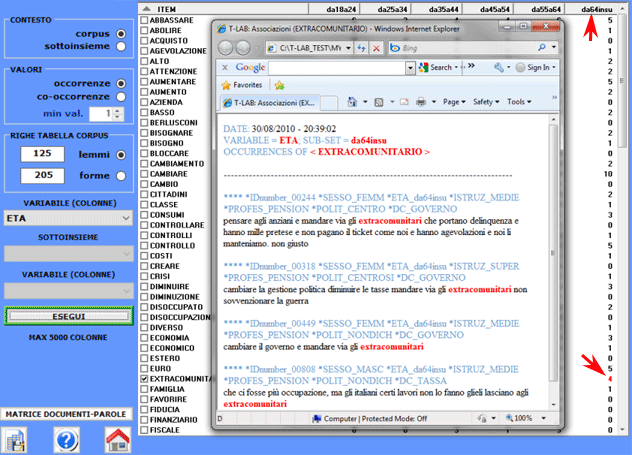
Inoltre, cliccando su specifiche celle, è possibile creare
file HTML con i tutti i contesti
elementari in cui la parola in riga è presente nel sottoinsieme in
colonna (vedi sotto).
Per esportare matrici sparse del tipo documenti per
parole è sufficiente cliccare il pulsante Matrice Documenti-Parole. In questo caso, i tipi
di output sono due:
Il primo (Sparse_Matrix.csv) ha il formato seguente:
Doc_Index; Word_Index; Word_Occ
00001; 1; 12
00001; 2; 5
…..
Il primo (Word_Indexes.csv) ha il formato seguente:
Word_Index; Word_Label
1; abolire
2; acquisto
…..
|


