|
www.tlab.it
Specificità
 N.B.: Le immagini di questa sezione fanno riferimento a una
versione precedente di T-LAB.
In T-LAB 10 l'aspetto è
leggermente diverso. In particolare, a partire dalla versione 2021,
una galleria di immagini ad accesso rapido funziona come un menu
aggiuntivo che permette di passare da un output all'altro con un
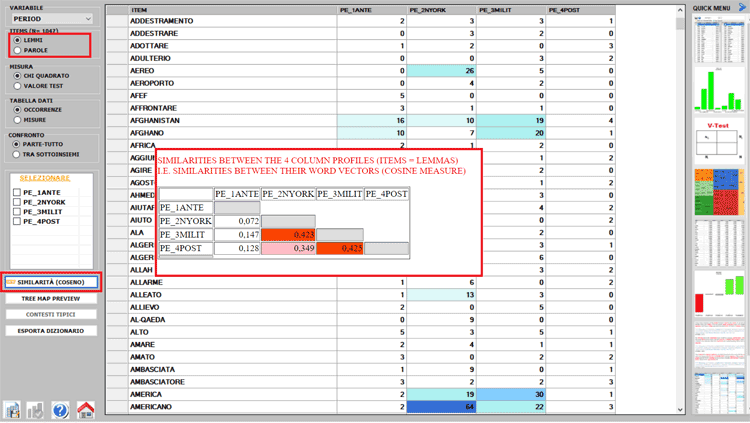
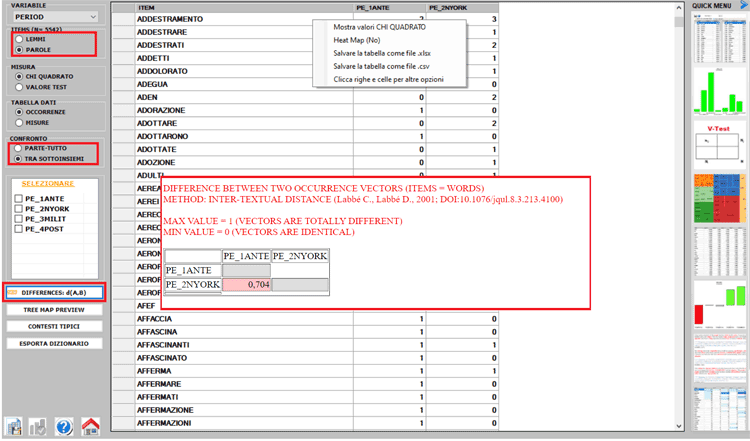
solo clic. Inoltre l'utente può ora valutare facilmente somiglianze
(es.Coseno) e differenze (es.Distanza intertestuale) tra
sottoinsiemi di corpus (da 2 a 150), e quindi anche per rilevare la
presenza di documenti (vedi immagini seguenti).
N.B.: Le immagini di questa sezione fanno riferimento a una
versione precedente di T-LAB.
In T-LAB 10 l'aspetto è
leggermente diverso. In particolare, a partire dalla versione 2021,
una galleria di immagini ad accesso rapido funziona come un menu
aggiuntivo che permette di passare da un output all'altro con un
solo clic. Inoltre l'utente può ora valutare facilmente somiglianze
(es.Coseno) e differenze (es.Distanza intertestuale) tra
sottoinsiemi di corpus (da 2 a 150), e quindi anche per rilevare la
presenza di documenti (vedi immagini seguenti).
Questo strumento T-LAB permette di verificare quali unità
lessicali (cioè parole, lemmi o categorie) sono tipici o esclusivi
in un testo o in un sottoinsieme del
corpus definito da una variabile categoriale; inoltre esso consente
di individuare le unità di contesto caratteristiche dei vari
sottoinsiemi in esame (ad esempio le frasi 'tipiche' che meglio
differenziano i discorsi dei vari leader politici).
Le tipiche unità lessicali,
definite dalla proporzione delle rispettive occorrenze (vale a dire
dal loro sovra/sotto utilizzo), sono individuate tramite il calcolo
chi-quadrato o del valore test.
Le unità di contesto caratteristiche vengono
individuate calcolando e sommando i valori TF-IDF normalizzati assegnati alle parole di cui
ogni frase o paragrafo è costituito.
Per mezzo di questo strumento, analizzando i
profili delle occorrenze corrispondenti a righe e colonne delle
tabelle di contingenza, è possibile effettuare due tipi di
confronti concernenti i profili delle occorrenze:
1- tra una parte (es.
il sottoinsieme "A") e il tutto
(es. l'intero corpus in analisi, "B");
2- tra coppie di
sottoinsiemi del corpus ("A" e "B").
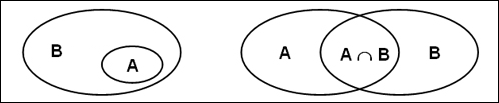
In entrambi i casi possono essere analizzate sia le
Specificità relative alle intersezioni
(parole "tipiche") sia quelle relative alle differenze (parole "esclusive").
Le modalità del calcolo sono illustrate nella
corrispondente voce del glossario.
Le unità lessicali considerate possono essere tutte
(impostazioni automatiche) o solo quelle selezionate
dall'utilizzatore ("impostazioni
personalizzate").
Di seguito vengono illustrati i quattro tipi di confronti
possibili.
1.1 - parte/tutto: unità lessicali "tipiche"
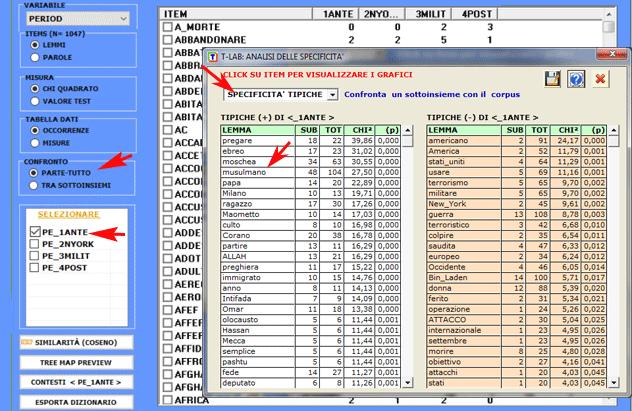
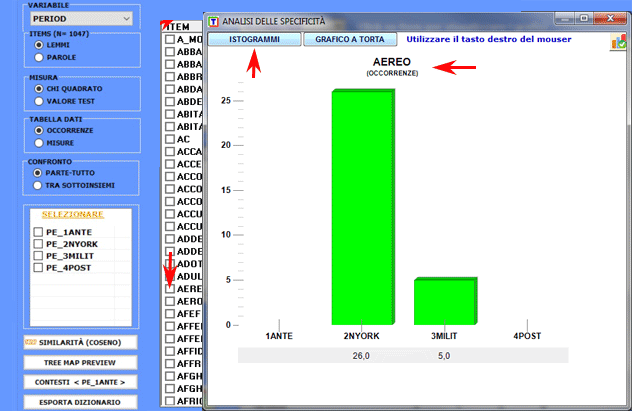
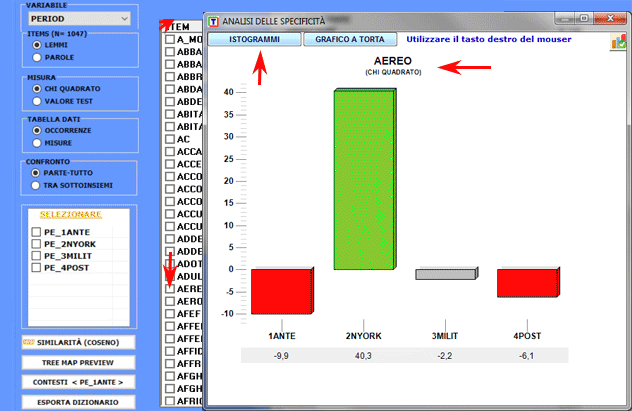
Le chiavi di lettura della tabella sono le
seguenti:
- LEMMA = unità lessicali "tipiche" (per eccesso o per difetto);
- SUB = occorrenze di ogni LEMMA nel sottoinsieme considerato;
- TOT = occorrenze di ogni LEMMA nel corpus o nei due sottoinsiemi
confrontati (vedi punto 2.1);
- CHI2 = valori del CHI
quadro (o VTEST = Valore Test);
- (p) = probabilità associata al
valore del CHI quadro.
Un click sugli item delle tabelle consente di
visualizzare vari tipi di grafici (vedi sotto):
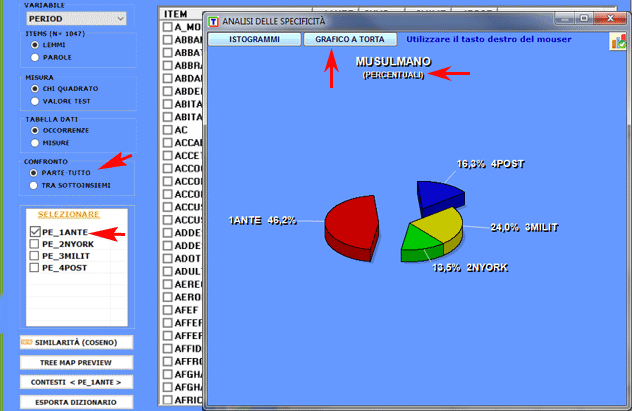
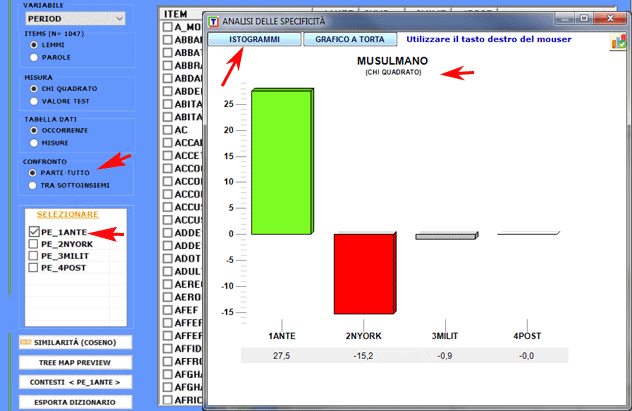
1.2 - parte/tutto: unità lessicali "esclusive"
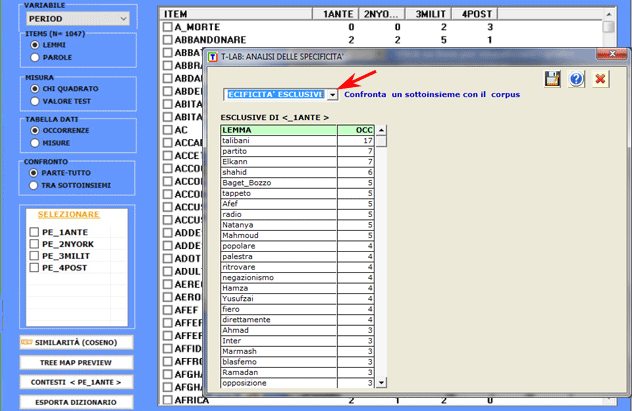
2.1- sottoinsieme/sottoinsieme: unità lessicali
"tipiche"
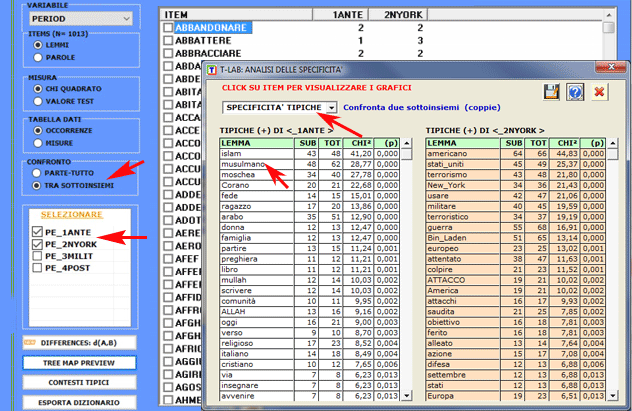
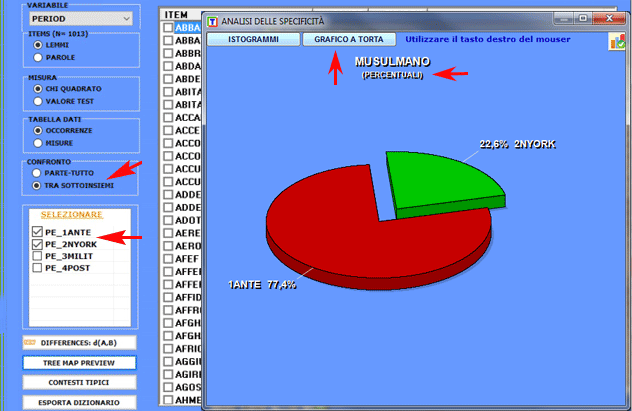
2.2 - sottoinsieme/sottoinsieme: unità lessicali
"esclusive"
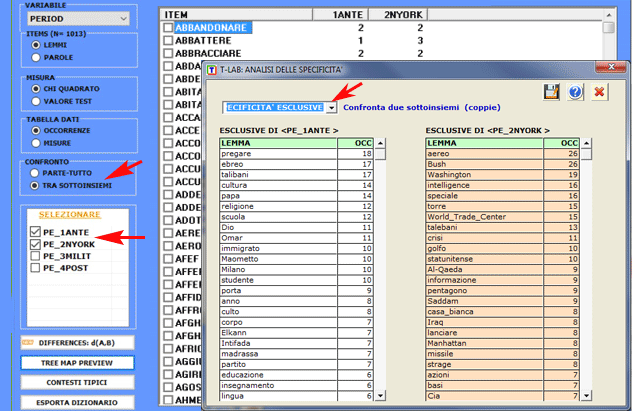
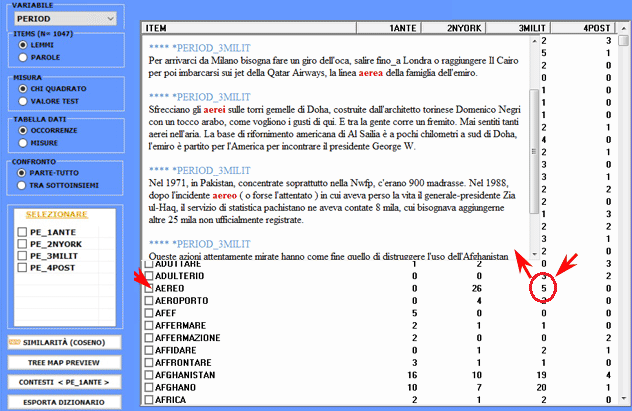
Per ogni sottoinsieme analizzato è anche possibile
verificare i contesti elementari (cioè frasi o paragrafi) che
meglio lo distinguono dagli altri. In questo caso, la 'specificità'
risulta dal calcolo di valori TF-IDF
normalizzati; più in particolare, lo 'score' assegnato a
ciascun contesto elementare (vedi immagine seguente) risulta dalla
somma dei valori TF-IDF assegnati alle parole che lo
compongono.
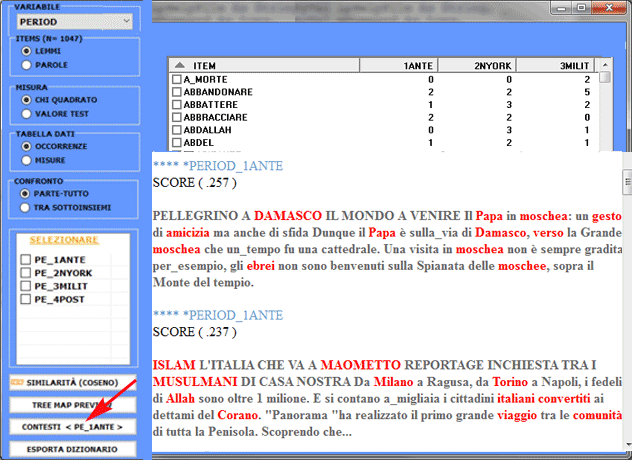
Le tabelle di contingenza utilizzate per i vari confronti
possono essere facilmente esportate ed utilizzate per realizzare
vari tipi grafici.
Inoltre,
cliccando su specifiche celle (vedi sotto), è possibile creare file
HTML con i tutti i contesti elementari in cui la parola in riga è
presente nel sottoinsieme in colonna.
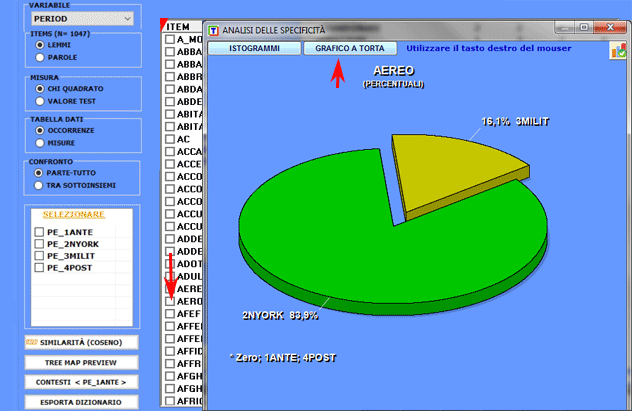
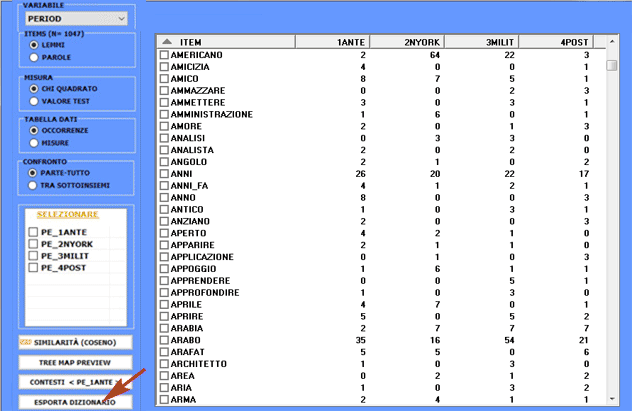
Infine, cliccando l'apposito
pulsante(vedi sotto), viene creato un file dizionario con l'estensione .dictio che è pronto
per essere importato da qualsiasi strumento T-LAB per l'analisi
tematica. Tale dizionario include tutte le parole tipiche
della variabile categoriale selezionata.
|


