|
www.tlab.it
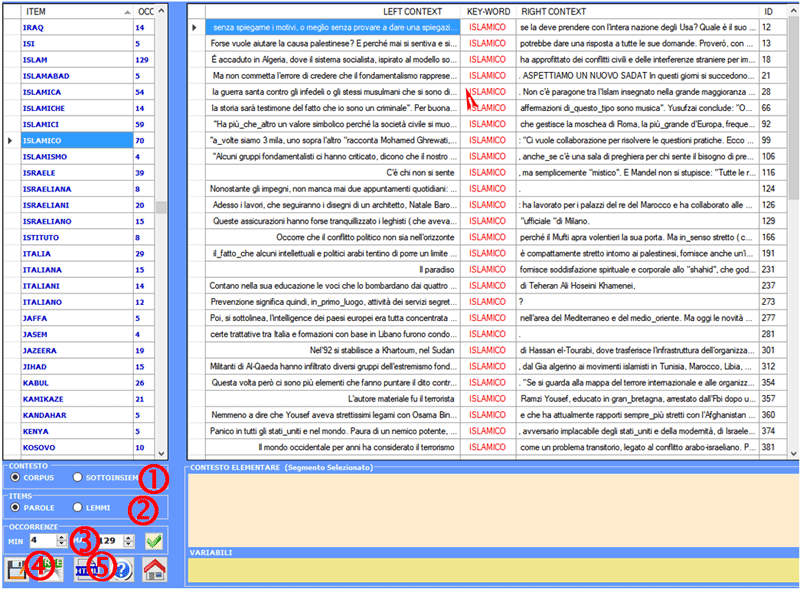
Concordanze
Questo strumento T-LAB ci consente
di verificare i contesti di occorrenza di ogni unità
lessicale.
Le ricerche del tipo KWIC (Key-Word in Context)
possono essere effettuate per forme e
per lemmi (vedi sotto '2'), sia
all'interno dell'intero corpus che
all'interno di un suo sottoinsieme
(vedi sotto '1').
E' inoltre possibile definire il range delle occorrenze
(min e max; vedi sotto '3').
Per ogni unità lessicale, con un semplice click sulla
riga corrispondente, è possibile verificare quali sono i suoi
contesti di occorrenza (i contesti
elementari).
Appositi pulsanti consentono di salvare un file con tutti
i contesti selezionati, sia in formato Word
Tree (vedi sotto '4') che i formato HTML (vedi sotto
'5').
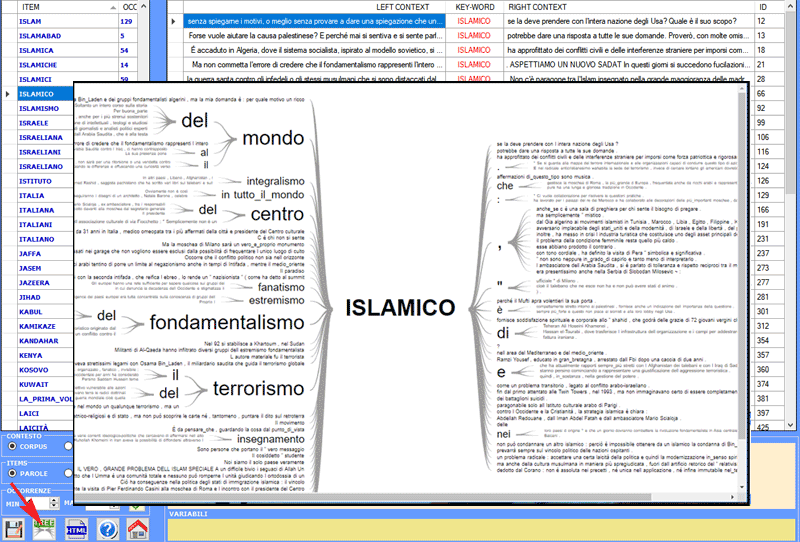

Inoltre, cliccando al centro dei segmenti mostrati
è possibile visualizzare il loro contenuto e verificare le
categorie utilizzate nelle rispettive linee di codifica (vedi
sotto).

|


