|
www.tlab.it
Contesti Chiave di Parole
Tematiche
Questo strumento
T-LAB può essere usato per due
diversi scopi:
A) estrarre insiemi di unità di contesto che permettono
di approfondire il valore tematico di specifiche parole-chiave;
B) estrarre le unità di contesto che risultano le più simili a
testi campione proposti
dall'utilizzatore.
Passo dopo passo, le rispettive procedure sono le
seguenti:
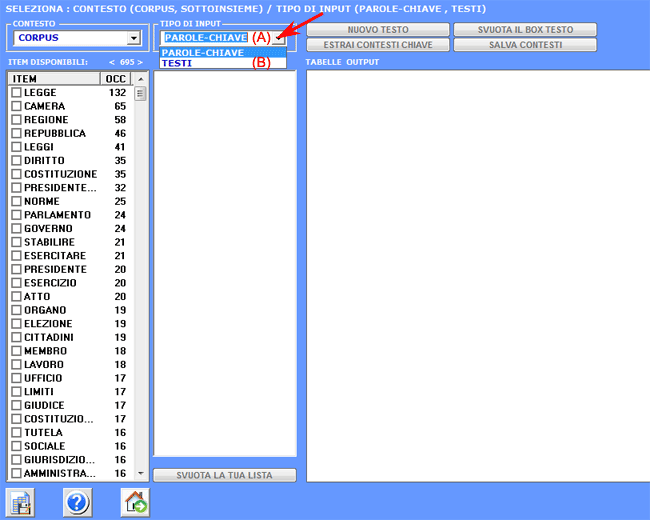
Caso (A)
A differenza della funzione Concordanze, che
consente di estrarre tutti i contesti elementari in cui sono
presenti (occorrenze) le singole parole chiave selezionate , e
della funzione Associazioni di Parole, che consente di
estrarre i contesti elementari in cui le parole chiave selezionate
sono "in coppia" con altre parole (co-occorrenze binarie), questo
strumento consente di estrarre i contesti elementari in cui la
parola selezionata è significativamente associata con un gruppo di
altre parole (co-occorrenze multiple) che definiscono il suo ambito
tematico.
Il suo funzionamento è il seguente:
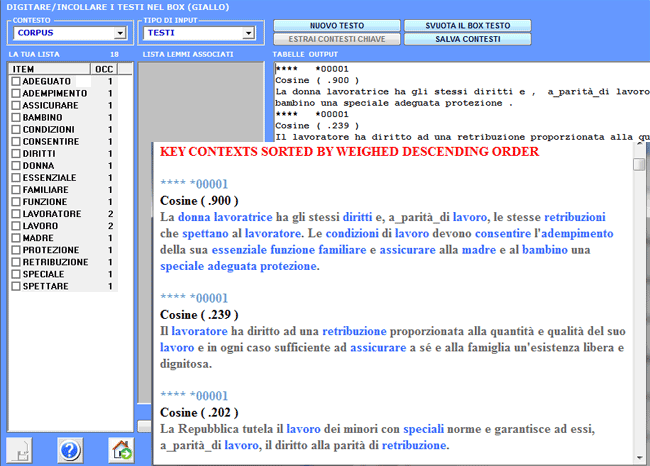
1- l'utilizzatore sceglie
una parola tematica "X" (vedi "lavoro" nell'immagine seguente);
2- T-LAB propone una lista di parole (max. 50)
i cui valori di co-occorrenza con "X" sono i più
significativi;
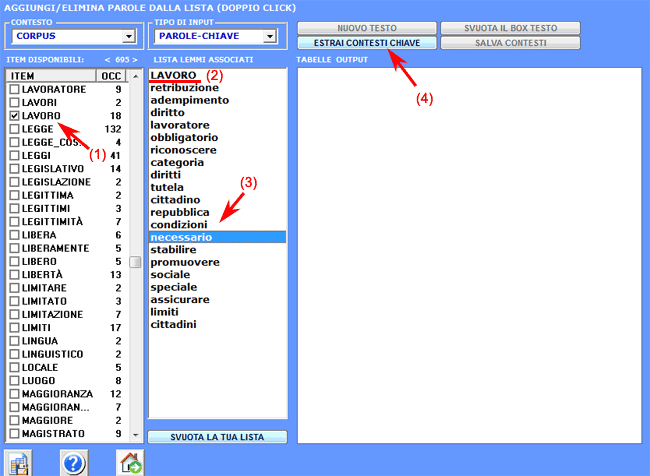
3-
l'utilizzatore può eliminare (doppio click) item irrilevanti dalla
lista proposta;
T-LAB assume la lista come un "query
vector" e calcola i suoi indici di
associazione (coefficiente del coseno) con tutti i contesti
elementari del corpus o del sottoinsieme
selezionato;
4- l'output fornito è una pagina
HTML che contiene una lista dei
più significativi contesti chiave di "X", ordinati per il valore
decrescente dell'indice (vedi sotto);
I passi 1-4 possono essere ripetuti per "n" parole
tematiche.
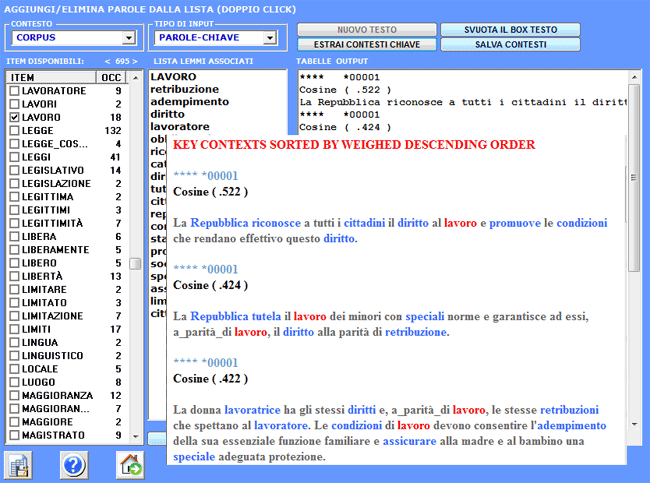
Gli output, sia in formato HTML e TXT, contengono un elenco dei più
significativi contesti chiave di "X", elencati secondo l'ordine
decrescente dei loro indici di associazione
.
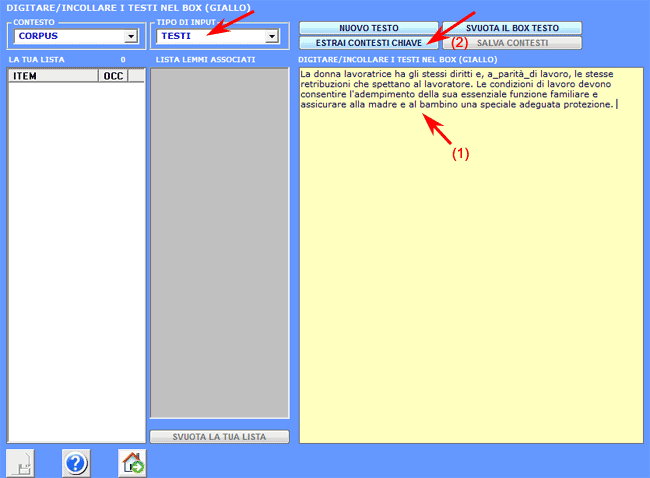
Caso (B)
Il suo funzionamento è modo seguente:
1 - l'utilizzatore copia / incolla un testo 'modello' (max 5000
caratteri) nella casella corrispondente;
2 - dopo aver cliccato l'opzione 'estrai contesti chiave',
T-LAB trasforma il testo
immesso in un vettore (query vector) e calcola i relativi indici di
associazione (cioè i coefficienti coseno) con tutti i contesti
elementari del corpus o del sottoinsieme selezionato.
Gli output, sia in formato HTML e TXT, contengono un
elenco dei contesti chiave che sono più simili al testo in
input.
N.B.: In questo caso la misura di similarità non tiene conto delle
parole multiple le cui stringhe, con o senza il carattere
underscore ('_'), non corrispondono al testo analizzato.
I passi 1-2 possono essere ripetuti per "n" testi campione
proposti dall'utilizzatore.
|


