|
www.tlab.it
Preparare un Corpus (Corpus
Builder)
 N.B.:Le immagini di questa sezione fanno riferimento a una versione
precedente di T-LAB. In
T-LAB 10 questo strumento
include due pulsanti aggiuntivi: a) uno che, per corpus di
dimensioni non superiori a 20 MB, attiva l'opzione Text Screening; b) l'altro che consente di
procedere immediatamente con l'importazione dei materiali testuali selezionati
(vedi immagine seguente).
N.B.:Le immagini di questa sezione fanno riferimento a una versione
precedente di T-LAB. In
T-LAB 10 questo strumento
include due pulsanti aggiuntivi: a) uno che, per corpus di
dimensioni non superiori a 20 MB, attiva l'opzione Text Screening; b) l'altro che consente di
procedere immediatamente con l'importazione dei materiali testuali selezionati
(vedi immagine seguente).

Questo strumento software è stato progettato per
facilitare la preparazione e la trasformazione di vari materiali
testuali in un file corpus pronto per essere importato da
T-LAB.
Più specificamente, tale strumento consente di eseguire
rapidamente le seguenti operazioni:
1. Importare automaticamente
vari tipi di file;
2. Editare e modificare i testi dei
file importati;
3. Gestire l'uso di variabili
categoriali;
4. Salvare il risultato del lavoro in
un file pronto per essere importato da T-LAB;
5. Verificare e modificare qualsiasi file corpus che corrisponda
al formato richiesto da T-LAB.

Mentre il modo di importare i file (vedi sopra '1') varia
in base al loro formato, tutte le altre operazioni seguono la
stessa logica.
Di seguito una breve descrizione dei modi per importare i
vari tipi di file.
A - Importazione di file in
formato tabellare (CSV, .SAV, .JSON, .XML, .XLS, XLSX,
.MDB, .ACCDB).
Un singolo file che includa
fino a 30.000 record può essere importato usando l'opzione 'Open
Table' o tramite il metodo drag and drop (N.B.: quando nessuno dei
testi supera i 2.000 caratteri, il limite dei record da importare è
esteso a 99.999).
Tale file può essere costituito da varie colonne
contenenti i seguenti dati:
- Variabili categoriali (una per ogni
colonna, fino a un massimo di 50)
- Testi da analizzare (una sola
colonna);
- IDnumbers, cioè identificativi di
unità di contesto o di soggetti/casi.
N.B.: Mentre la presenza di variabili categoriali e IDnumbers è
opzionale, la presenza di almeno una colonna contenente i testi da
analizzare è obbligatoria.
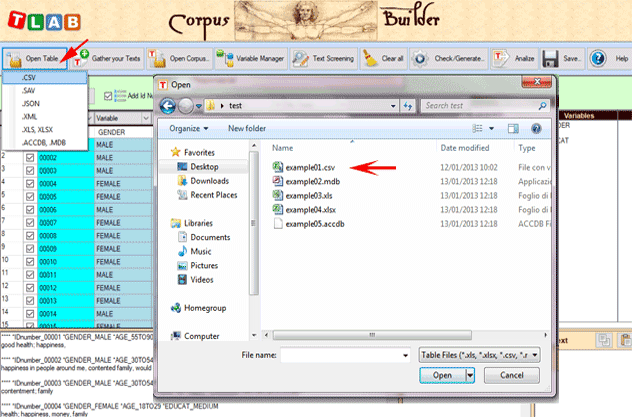
Quando viene importato un file .CSV, deve essere
opportunamente selezionato il delimitatore usato (vedi
sotto).

Quando vengono importati file Excel o Access, è possibile
selezionare solo una tabella (vedi sotto)..

B - Importazione testi e
documenti in vari formati
L'opzione
'Gather your Texts' (vedi sotto) consente di importare fino a
30.000 documenti, sia uno per volta che tramite selezione multipla,
utilizzando tre diversi
metodi.
Il primo metodo ('Add your
Documents') prevede l'importazione automatica di file tipo .TXT,
.DOC, .DOCX, .PDF, .RTF.

Il secondo metodo ('Add
EmptyRecord') consente di aggiungere singoli record in cui è
possibile copiare/incollare qualsiasi tipo di testo (vedi
sotto).


Il terzo metodo ('Import
text from URL) consente di scaricare direttamente singoli file HTML
da internet, di editarne il contenuto per eventuali modifiche e -
quindi - di importarli (vedi sotto).

C - Importazione di un
corpus già codificato secondo le specifiche di
T-LAB.
Si consiglia l'uso dell'opzione 'Open Corpus' in tre tipi
di casi:
1 - l'utilizzatore intende modificare la struttura di un
file corpus già codificato (es. aggiungere degli altri testi
tramite i metodi spiegati nella precedente sezione 'B', modificare
le denominazioni delle variabili e/o delle modalità, etc.);
2 - l'utilizzatore intende verificare/correggere gli eventuali
errori contenuti in una codifica del corpus effettuata manualmente
e senza l'ausilio del modulo Corpus Builder;
3 - l'utilizzatore intende importare un file corpus con una
codifica 'grezza' (vedi immagine seguente), cioè un file corpus le
cui parti (documenti o record) siano tutte precedute solo da una
riga con quattro asterischi seguiti da uno spazio ('****
').

In tutti i tre
casi sopra menzionati (1,2,3) è sufficiente selezionare un singolo
file tramite l'opzione 'Open Corpus' o trascinarlo con il metodo
drag and drop.

Operazioni successive
all'importazione di file
Al termine della fase attraverso la quale i file sono
stati importati in Corpus Builder, sia nel caso in cui 'non' si sia
interessati all'uso di variabili, sia nel caso in cui le operazioni
di codifica siano state già effettuate, si può procedere con
l'opzione 'Check /Generate' e - successivamente - con
l'importazione del corpus in T-LAB.
Quando il corpus contenga codifiche, va tenuto presente
che in tutti e i tre i tipi di importazione menzionati nelle
precedenti sezioni di questo documento ('A', 'B', 'C'), i dati
vengono visualizzati in diverse colonne, le cui intestazioni
possono essere le seguenti:
- Variable, cioè
variabili categoriali, il cui uso è necessario quando si intendano
analizzare le caratteristiche e le relazioni di distinti
sottoinsiemi del corpus;
- IDnumber, cioè identificatori
di casi / record, il cui uso è opzionale;
- My Texts, cioè il testi da
analizzare, il cui uso è possibile in una sola colonna ed è
obbligatorio;
- Exclude, da usarsi per
segnalare a Corpus Builder che i dati contenuti nella
corrispondente colonna non vanno utilizzati.

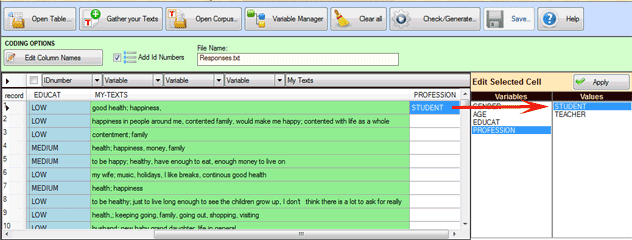
In tutti i casi, valgono le seguenti indicazioni:
- ogni record può essere selezionato o deselezionato (vedi sotto '1
');
- gli IDnumber possono essere aggiunti automaticamente (vedi sotto
'2');
- i nomi delle variabili possono essere editati e modificati (vedi
sotto '3';
- ogni valore di variabile può essere editato e modificato (vedi
sotto '4');
- ogni campo 'My Texts' può essere editato e modificato (vedi sotto
'5').

Si ricorda inoltre che:
- Il numero delle colonne con variabili categoriali non
deve superare i 50, e ciascuna di esse deve avere minimo 2 massimo
150 valori;
- I valori degli IDnumber, se usati, devono essere progressivi a
partire da 1 (es., 1, 2, 3, etc.);
- Ogni etichetta, sia nel caso delle variabili che delle modalità,
non deve superare la lunghezza di 25 caratteri alfanumerici (min.
2) e non deve essere intervallata da spazi vuoti;
- Nel modulo Corpus Builder tutti gli errori rilevati vengono
visualizzati nel box in basso a sinistra (vedi sotto).

Uso dello strumento Variable
Manager
Lo strumento 'Variable Manager' consente di costruire,
editare, modificare e salvare qualsiasi schema di codifica, anche
proveniente da un corpus diverso.
Ogni schema include l'elenco delle variabili e quello dei
rispettivi valori (vedi sotto).

Per aggiungere variabili provenienti da un altro corpus o
da uno schema precedentemente salvato, bisogna selezionare
l'opzione '1' (vedi sopra). Diversamente, per aggiungere
manualmente variabili e relativi valori, bisogna usare in sequenza
l'opzione '2' e l'opzione '3' (vedi sopra).
L'aggiunta di valori di variabili a singoli record va
effettuata manualmente (vedi sotto) e in un'unica sessione di
lavoro; questo perché il salvataggio dello schema non include le
codifiche attribuite a ciascun record. Nel caso quindi
l'utilizzatore si trovi a codificare manualmente un corpus che
includa un numero considerevole di record e/o il lavoro richieda
più di una sessione di lavoro, si raccomanda di procedere come
segue:
1 - importare la quantità di file/record che si ritiene
di poter codificare in un'unica sessione di lavoro;
2 - salvare il lavoro come un corpus (vedi opzione 'Save' del menu
Corpus Builder).
Quindi, nella successiva sessione, reimportare il corpus
salvato in precedenza (vedi sopra, punto '2'), aggiungere altri
record/file da codificare e continuare.
Quando l'utilizzatore ha completato le operazioni che
ritiene opportune, l'opzione 'Check/Generate' consente di
verificare la loro correttezza e, se tutto è ok, è possibile
esportare (A) o salvare (B) un corpus pronto per essere importato
da T-LAB.
Nel primo caso (A - vedi sotto) Corpus Builder crea una
nuova cartella nella directory '..\Miei Documenti\T-LAB PLUS\" e -
automaticamente - avvia la procedura di importazione
T-LAB.
N.B.: In questo caso, la nuova cartella che viene creata
ha lo stesso nome del file corpus.
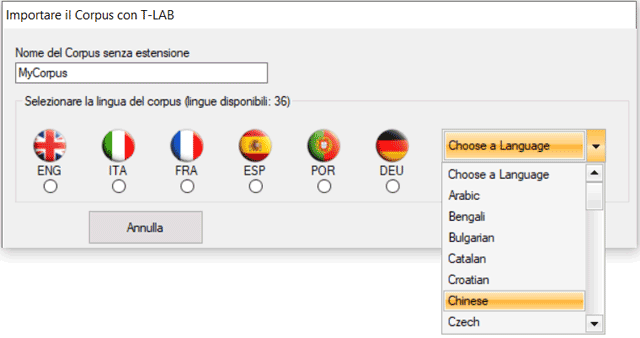
Nel secondo caso (B - vedi sotto) l'utilizzatore può
salvare il corpus nella directory che preferisce e -
successivamente - usare l'opzione 'Importa un corpus' del
menu T-LAB.
N.B.: In questo caso, si raccomanda di creare - ogni
volta - una nuova cartella di lavoro con al suo interno il solo
file corpus da importare.

|


