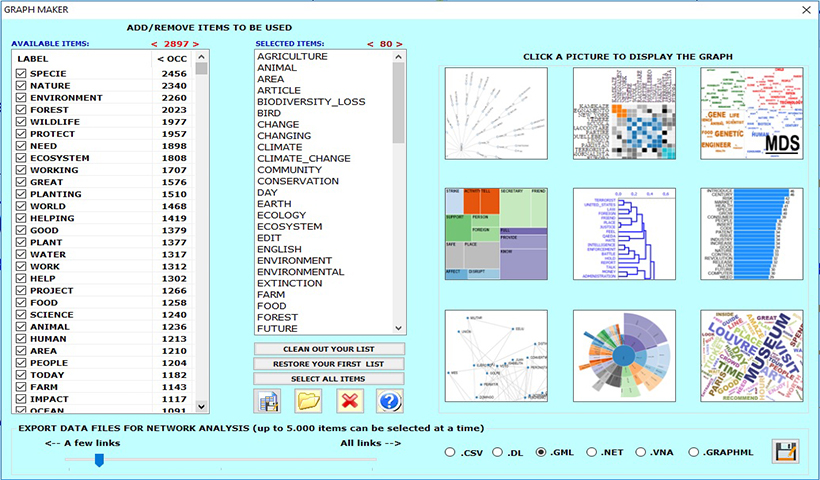
T-LAB offre un milieu logiciel pour l'analyse du contenu et le text mining qui se distingue pour être un des plus complets, flexibles, transparents et faciles à utiliser.
Quoi?

T-LAB offre un milieu logiciel pour l'analyse du contenu et le text mining qui se distingue pour être un des plus complets, flexibles, transparents et faciles à utiliser.
Les textes à analyser peuvent être des plus variés: transcriptions d'entrevues, articles de journaux, réponses aux questions ouvertes, messages Twitter, documents téléchargés par Internet, textes législatifs, livres, etc.
En phase d'importation, les formats des documents et des tableaux supportés sont les suivants: .txt, .doc, .docx, .pdf, .rtf, .html, .xls, .xlsx, .csv, .mdb, .accdb, .sav, .json, .xml.
Il est possible d' analyser des textes dans toutes les langues, y comprises celles qui font usage d 'idéogrammes.
Cliquez ici pour découvrir ce que fait T-LAB et ce que T-LAB vous permet de faire.
Qui?
T-LAB est utilisé dans plus de quarante pays au monde et il est très apprécié aussi bien par les chercheurs d' importantes universités que par des professionnels qui opèrent en plusieurs secteurs.
Il s'agit de sociologues, psychologues, antropologues, consultants en marketing, politologues, économistes, cadres de l'administration publique, linguistes, historiens, psychiatres, philosophes etc.
Cliquez ici pour voir la liste des utilisateurs et la bibliographie.
Pourquoi?
T-LAB utilise un genre d'analyse automatique qui extrait rapidement des patterns constitués par des mots et des sujets significatifs.
La structure de T-LAB stimule la curiosité du chercheur, l'intrigue avec les transformations circulaires des données et l'aide à construire des interprétations.
Les processus du logiciel sont tous transparents et peuvent être facilement personnalisés.
La gamme des outils disponibles est large et flexible.
Les tableaux et les graphiques sont en format interactif et ils peuvent être exportés en différents formats.
L'interface utilisateur, l'aide du logiciel et le manuel sont dans quatre langues: Anglais, Espagnol, Français, Italien.
Comment?
Une fois que le texte ait été traité, T-LAB dispose d'une base des données avec des renseignements détaillés concernants les mots, les phrases et les documents y présents.
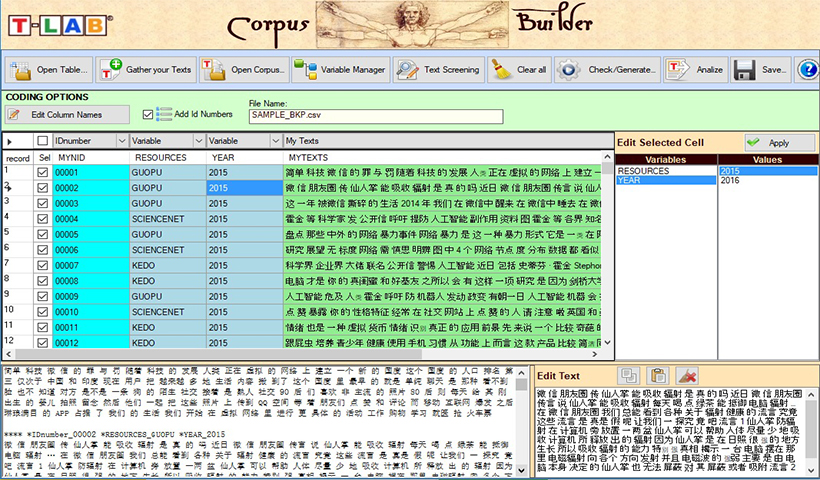
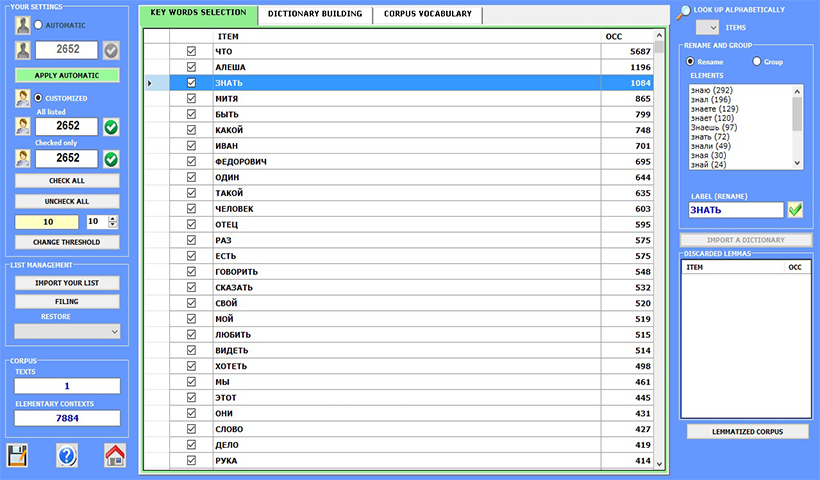
Pendant la phase d'importation du corpus, T-LAB effectue les traitements suivants: normalisation du texte, détection des multi-words et des stop-words, segmentation en contextes élémentaires, lemmatisation automatique ou stemming, sélection des mots-clés.
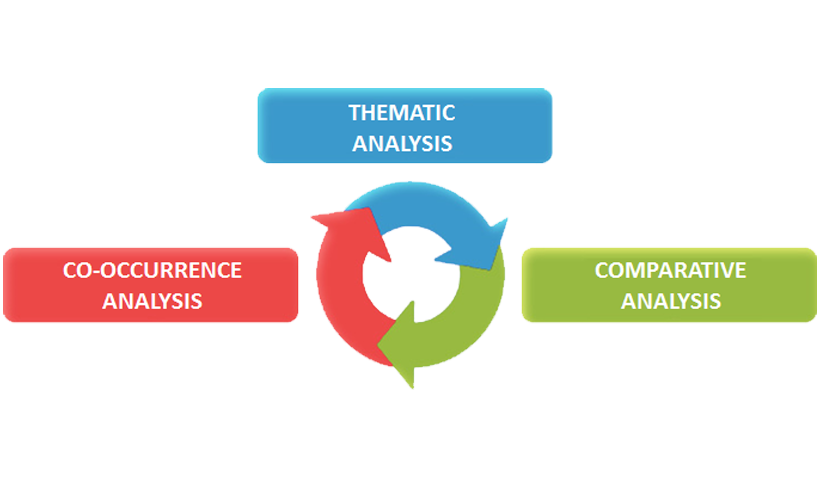
De suite trois sous-menus permettent l'accès à plusieurs outils d'analyse.
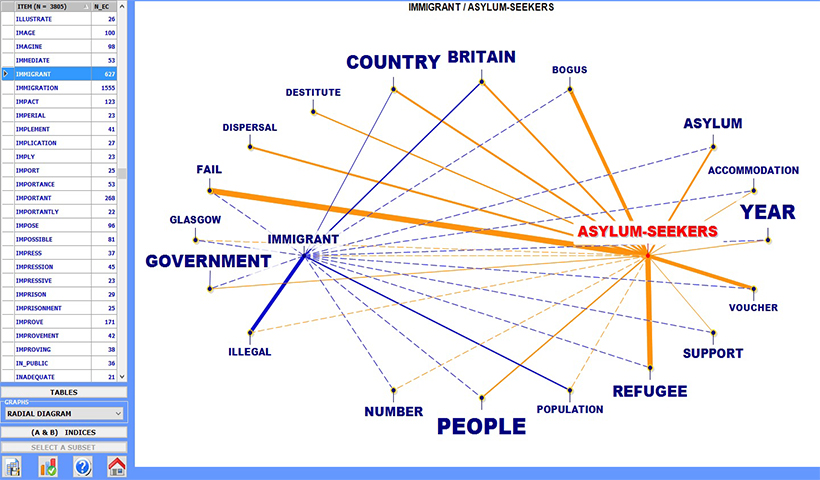
Les outils pour l'analyse des co-occurrences permettent d' explorer, de mesurer et de cartographier différents types de relations entre les mots-clés, soit en couples qu' en groupe, aussi bien à l' intérieur de tout le corpus qu' à l' intérieur de ses sous-ensembles (par exemple articles de journal appartenants au même journal, interviews avec des gens appartenants à la même catégorie démographique, etc...)
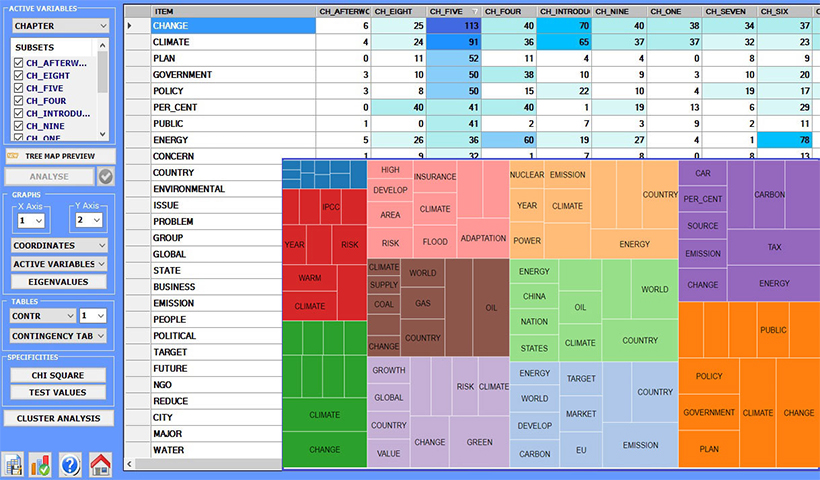
Les outils pour les analyses thématiques sont en grande mesure orientés à la recherche de patterns de mots-clés à l' intérieur des unités de contexte. En réalité, la façon dont T-LAB permet de gérer l' analyse thématique est plutôt sophistiquée. En effet, toutes les unités d' analyse (c' est-à-dire les mots,les segments de texte et les documents) peuvent être clustérisées soit à travers une approche bottom-up, soit par une approche top-down.
Les outils pour les analyses comparatives permettent d' analyser et de topogrammer des ressemblances et des différences entre les divers sous-ensembles du corpus, chacun desquels a un profil lexical déterminé par les mots-clés présents en son interne (occurrences). Aussi bien les ressemblances que les différences peuvent être explorées en comparant chaque sous-ensemble ou groupes de sous-ensemble.
Cliquez ici pour voir un exemple descriptif.
T-LAB a été conçu pour les systèmes d'exploitation Windows (Windows 7, 8, 10, 11).
L'interface utilisateur, l'aide du logiciel et le manuel sont dans quatre langues: Anglais, Espagnol, Français, Italien.
Les utilisateurs MAC intéressés à utiliser T-LAB doivent avoir Microsoft Windows activé sur leur ordinateur.
Le tableau suivant résume les principales caractéristiques du logiciel T-LAB.
Textes dans toutes les langues, inclues celles qui utilisent des idéogrammes
(fichiers au format UTF-8).
Dimension maximale d'un fichier corpus:90 MB, correspondant à environ 55.000 pages au format texte.
Formats de documents qui peuvent être traités: .txt, .doc, .docx, .pdf, .rtf, .html, .xls, .xlsx, .csv, .mdb, .accdb, .sav, .json, .xml (N.B. Les fichiers PDF seule image doivent d'abord être convertis avec un logiciel OCR)
Langues pour les quelles la LEMMATISATION est supportée:
Allemand, Anglais, Catalan, Croate, Espagnol, Français, Italien, Latin, Polonais, Portugais, Roumain, Russe, Serbe, Slovaque, Suédois, Ukrainien.
Langues pour les quelles le STEMMING est supporté:
Arabe, Bengali, Bulgare, Danois, Finnois, Grec, Hindi, Hollandais, Hongrois, Indonésien, Marathe, Norvégien, Perse, Tchèque, Turc
Au cours de la phase d'importation, T-LAB effectue une segmentation de corpus pour le calcul des co-occurrences. Selon les choix de l'utilisateur, les segments de texte (i.e. c'est-à-dire les contextes élémentaires) peuvent être de quatre types: 1) Énoncés; 2) Fragments; 3) Paragraphes; 4) Textes Courts (par exemple, Tweets)
Textes et documents peuvent être analysés et comparés en utilisant des variables catégoriques définies par l'utilisateur. Le nombre de variables disponibles est fixé à 50, chacune d'entre elles permet une subdivision du corpus jusqu'à 150 parties comparables entre elles.