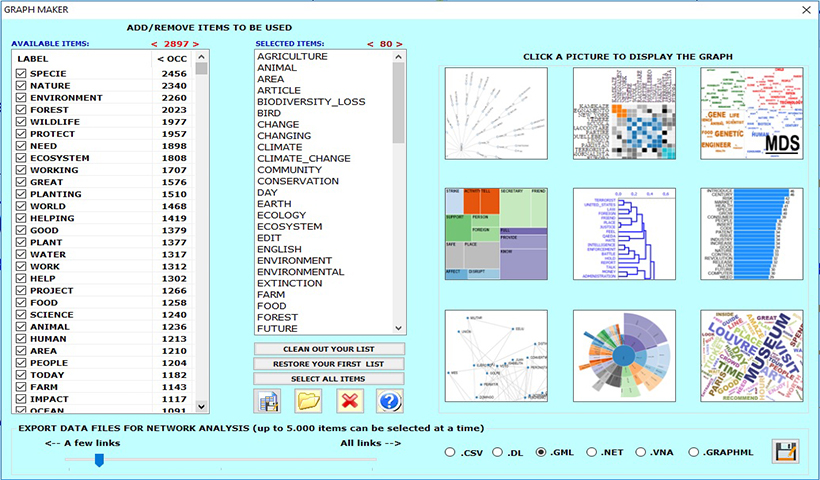
T-LAB offre un ambiente software per l'analisi del contenuto e il text mining che si distingue per essere uno dei più completi, flessibili, trasparenti e facili da utilizzare.
Cosa?

T-LAB offre un ambiente software per l'analisi del contenuto e il text mining che si distingue per essere uno dei più completi, flessibili, trasparenti e facili da utilizzare.
I testi analizzabili possono essere i più vari: articoli di giornali, trascrizioni di interviste e discorsi, risposte a domande aperte, messaggi Twitter, documenti aziendali, materiali scaricati da Internet, testi legislativi, libri, etc.
Nella fase di importazione, i formati di documenti e tabelle supportati sono i seguenti: .txt, .doc, .docx, .pdf, .rtf, .html, .xls, .xlsx, .csv, .mdb, .accdb, .sav, .json, .xml.
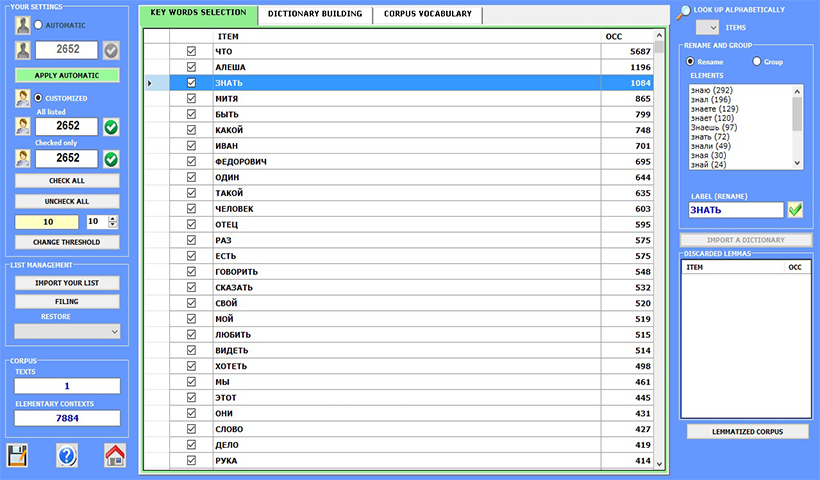
È possibile analizzare testi in tutte le lingue, comprese quelle che fanno uso di ideogrammi. L'intero corpus e i suoi sottoinsiemi possono essere analizzati utilizzando liste di parole chiave facilmente personalizzabili.
Clicca qui per scoprire cosa fa T-LAB e cosa T-LAB ti consente di fare.
Chi?
T-LAB è utilizzato in più di quaranta paesi del mondo, ed è molto apprezzato sia da ricercatori attivi in importanti università che da professionisti che operano in vari settori.
Gli utilizzatori sono sociologi, psicologi, antropologi, consulenti di marketing, politologi, managers di pubbliche amministrazioni, economisti, linguisti, storici, psichiatri, filosofi etc.
Per saperne di più: lista degli utilizzatori e bibliografia.
Perché?
T-LAB usa un tipo di analisi automatica che estrae rapidamente pattern costituiti da parole e temi significativi.
L'architettura di T-LAB stimola la curiosità del ricercatore, lo intriga con le trasformazioni circolari dei dati e lo aiuta a costruire interpretazioni.
Tutti i processi sono trasparenti e possono essere agevolmente personalizzati.
I dati possono essere analizzati mediante vari metodi e utilizzando varie misure.
Tabelle e grafici sono in formato interattivo e possono essere esportati in vari formati.
L'interfaccia, l'help contestuale e il manuale sono in quattro lingue: Inglese, Italiano, Francese e Spagnolo.
Come?
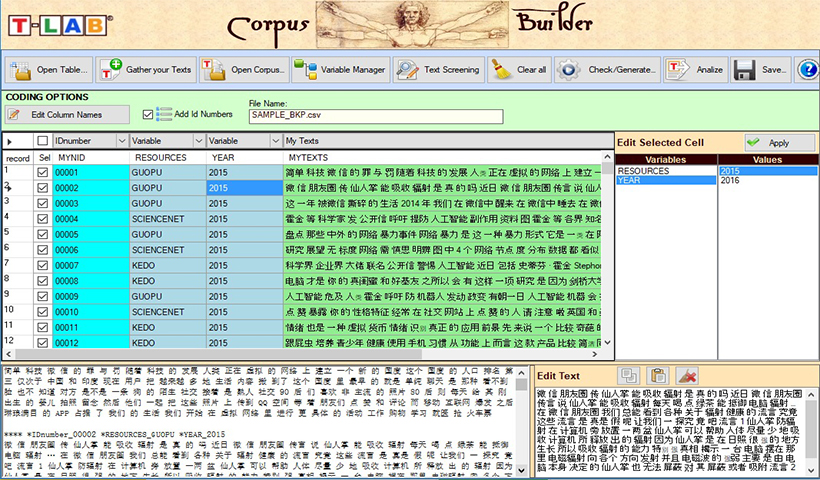
Dopo che il testo è stato processato, T-LAB dispone di un archivio con dettagliate informazioni concernenti le parole, le frasi e i documenti in esso presenti.
Nella fase di pre-processing T-LAB realizza i seguenti trattamenti automatici: normalizzazione del corpus, riconoscimento di stop-word e multi-word, segmentazione in contesti elementari, lemmatizzazione automatica o stemming, selezione delle parole chiave.
Successivamente, tre tipi di strumenti consentono vari tipi di esplorazione e di analisi.
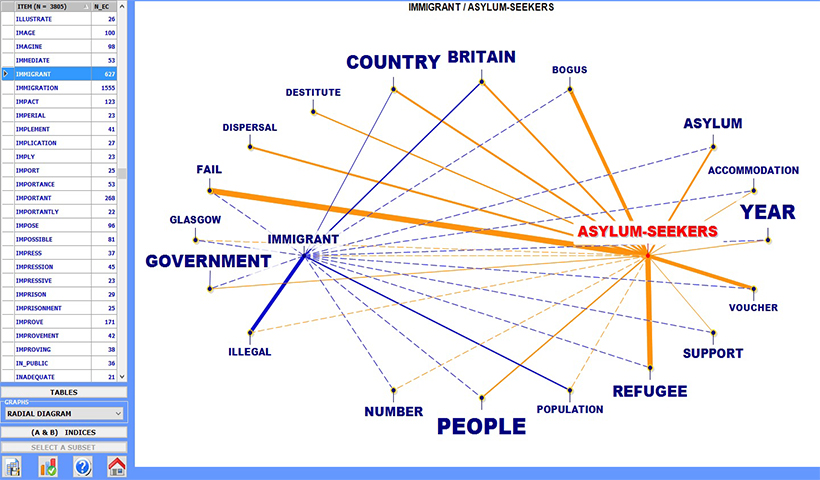
Gli strumenti per l'analisi delle co-occurrenze permettono di esplorare, misurare e mappare vari tipi di relazioni tra le parole-chiave, sia in coppie che in gruppo, sia all'interno di tutto il corpus sia all'interno dei suoi sottoinsiemi (es. articoli di giornale appartenenti alla stessa testata, interviste con persone appartenenti alla stessa categoria demografica, etc.).
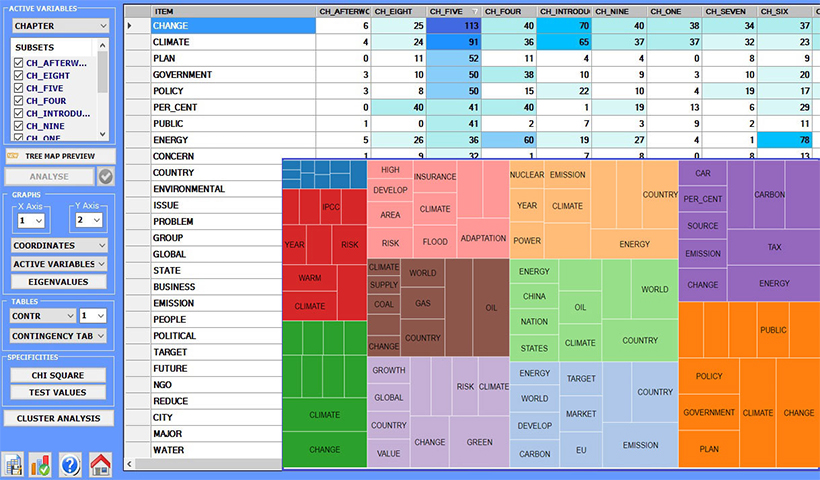
Gli strumenti per le analisi tematiche sono in gran parte orientati alla ricerca di pattern di parole-chiave all'interno delle unità di contesto. In realtà il modo in cui T-LAB permette di gestire l'analisi tematica è piuttosto sofisticato. Infatti tutte le unità di analisi (cioè parole, segmenti di testo e documenti) possono essere clusterizzate sia tramite un approccio bottom-up che tramite un approccio top-down.
Gli strumenti per le analisi comparative permettono di analizzare e mappare somiglianze e differenze tra i vari sottoinsiemi del corpus, ognuno dei quali ha uno profilo lessicale determinato dalle parole-chiave che sono in esso presenti (occorrenze). Sia le somiglianze che le differenze possono essere esplorate confrontando singoli sottoinsiemi o gruppi di essi.
Clicca qui per consultare un esempio descrittivo.
T-LAB è stato progettato per gli ambienti Windows (7, 8, 10, 11).
L'interfaccia, l'help contestuale e il manuale sono in quattro lingue: Inglese, Italiano, Francese e Spagnolo.
Gli utenti MAC interessati ad usare T-LAB devono avere Microsoft Windows attivo sul loro computer.
La tabella seguente riassume le principali caratteristiche del software T-LAB.
Testi in tutte le lingue, incluse quelle che usano ideogrammi
(file in formato UTF-8).
Dimensione massima di un file corpus: 90 MB, corrispondenti a circa 55.000 pagine in formato testo
Tipi di documenti che possono essere elaborati .txt, .doc, .docx, .pdf, .rtf, .html, .xls, .xlsx, .csv, .mdb, .accdb, .sav, .json, .xml (N.B. I file PDF di sole immagini devono prima essere elaborati utilizzando un software OCR)
Lingue per le quali è supportata la LEMMATIZZAZIONE:
Catalano, Croato, Francese, Inglese, Italiano, Latino, Polacco, Portoghese, Rumeno, Russo, Serbo, Slovacco, Spagnolo, Svedese, Tedesco, Ucraino.
Lingue per le quali è supportato lo STEMMING:
Arabo, Bengali, Bulgaro, Ceco, Danese, Finlandese, Greco, Hindi, Indonesiano, Marathi, Norvegese, Olandese, Persiano, Turco, Ungherese.
Durante la fase di importazione, T-LAB esegue una segmentazione di corpus per il calcolo delle co-occorrenze. Secondo le scelte dell'utente, i segmenti di testo (vale a dire i contesti elementari) possono essere di quattro tipi: 1) Frasi; 2) Frammenti; 3) Paragrafi; 4) Testi Brevi (ad esempio, Tweet, risposte a domande aperte etc.)
Testi e documenti possono essere analizzati e confrontati tramite l'uso di variabili categoriali definite dall'utilizzatore. Il numero delle variabili disponibili è fissato a 50, e ciascuna di esse consente una suddivisione del corpus fino a 150 parti confrontabili tra loro.