|
|
T-LAB 10.2 - HELP ON-LINE |
|
|
www.tlab.it
T-LAB: cosa fa e cosa consente di fare T-LAB è un software costituito da un insieme di strumenti linguistici, statistici e grafici per l'analisi dei testi che possono essere utilizzati nelle seguenti pratiche di ricerca: Analisi di Contenuto, Sentiment Analysis, Analisi Semantica, Analisi Tematica, Text Mining, Perceptual Mapping, Analisi del Discorso, Network Text Analysis, Document Clustering, Text Summarization.
In effetti, tramite gli strumenti T-LAB i ricercatori possono gestire agevolmente attività di analisi come le seguenti: - esplorare, misurare e mappare la relazioni di co-occorrenza tra parole-chiave; L'interfaccia del software è particolarmente
user friendly e i testi analizzabili
possono essere i più vari: Tutti i testi possono essere codificati con
variabili categoriali e/o con un
identificativo (Unique Identifier)
che corrisponde a unità di contesto o a casi (es. risposte a
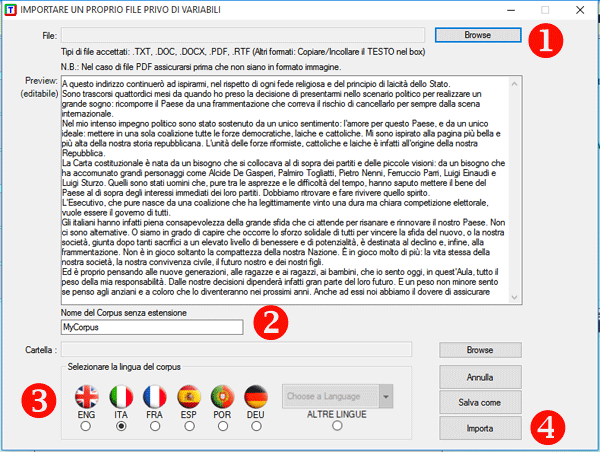
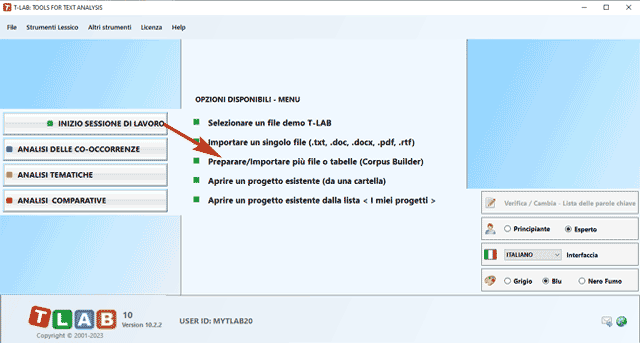
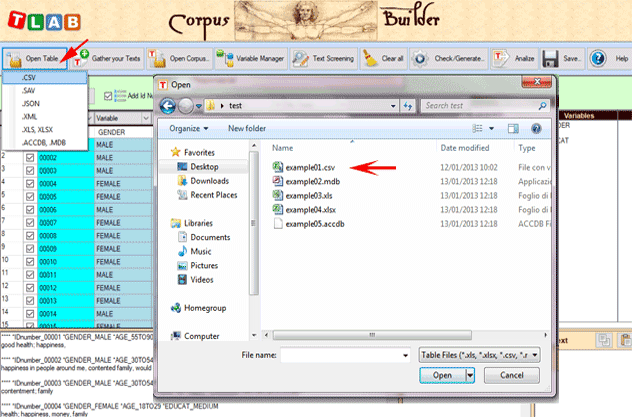
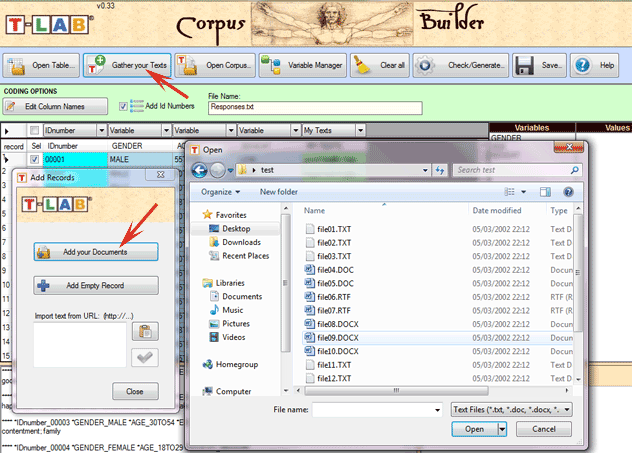
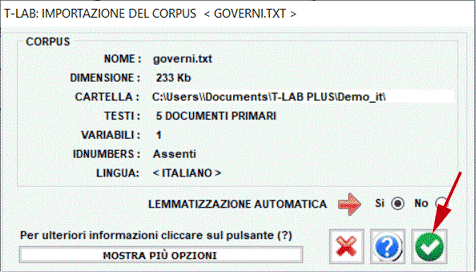
domande aperte, messaggi Twitter, etc.). Nel caso di un singolo documento (o di un corpus trattato come unico testo) T-LAB non richiede ulteriori accorgimenti: basta selezionare l'opzione 'Importare un singolo file ...' e procedere (vedi sotto).
Diversamente, negli altri casi va usato il modulo Corpus Builder (vedi sotto) che - in modo automatico - facilita la trasformazione di vari tipi di materiali testuali e vari tipi di file (undici diversi formati) in un corpus pronto per essere importato da T-LAB.
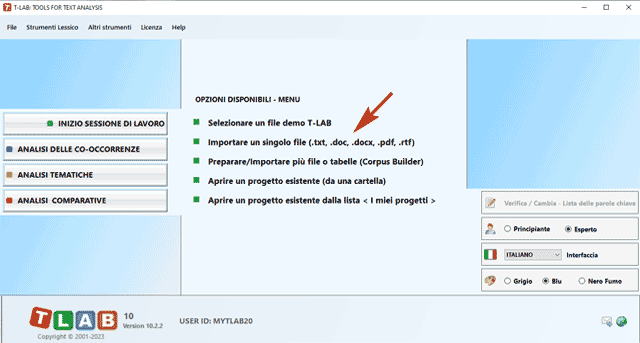
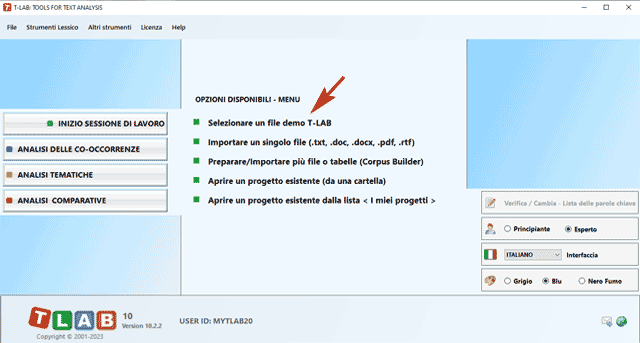
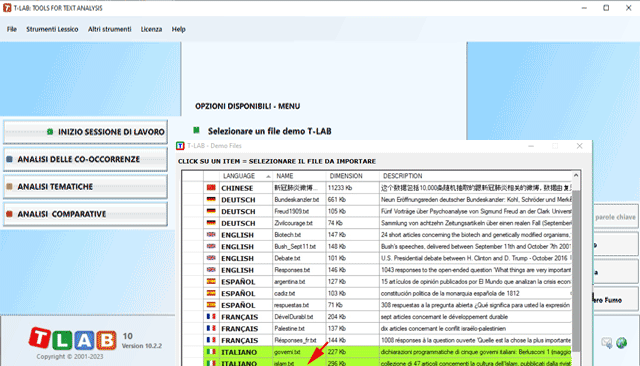
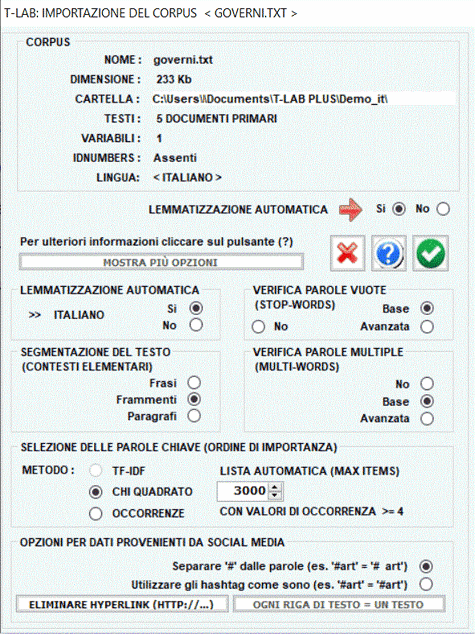
N.B.: Al momento - per garantire l'uso integrato dei vari strumenti - ogni file/corpus da analizzare non dovrebbe superare i 90 Mb (cioè circa 55.000 pagine in formato ASCII). Per ulteriori informazioni, vedere la sezione Requisiti e Prestazioni dell'Help / Manuale. Per verificare rapidamente le funzionalità del software sono sufficienti i seguenti passi: 1 - Selezionare l'opzione 'Selezionare un file demo T-LAB'
2 - Selezionare un corpus da analizzare
3 - Cliccare su "ok" nella prima finestra di Setup
4 - Scegliere uno strumento all'interno di uno dei sub-menu "Analisi"
5 - Verificare i risultati
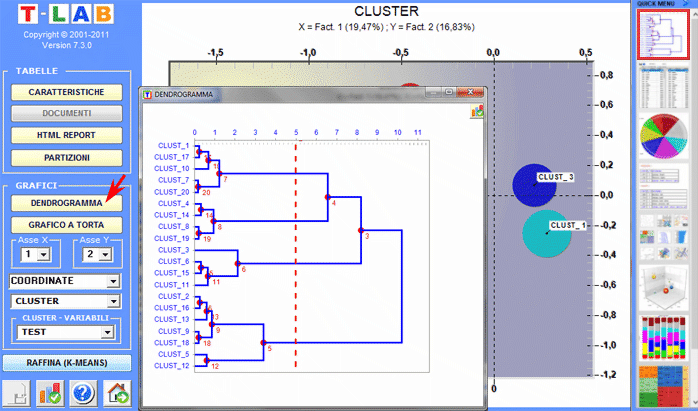
6 - Utilizzare l'help contestuale per interpretare grafici e tabelle
Di seguito vengono fornite le informazioni essenziali per capire cosa T-LAB fa e come può essere usato. Dal punto di vista esterno, l'uso del software è organizzato dall'interfaccia, cioè dal menu principale, dai sub-menu e dalle funzioni (strumenti) che li compongono. Da un punto di vista logico, oltre che dall'interfaccia utente, il sistema T-LAB è organizzato da due componenti principali:
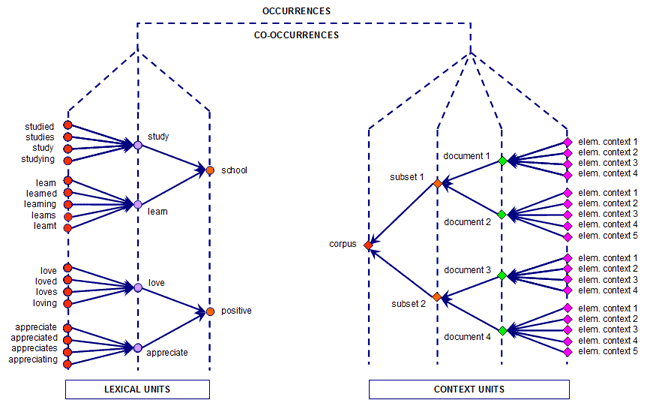
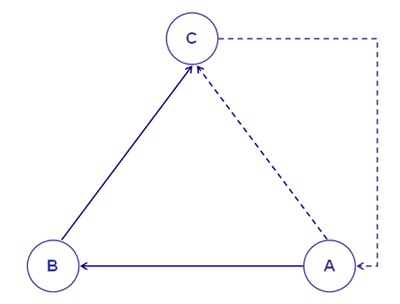
Per capire come T-LAB funziona e come può essere usato, è di fondamentale importanza aver chiaro quali unità di analisi sono archiviate nel suo database e quali algoritmi statistici vengono usati nelle varie analisi. Infatti, le tabelle dati analizzate sono sempre costituite da righe e colonne le cui intestazioni corrispondono alle unità di analisi archiviate nel database, mentre gli algoritmi regolano i processi che consentono di individuare relazioni significative tra i dati e di estrarre utili informazioni. Le unità di analisi di T-LAB sono di due tipi: unità lessicali e unità di contesto. A - le UNITA' LESSICALI sono parole, singole o multiple, archiviate e classificate in base a un qualche criterio. Più precisamente, nel database T-LAB ogni unità lessicale costituisce un record classificato con due campi: forma e lemma. Nel primo campo, denominato forma, sono elencate le parole così come compaiono nel corpus, mentre nel secondo, denominato lemma, sono elencate le label attribuite a gruppi di unità lessicali classificate secondo criteri linguistici (es. lemmatizzazione) o tramite dizionari e griglie semantiche definite dall'utilizzatore. B - le UNITA' DI CONTESTO sono porzioni di testo in cui può essere suddiviso il corpus. Più esattamente, nella logica T-LAB, le unità di contesto possono essere di tre tipi: B.1 documenti primari,
corrispondenti alla suddivisione "naturale" del corpus (es.
interviste, articoli, risposte a domande aperte, etc.), ovvero ai
contesti iniziali definiti
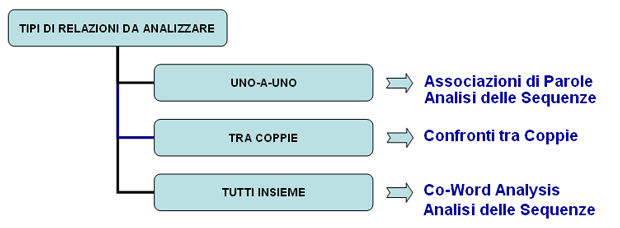
dall'utilizzatore; Il diagramma seguente illustra le possibili relazioni tra unità lessicali e unità di contesto che T-LAB ci permette di analizzare.
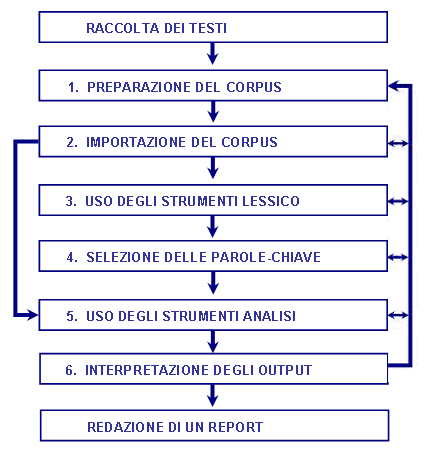
A partire da questa organizzazione del database, T-LAB consente - in modo automatico - di esplorare e di analizzare le relazioni tra le unità di analisi di tutto il corpus o di suoi sottoinsiemi. In T-LAB, la selezione di un qualsivoglia strumento di analisi (click del mouse) attiva sempre un processo semiautomatico che, con poche e semplici operazioni, genera qualche tabella input, applica qualche algoritmo di tipo statistico e produce alcuni output. In ipotesi, un tipico progetto di lavoro in cui viene usato T-LAB è costituito dall'insieme delle attività analitiche (operazioni) che hanno per oggetto il medesimo corpus ed è organizzato da una strategia e da un piano dell'utilizzatore. Quindi, inizia con la raccolta dei testi da analizzare e termina con la redazione di un report.
Proviamo ora a commentare le varie fasi una dopo l'altra:
Nel caso di un unico testo (o di un corpus trattato come unico testo) T-LAB non richiede ulteriori accorgimenti. Quando, invece, il corpus è costituito da più testi e vengono utilizzate codifiche che rinviano all'uso di qualche variabile, nella fase di preparazione bisogna utilizzare il modulo Corpus Builderr che - in maniera automatica - procede alla trasformazione di vari materiali testuali in un file corpus pronto per essere importato da T-LAB. N.B.:
Nella fase di pre-processing realizza i seguenti trattamenti:
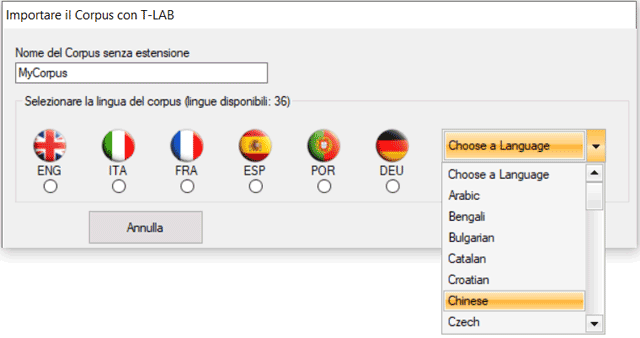
Di seguito la lista complete delle trenta (30) lingue per
le quali T-LAB
supporta la lemmatizzazione automatica o lo stemming. In ogni caso, senza lemmatizzazione automatica e/o usando dizionari personalizzati, possono essere analizzati testi in tutte le lingue le cui parole siano separate da spazi e/o da punteggiatura.
A partire dalla selezione della lingua, l'intervento dell'utilizzatore è richiesto per definire le scelte indicate nella finestra seguente:
N.B.: Poiché i trattamenti preliminari determinano il tipo e la quantità delle unità di analisi (cioè quali e quante unità di contesto e quali e quante unità lessicali), scelte diverse in questa fase comportano risultati diversi delle successive analisi. Per questa ragione, tutti gli output T-LAB mostrati nel manuale e nell'help hanno solo valore indicativo.
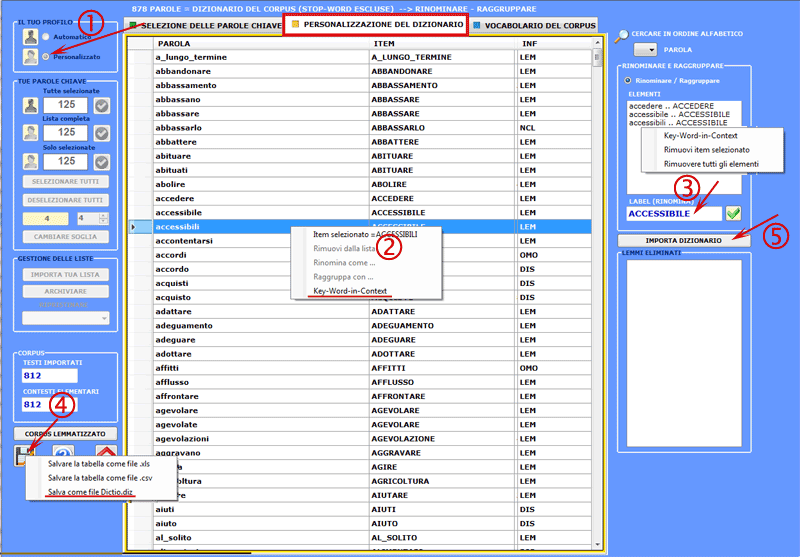
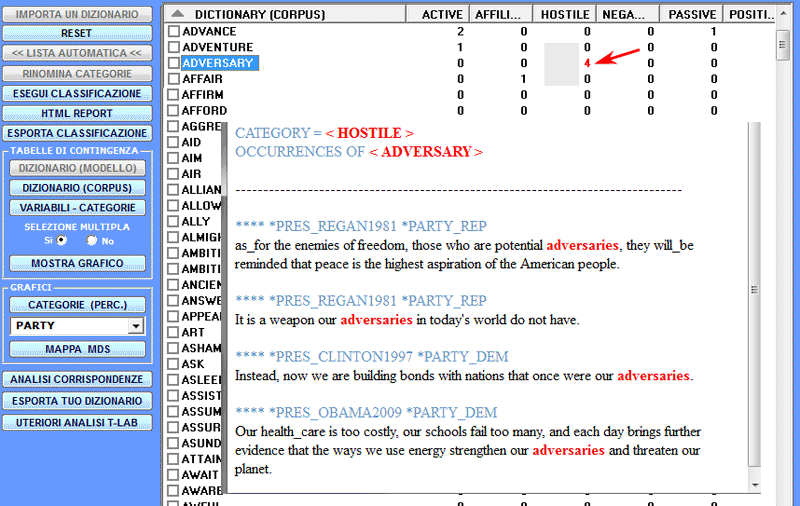
Le modalità dei vari interventi sono illustrate nelle corrispondenti voci dell'help (e del manuale). In particolare si rinvia alla corrispondente voce dell'help (e del manuale) per una dettagliata descrizione del processo Personalizzazione del Dizionario (vedi sotto). Infatti, qualsiasi modifica relativa alle voci del dizionario (es., raggruppamento di due o più item) incide sia sul calcolo delle occorrenze che su quello delle co-occorrenze.
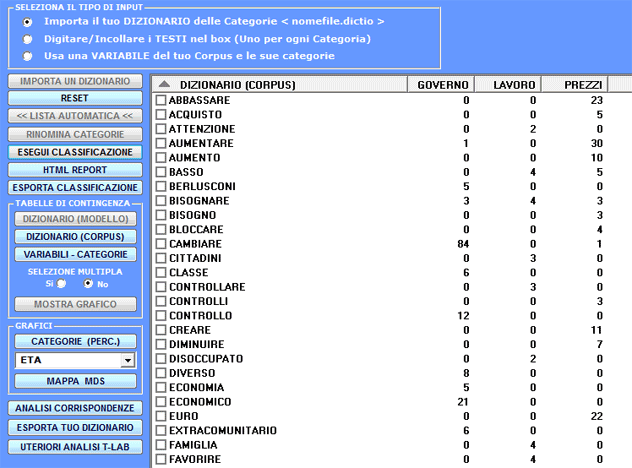
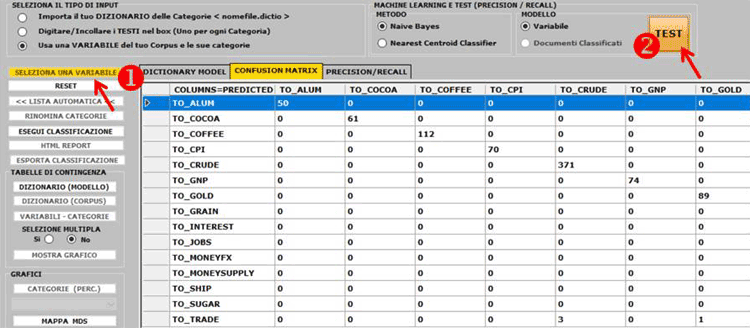
N.B.: Quando l'utilizzatore, senza perdere alcuna informazione lessicale, intende applicare schemi di codifica che raggruppano più parole o lemmi in poche categorie (da 2 a 50) è consigliabile utilizzare lo strumento Classificazione Basata su Dizionari incluso nel sottomenu Analisi Tematiche (vedi sotto).
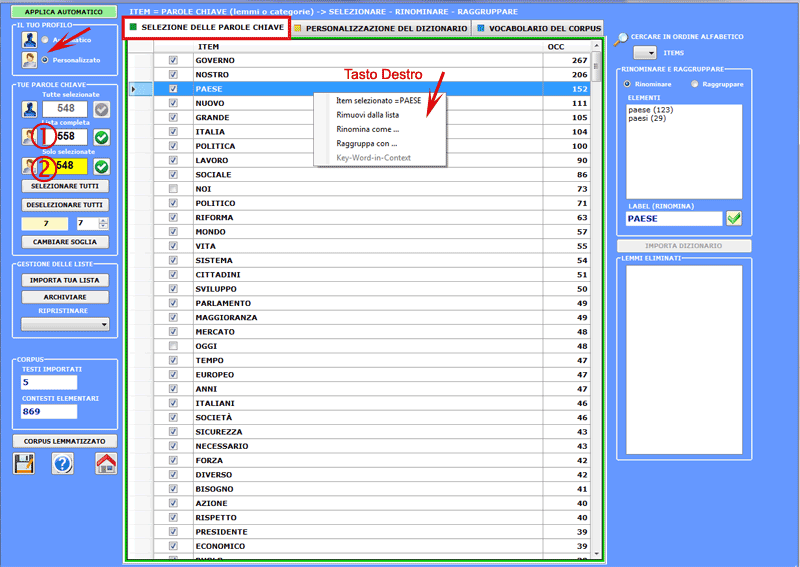
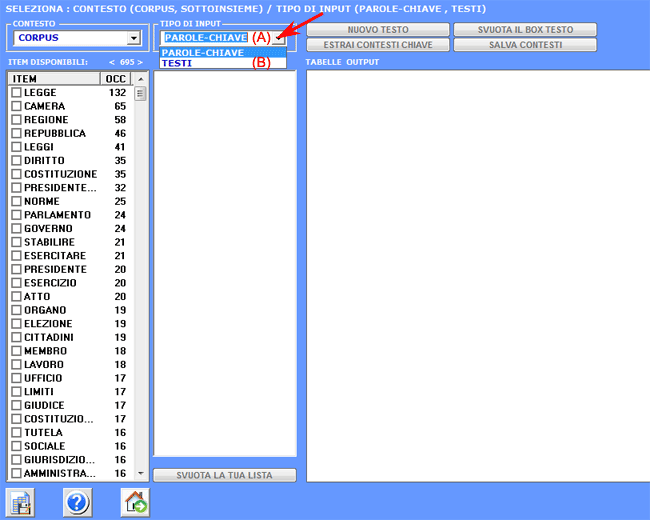
4 - LA SELEZIONE DELLE PAROLE-CHIAVE consiste nella predisposizione di una o più liste di unità lessicali (parole, lemmi o categorie) da utilizzare per costruire le tabelle dati da analizzare. L'opzione impostazioni automatiche rende disponibile liste di parole chiave selezionate da T-LAB; tuttavia, poiché la scelta delle unità di analisi è estremamente rilevante ai fini delle successive elaborazioni, si consiglia vivamente l'uso delle impostazioni personalizzate. In questo modo l'utilizzatore potrà scegliere di modificare la lista suggerita da T-LAB e/o di costruire liste che meglio corrispondono ai suoi obiettivi di indagine.
In ogni caso, nella costruzione di queste liste, valgono i seguenti criteri: - verificare la rilevanza
quantitativa (totale delle occorrenze) e qualitativa (non banalità
del significato) dei vari item; 5 - L'USO DEGLI STRUMENTI DI ANALISI è finalizzato alla produzione di output (grafici e tabelle) che rappresentano relazioni significative tra le unità di analisi e che consentono di fare inferenze. Attualmente T-LAB
include venti diversi strumenti di analisi, ciascuno dei quali
funziona con una sua specifica logica; cioè, usa specifici
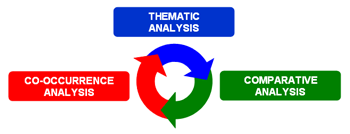
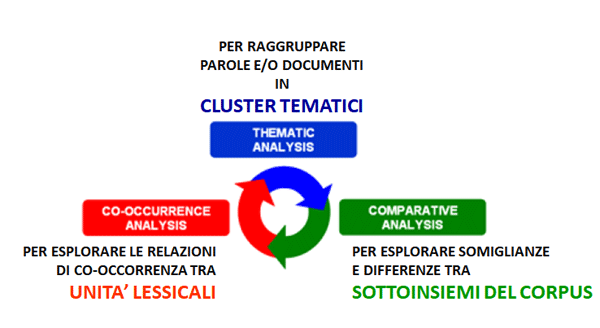
algoritmi e produce specifici output. A questo proposito, oltre alla distinzione fra strumenti per analisi delle co-occorrenze, per analisi comparative e per analisi tematiche, è utile considerare che alcuni di questi ultimi consentono di ottenere ulteriori sottoinsiemi del corpus basati su similarità di contenuto.
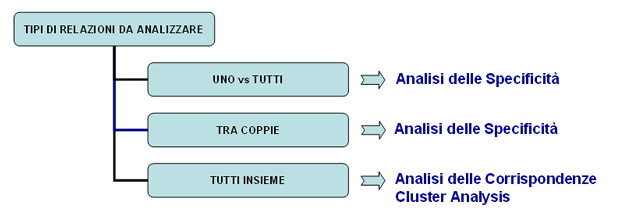
In generale, anche se l'uso degli strumenti T-LAB può essere circolare e reversibile, possiamo individuare tre punti di avvio (start points) che corrispondono ai tre sub-menu ANALISI:
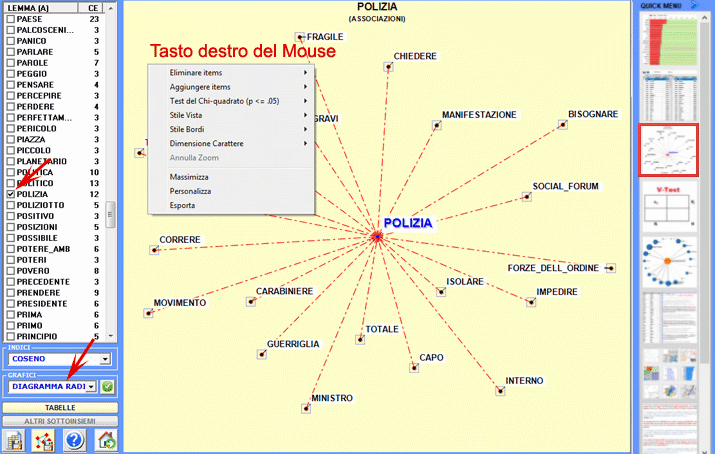
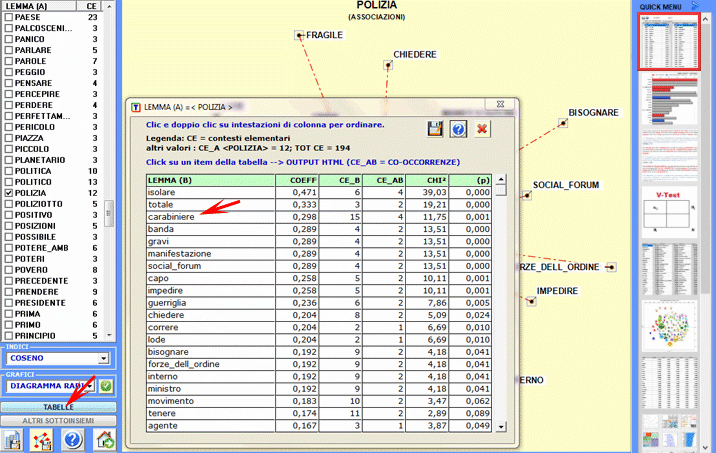
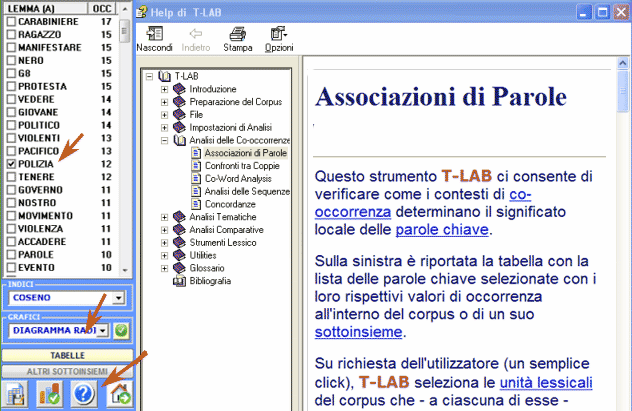
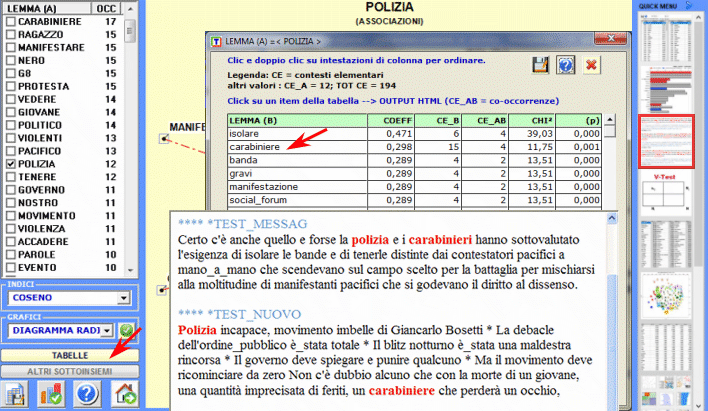
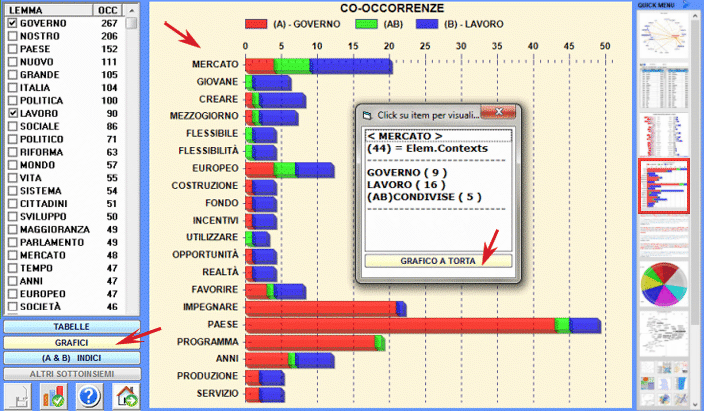
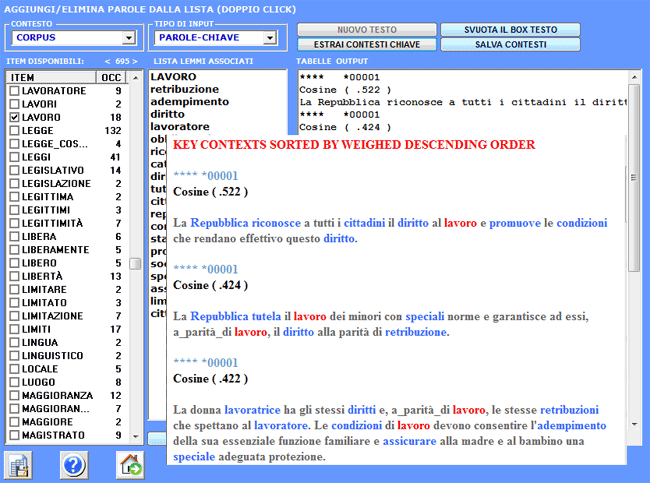
Ecco alcuni esempi di output (N.B.: per ulteriori informazioni sulla interpretazione degli output si rimanda alle corrispondenti sezioni della guida / manuale): Questo strumento T-LAB ci consente di verificare come i contesti di co-occorrenza determinano il significato locale delle parole chiave.
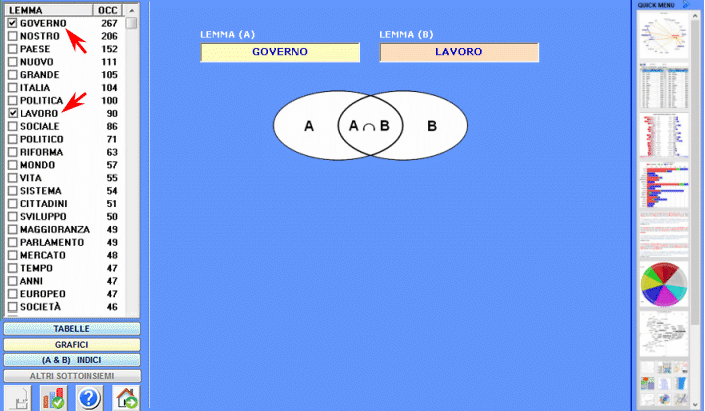
Questo strumento T-LAB consente di confrontare insiemi di contesti elementari (cioè contesti di co-occorrenza) in cui sono presenti gli elementi di una coppia di parole chiave.
L'uso di questa funzione T-LAB consente di analizzare le relazioni di co-occorrenza all'interno di gruppi di parole chiave.
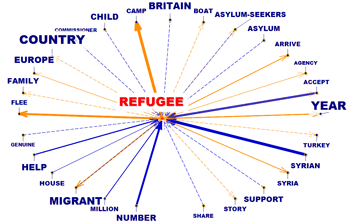
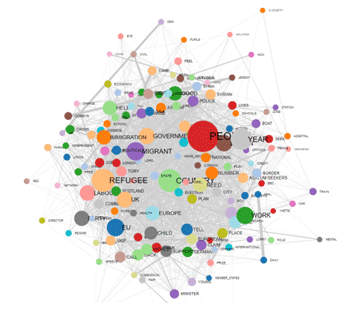
Questo strumento T-LAB tiene conto delle posizioni delle varie unità lessicali all'interno delle frasi e ci permette di rappresentare ed esplorare qualsiasi testo come una rete di relazioni. Ciò significa, dopo aver eseguito questo tipo di analisi, l'utilizzatore può verificare le relazioni tra i nodi della rete (cioè le parole chiave) a diversi livelli: a) in relazioni del tipo uno-a-uno; b) all'interno di 'ego network'; c) all'interno delle 'comunità' acui appartengono; d) all'interno dell'intera rete costituita dal testo in analisi.
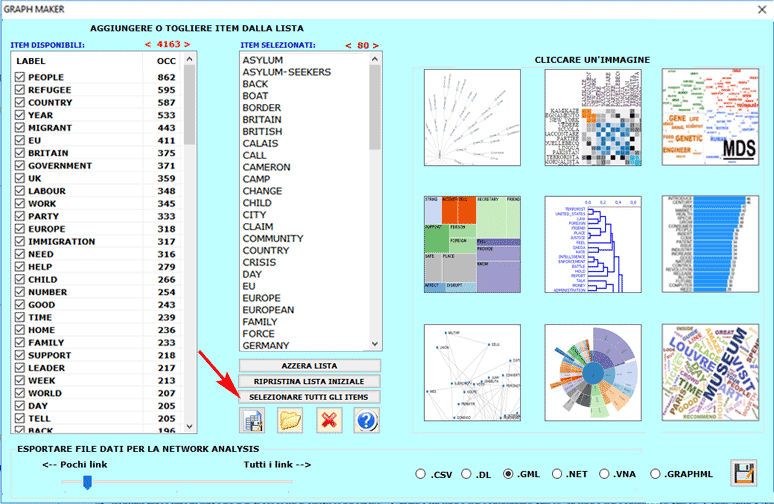
Inoltre, facendo clic sull'opzione GRAPH MAKER, l'utente può creare diversi tipi
di grafici utilizzando elenchi personalizzati di parole chiave
(vedi sotto).
B : STRUMENTI PER ANALISI COMPARATIVE Questi strumenti consentono di analizzare vari tipi di relazioni tra le unità di contesto.
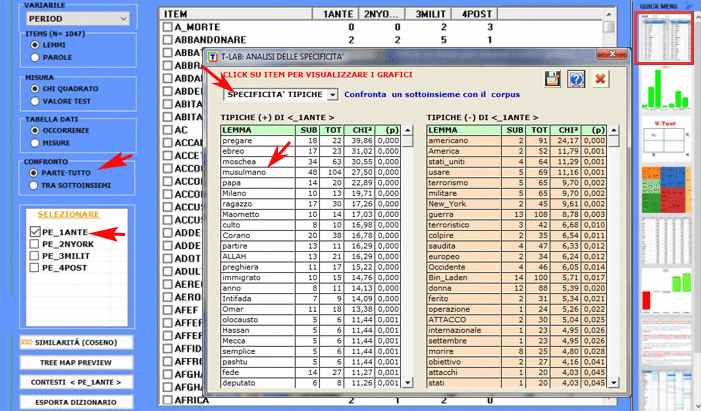
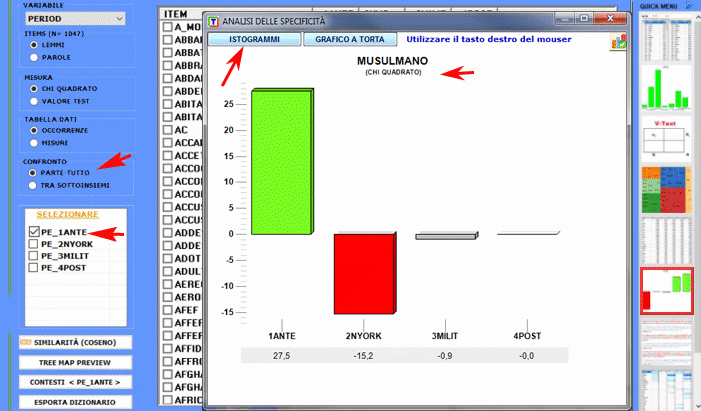
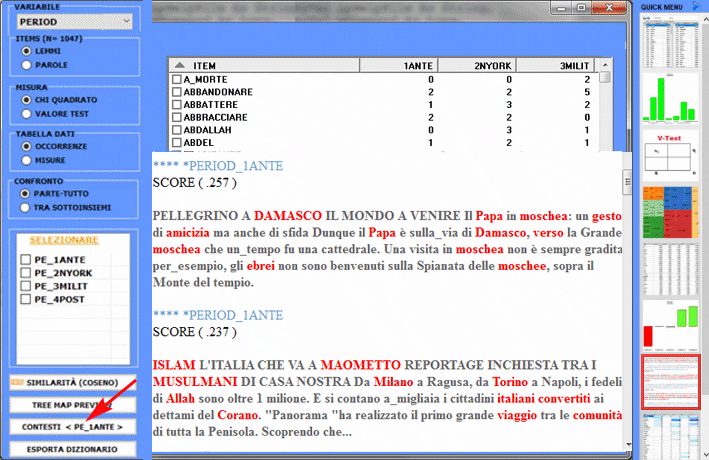
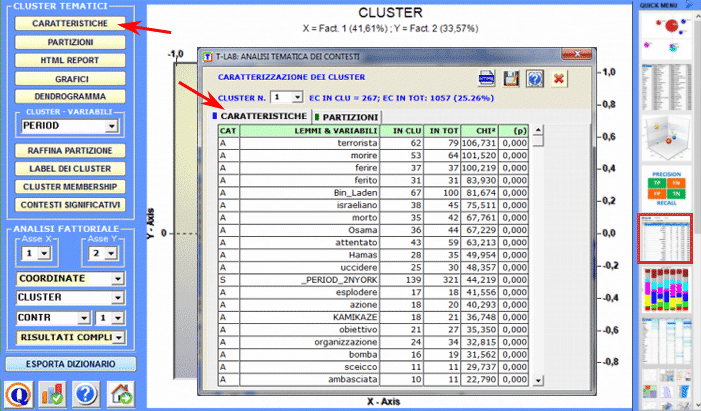
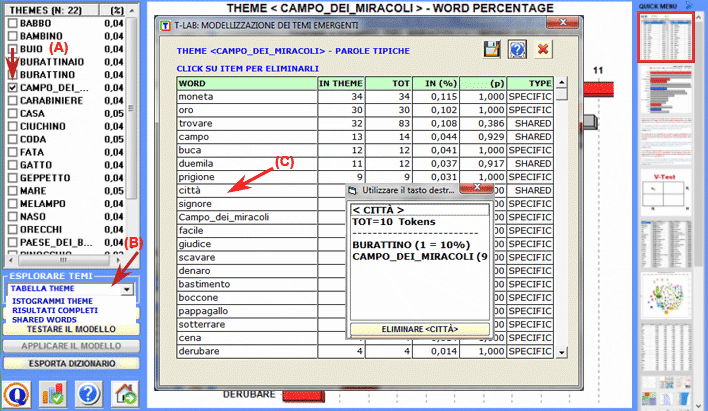
L'Analisi delle Specificità consente di verificare quali parole sono 'tipiche' o 'esclusive' di ogni specifico sottoinsieme del corpus. Inoltre permette di estrarre i 'contesti tipici', cioè i contesti elementari caratteristici, di ciascuno dei sottoinsiemi analizzati (ad esempio, le 'tipiche' frasi usate da specifiche leader politici).
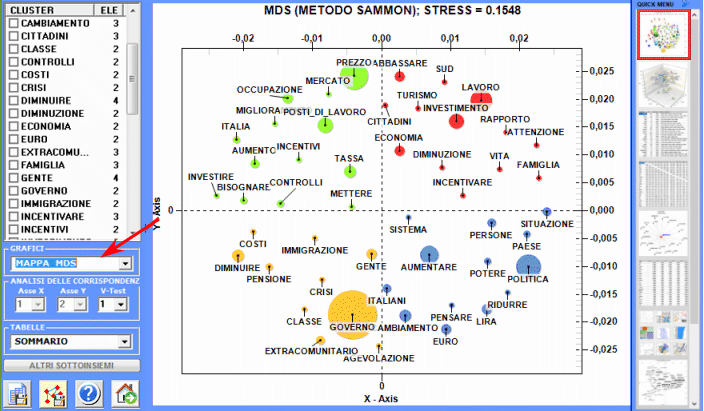
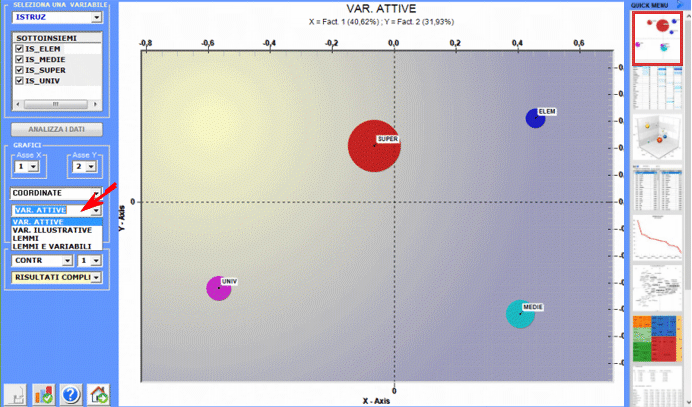
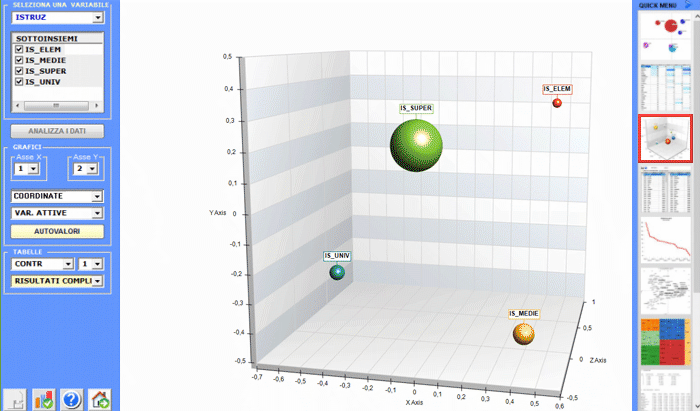
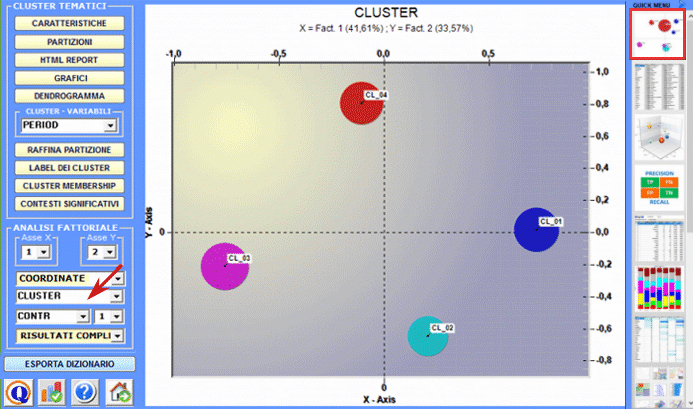
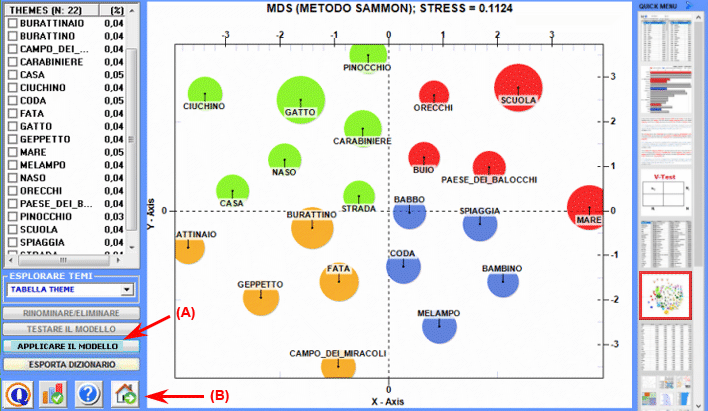
L'Analisi delle Corrispondenze consente di esplorare vari tipi di relazioni (somiglianze e differenze) tra gruppi di unità di contesto.
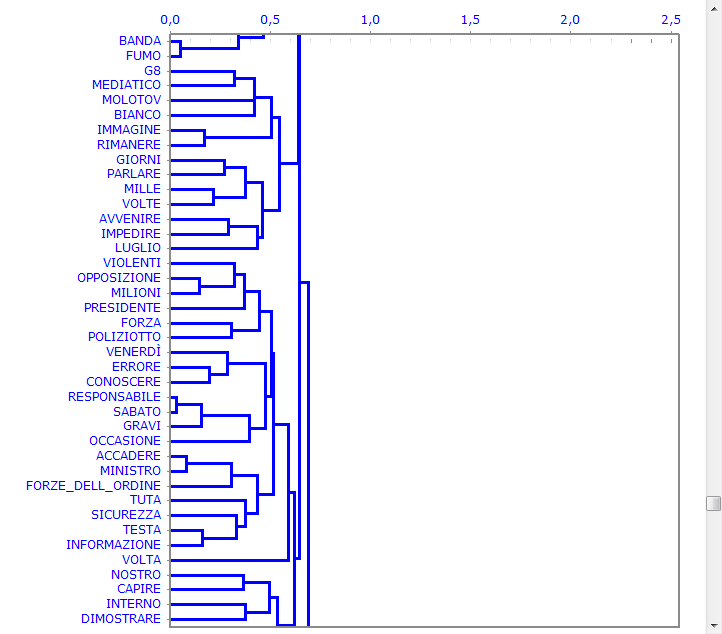
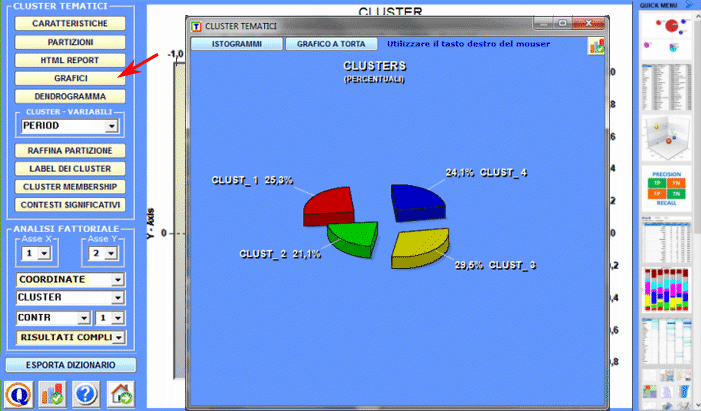
La Cluster Analysis, che può essere effettuata con varie tecniche, consente di individuare gruppi di unità di analisi che abbiano due caratteristiche complementari: massima omogeneità al loro interno e massima eterogeneità tra ciascuno di essi e gli altri.
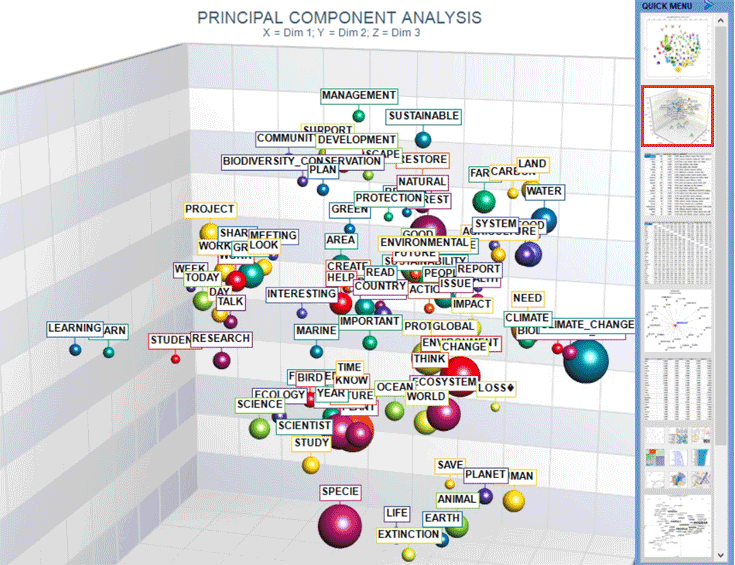
C : STRUMENTI PER ANALISI TEMATICHE Questi strumenti consentono di individuare, esaminare e mappare i "temi" presenti nei testi analizzati.
1 - un cluster tematico di unità di contesto caratterizzate dagli stessi pattern di parole chiave (vedi gli strumenti Analisi Tematica dei Contesti Elementari, Classificazione Tematica dei Documenti e Classificazione basata su Dizionari); 2 - un gruppo tematico di parole-chiave classificate come appartenenti alla stessa categoria (vedi lo strumento Classificazione Basata su Dizionari); 3 - una componente di un modello probabilistico che rappresenta ogni unità di contesto (sia essa un contesto elementare o un documento) come generato da una mistura di "temi" o "topics" (vedi gli strumenti Modellizzazione dei Temi Emergenti e Testi e Discorsi come Sistemi Dinamici); 4 - una specifica
parola chiave usata per estrarre un
insieme di contesti elementari in cui essa è associata con uno
specifico gruppo di parole preselezionate dall'utilizzatore (vedi
lo strumento Contesti Chiave di Parole
Tematiche);
1 - sia l' Analisi Tematica dei
Contesti Elementari che la Classificazione Tematica dei Documenti
funzionano nel modo seguente: a- realizzano un'analisi delle
co-occorrenze per individuare cluster tematici di unità di
contesto;
2 - tramite lo strumento Classificazione Basata su Dizionari possiamo
facilmente costruire / testare / applicare modelli (ad esempio
dizionari di categorie) sia per la classica analisi di contenuto
che per la sentiment analysis. Infatti questo strumento ci permette
di eseguire una classificazione automatica di tipo top-down sia
delle unità lessicali (cioè parole e lemmi) che delle unità di
contesto (cioè frasi, paragrafi e documenti
brevi).
4 - lo strumento Contesti Chiave
di Parole Tematiche può essere utilizzato per due diversi
scopi: (a) estrarre elenchi di unità di contesto (cioè contesti
elementari) che permettono di approfondire il valore tematico di
specifiche parole chiave; (b) estrarre gruppi di unità di contesto
che risultano simili a una qualche testo 'esempio' scelto
dall'utilizzatore.
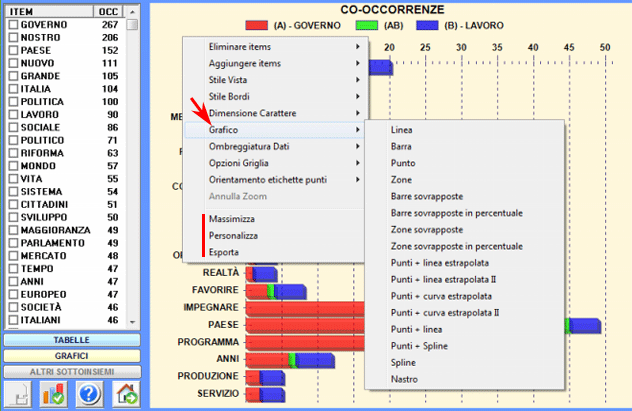
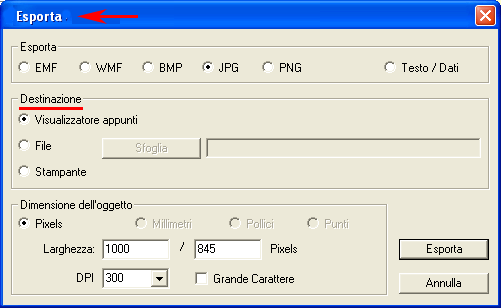
6 - L' INTERPRETAZIONE DEGLI OUTPUT consiste nella consultazione delle tabelle e dei grafici prodotti da T-LAB, nell'eventuale personalizzazione del loro formato e nel fare inferenze sul significato delle relazioni in essi rappresentate. Nel caso delle tabelle, a seconda dei casi, T-LAB consente di esportarle in file con le seguenti estensioni: .DAT, .TXT, .CSV, .XLXS, .HTML. Ciò significa che, servendosi di qualunque editore di testi e/o di un qualche applicativo della suite Microsoft Office, l'utilizzatore può facilmente importarli e rielaborarli. Nel caso dei grafici, appositi sub-menu attivati con il tasto destro del mouse consentono vari tipi di operazioni: zoom (clic con il tasto sinistro e selezionare un rettangolo), massimizzazione, personalizzazione ed esportazione degli output in diversi formati (vedi sotto, uso del tasto destro).
Alcuni criteri generali per l'interpretazione degli output T-LAB sono illustrati in un paper citato in Bibliografia (Lancia F.: 2007) e disponibile nel sito www.tlab.it. In questo viene proposta l'ipotesi che gli output delle elaborazioni statistiche (tabelle e grafici) sono un tipo particolare di testi, cioè degli oggetti multi-semiotici caratterizzati dal fatto che le relazioni tra segni e simboli sono ordinate da misure che rinviano a specifici codici. In altri termini, sia nel caso dei testi scritti in linguaggio naturale che in quelli scritti nel linguaggio della statistica, la possibilità di fare inferenze sulle relazioni che organizzano le forme del contenuto è fondata sul fatto che le relazioni tra le forme dell'espressione non sono casuali (random); infatti, nel primo caso (linguaggio naturale) le unità significanti si susseguono ordinate in modo lineare (una dopo l'altra nella catena del discorso), mentre nel secondo caso (tabelle e grafici) i principi di ordinamento sono costituiti dalle misure che determinano l'organizzazione degli spazi semantici multidimensionali. Anche se gli spazi semantici rappresentati nelle mappe T-LAB sono molto vari, e ciascuno di essi richiede specifiche procedure interpretative, possiamo fare l'ipotesi che - in generale - la logica del processo inferenziale è la seguente: A - rilevare una qualche relazione
significativa tra le unità "presenti" sul piano dell'espressione
(ad es. tra "dati" di tabelle e/o tra "label" di grafici);
|