29 November 2022
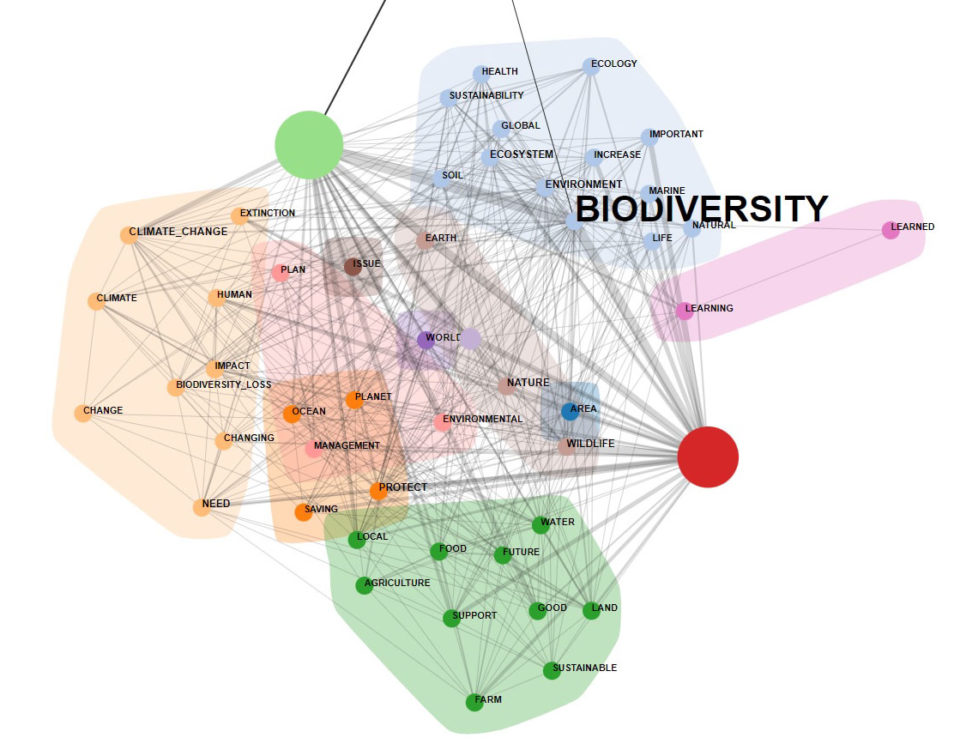
A new analysis tool, named Co-occurrence Toolkit, has been added, which includes about a fifteen options for building and analysing word co-occurrence matrices with up to 5,000 columns.
The new analysis options include various clustering methods, measures like Assortativity Coefficient, Clustering Coefficient, Entropy, Positive Pointwise Mutual Information and also five Centrality measures.
When using the Co-Word Analysis tool, a new interactive dendrogram is available which allows the user to explore the relationships between up 3,000 (three thousand) key-words...
The new analysis options include various clustering methods, measures like Assortativity Coefficient, Clustering Coefficient, Entropy, Positive Pointwise Mutual Information and also five Centrality measures.
When using the Co-Word Analysis tool, a new interactive dendrogram is available which allows the user to explore the relationships between up 3,000 (three thousand) key-words...
16 October 2021
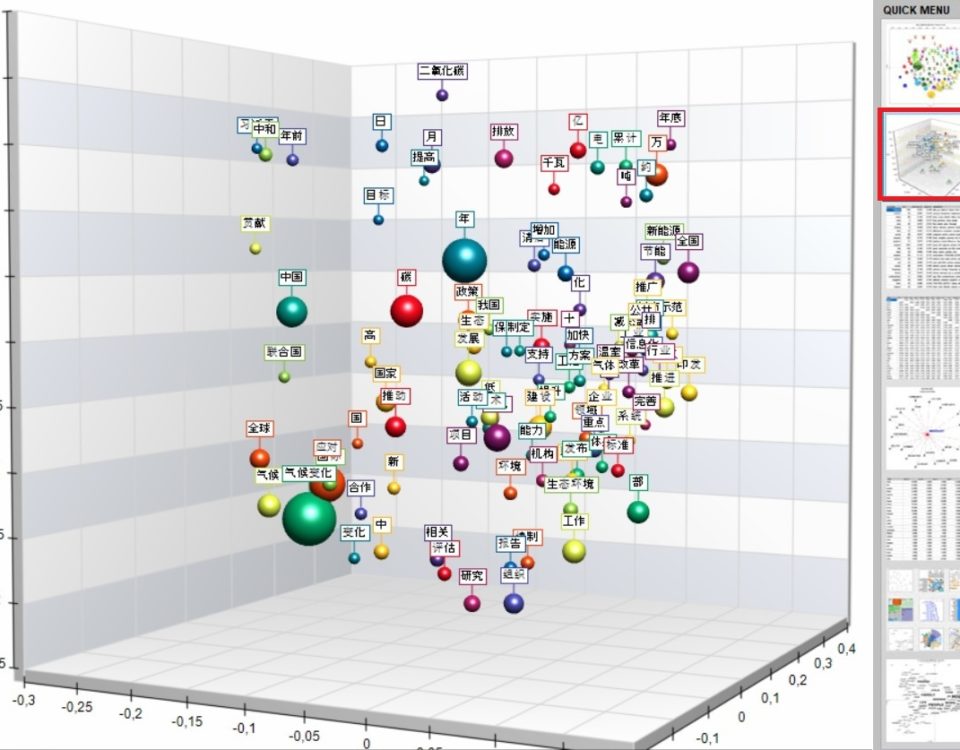
The way T-LAB processes Chinese texts has been refined and three built-it examples in this language have been added.
Now the Corpus Builder tool allows one to easily import data in three further formats: .SAV (i.e. Spss files), .JSON (e.g. Twitter data) and .XML. Moreover, the process through which T-LAB generates a corpus from a data table with thousands of records is faster.
Latest update (5 May 2022): automatic lemmatisation for Latin language added...
Now the Corpus Builder tool allows one to easily import data in three further formats: .SAV (i.e. Spss files), .JSON (e.g. Twitter data) and .XML. Moreover, the process through which T-LAB generates a corpus from a data table with thousands of records is faster.
Latest update (5 May 2022): automatic lemmatisation for Latin language added...
14 October 2020
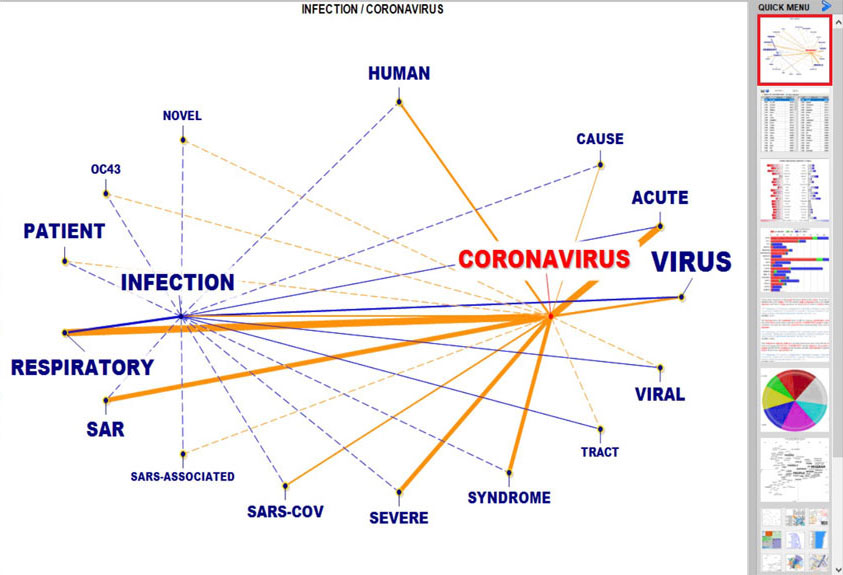
Now the main analysis tools include a quick access gallery of pictures which works as an additional menu and allows one to switch between various outputs with a single click. This way non-expert users can easily familiarize themselves with the software.
A new wizard has been added which allows one to easily classify new documents according to a pre-existing model and also to compare any new document with all documents included in a corpus already analysed ...
A new wizard has been added which allows one to easily classify new documents according to a pre-existing model and also to compare any new document with all documents included in a corpus already analysed ...
16 September 2019
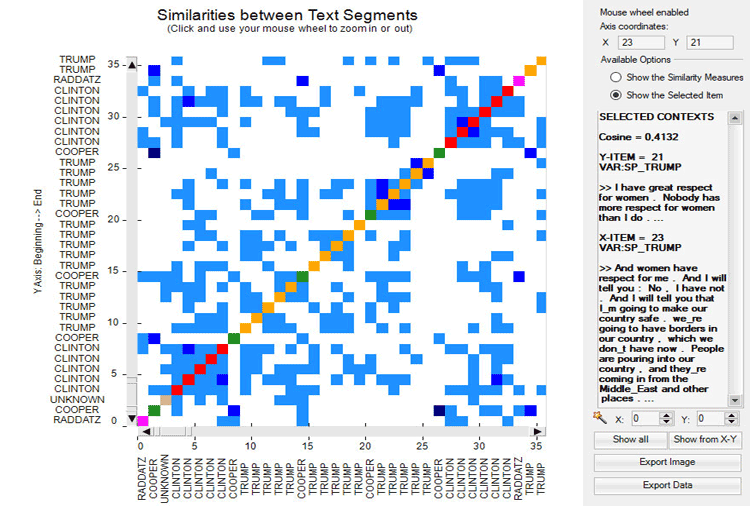
The main menu, which has been redesigned, is now easier to use.
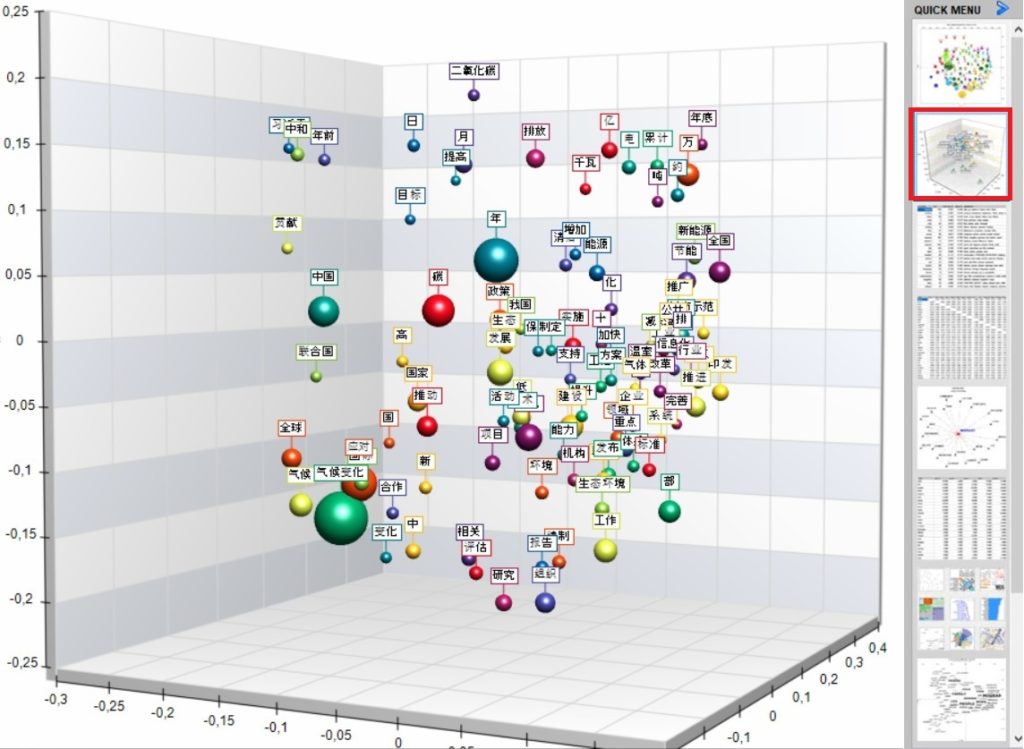
All T-LAB tools which include the 3d bubble chart option now use a new type of visualization which is highly customizable.
A new tool named ‘Texts and Discourses as Dynamic Systems’ has been added which integrates various state of the art algorithms already present in T-LAB with the Recurrence Quantification Analysis...
All T-LAB tools which include the 3d bubble chart option now use a new type of visualization which is highly customizable.
A new tool named ‘Texts and Discourses as Dynamic Systems’ has been added which integrates various state of the art algorithms already present in T-LAB with the Recurrence Quantification Analysis...
6 February 2019

Here is a short list of the most significant improvements made in this version of the software.
The Concordances tool now includes a new option which allows the user to build/explore a dynamic Word-Tree of any selected item;
The way the Corpus Builder tool manages the CSV files in different languages has been significantly improved ...
The Concordances tool now includes a new option which allows the user to build/explore a dynamic Word-Tree of any selected item;
The way the Corpus Builder tool manages the CSV files in different languages has been significantly improved ...
6 January 2018
{kind=link}
{kind=link}
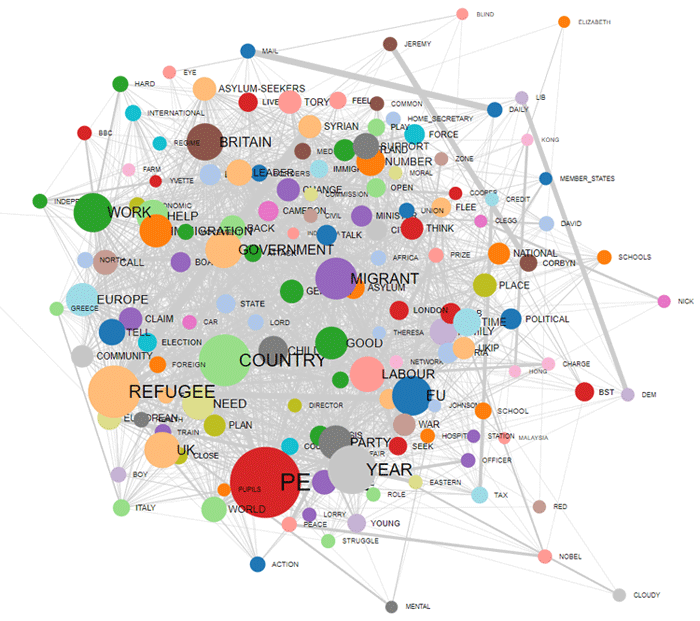
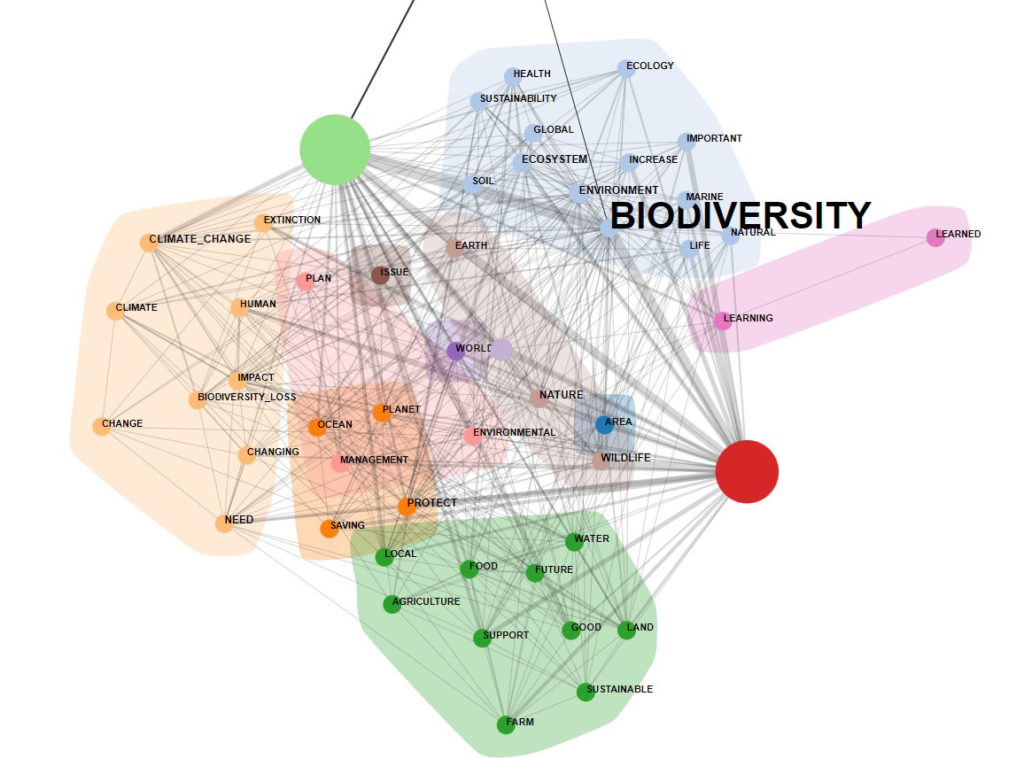
The Sequence and Network Analysis tool, which takes into account the positions of words relative to each other (i.e. transition probabilities), has been completely redesigned and now the user is able to check the relationships between the 'nodes' (i.e. the key-terms) of the text network at different levels …