|
www.tlab.it
Configuration Automatique et
Configuration Personnalisée
Le choix de la configuration automatique (A) ou personnalisée (B) concerne la liste des mots-clés utilisés dans toutes les analyses
effectuées au moyen de T-LAB.
Ce choix est réversible jusqu'à ce que l'utilisateur n' effectue
pas des opérations qui modifient le Dictionnaire du corpus.
A) CONFIGURATION AUTOMATIQUE
Le choix de la configuration
automatique signifie que la liste des mots-clés comprenne
jusqu'à 5000 unités lexicales
sélectionnées automatiquement par T-LAB et appartenant aux
catégories grammaticales qui sont plus denses de sens: noms,
verbes, adjectifs et adverbes.
Le critère de sélection change selon le genre de fichier
analysé.
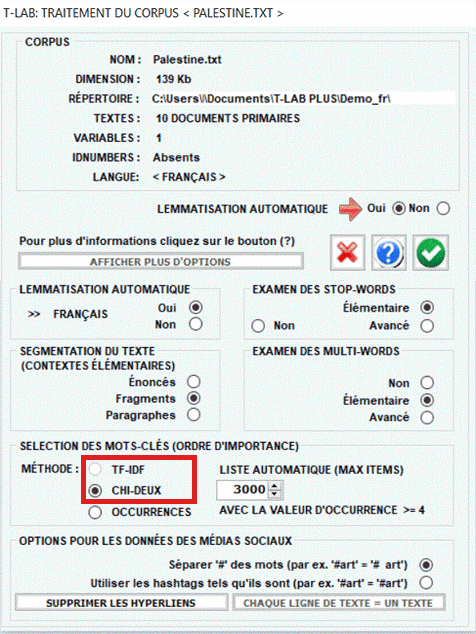
Si le corpus est un texte unique T-LAB choisit simplement les mots avec les
valeurs d'occurrence les plus élevées.
Quand le corpus se compose de deux textes ou plus
T-LAB emploie l'algorithme
suivant:
a) il choisit les mots avec les valeurs d'occurrence plus
élevées que le seuil minimum;
b) il applique le TF-IDF ou le test du chi-deux à toutes les croix de chaque mot
pour tous les textes analysés (N.B. : Dans le cas du chi-deux, les
textes analysés doivent être maximum 500);
c) il choisit les mots avec les valeurs du TF-IDF ou du chi-deux
les plus élevées, c'est-à-dire les mots qui, dans le corpus, font
la différence.
N.B.:
Dans le cas où le corpus est constitué par deux ou plusieurs
textes, l'utilisateur peut choisir le critère de sélection
(chi-carré ou bien TF-IDF) dans le stade de l'importation (voir
ci-dessous).
- Lorsque l' option pour la configuration automatique est activée, le tableau
avec la liste des Mots-clés inclut une colonne 'T-LAB' qui indique
l' importance de chaque élément selon le critère sélectionné (voir
ci-dessous)..
B) CONFIGURATION PERSONNALISEE
Le choix de la configuration personnalisée permet à
l' utilisateur de sélectionner, renommer et
regrouper les unités lexicales (mots, lemmes ou catégories)
à inclure dans les analyses successives de T-LAB.
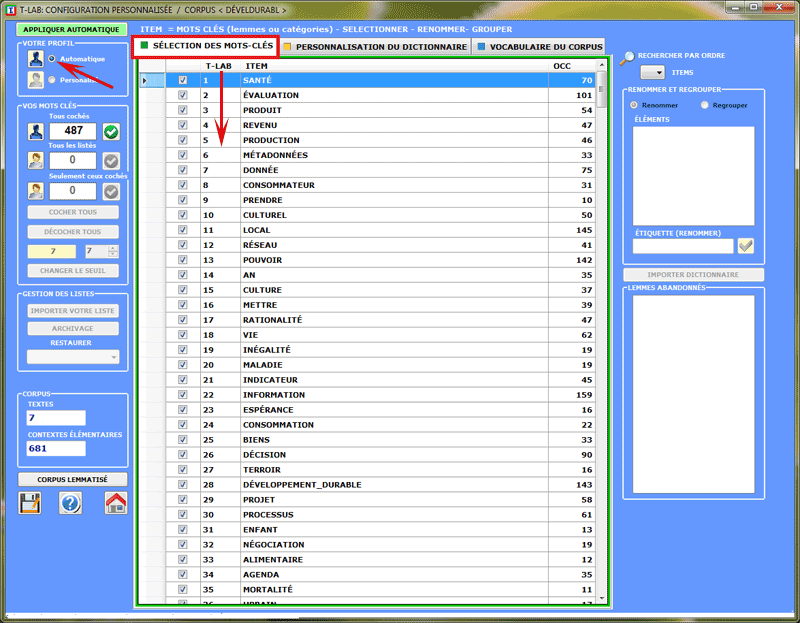
Dans le tableau est reportée la liste (liste 1) des
unités lexicales avec des valeurs d'occurrence égales ou
supérieures au seuil préfixé. Certaines
d'entre elles, celles indiquées avec un "v", font partie d'une
sous-liste (liste 2) proposée par T-LAB (voir Configuration Automatique).
En fonction des analyses qu'il entend effectuer, l'utilisateur peut
décider d'utiliser/modifier la liste (1) ou la liste
(2).
Dans les deux cas les opérations possibles sont les
suivantes:
- modifier la valeur de
seuil;
- sélectionner les lemmes à
rejeter de l'analyse;
- rétablir l'utilisation d'un
lemme ou plus;
- sélectionner/de-sélectionner
les items à utiliser.
Un clic sur le bouton "utiliser liste (1)" ou le
bouton "utiliser liste (2 )" rend active l'option "personnalisée"
des configurations d'analyse.
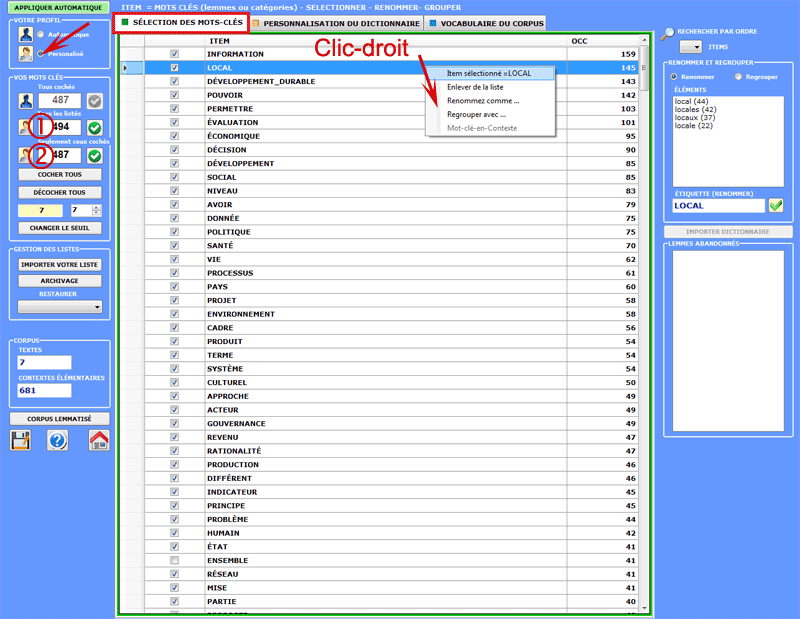
Les options qui concernent les interventions sur
les lemmes individuels sont accessibles par le bouton droit de la
souris en sélectionnant un élément quelconque du tableau (voir
ci-dessous ).
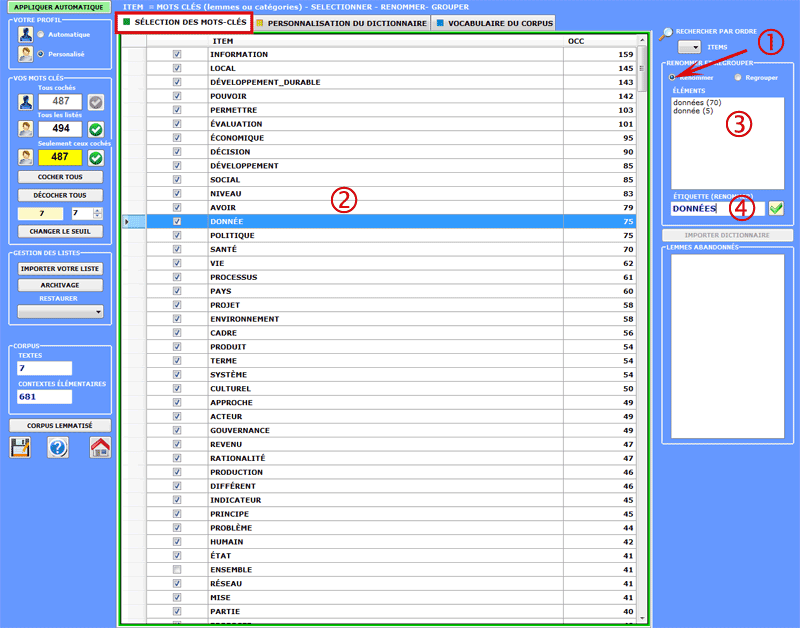
Pour renommer chaque lemme agir comme suit :
1. s' assurer que l' option
"renommer" soit active;
2. cliquer sur un item du tableau;
3. choisir un des mots
ou bien frapper un label à votre choix;
4. cliquer
sur "remplacer".
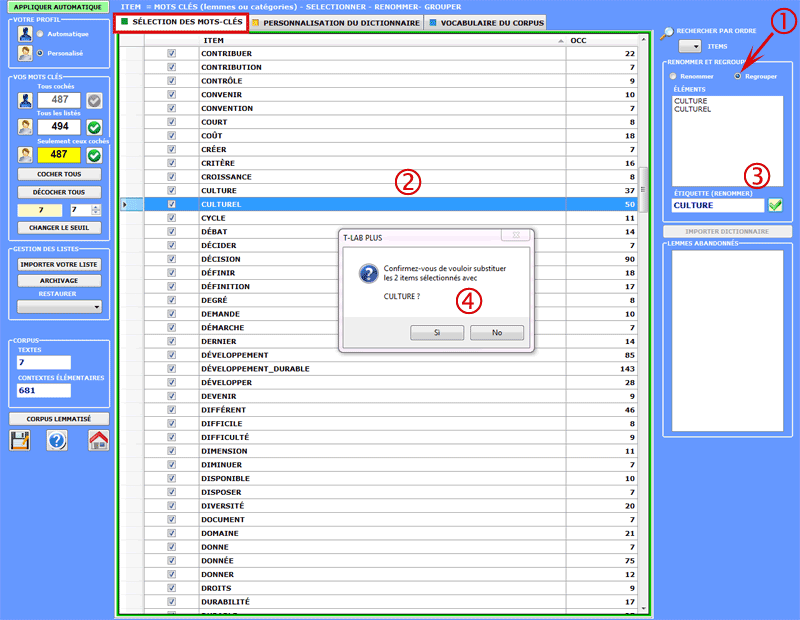
Les regroupements de deux ou plus lemmes doivent être
effectués comme suit :
1. sélectionner la modalité
"regroupements";
2. cliquer sur deux ou plus items du
tableau;
3. choisir (à l' aide d' un clic) un
des mots ou bien frapper un label à votre choix;
4. cliquer sur
"remplacer".
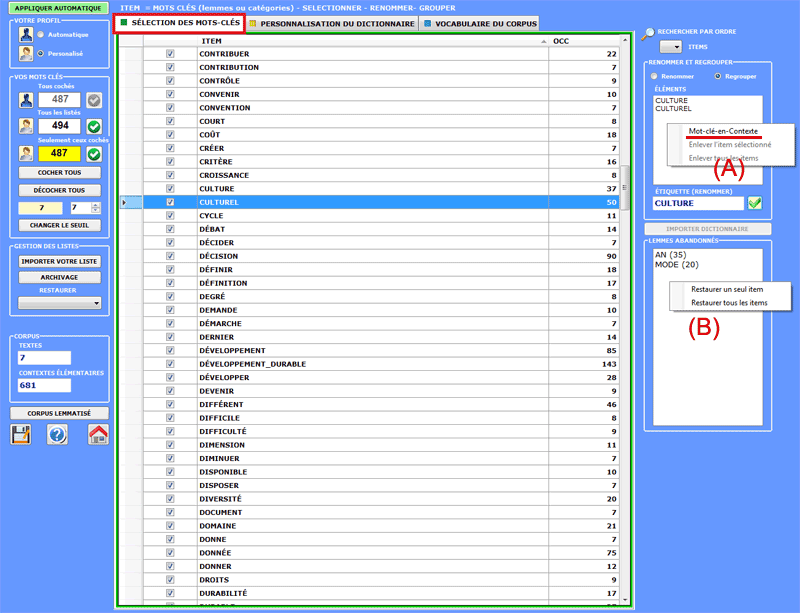
Des options supplémentaires peuvent être activées à
l'aide du bouton à droite dans la case
avec les éléments à renommer / regrouper (A) ou dans la case avec
les " lemmes supprimés " (B).
En particulier, lorsque - dans le cas (A) - on
sélectionne l' option "key-word-in-Context ", vous pouvez accéder
automatiquement à l'instrument Concordances et vérifier les contextes
d'occurrence des différents éléments (voir ci-dessous).
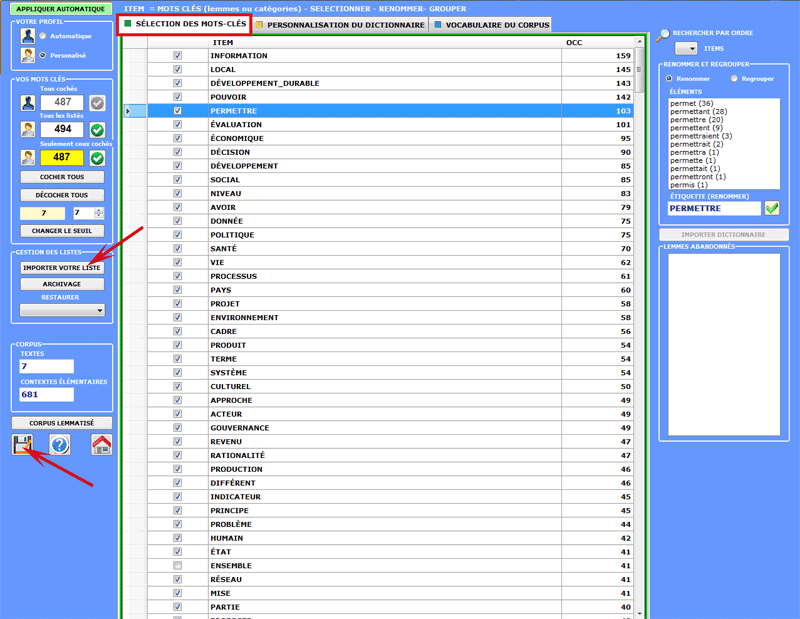
Un bouton spécifique (voir ci-dessous) vous permet
d'importer des listes personnalisées de
mots-clés.
Chaque liste à importer (ficher nommé MyList.diz), peut contenir
jusqu'à un maximum de 10.000 lignes (min = 20).
Chaque ligne de votre liste doit être un mot sans espaces
vides ni signes de ponctuation.
Un modèle de fichier MyList.diz est automatiquement créé
par T-LAB lors de
l'enregistrement de votre liste des mots clé (voir le bouton
approprié en bas à gauche).
Le paramétrage des analyses, à savoir aussi bien la
sélection des lemmes (ou catégories) que le dictionnaire utilisé,
peut être sauvegardé et récupéré à travers les boutons réservés à
cet usage. Ceci signifie que le même corpus -
sans avoir besoin d'être importé à nouveau - peut être analysé avec
différents dictionnaires et avec des sélections différentes de
mots-clés. Ceci pour un maximum de 10 differents
paramétrages.
En outre, dans T-LAB il est prévu que les paramétrages
puissent être revus en plusieurs sessions, même en utilisant
plusieurs fois la fonction Personnalisation
du Dictionnaire.
|


