|
www.tlab.it
Import a single file
...
In the case of a single document (or
a corpus considered as a single text) T-LAB 10
needs no further work: just select
the 'Import a single file…' option.
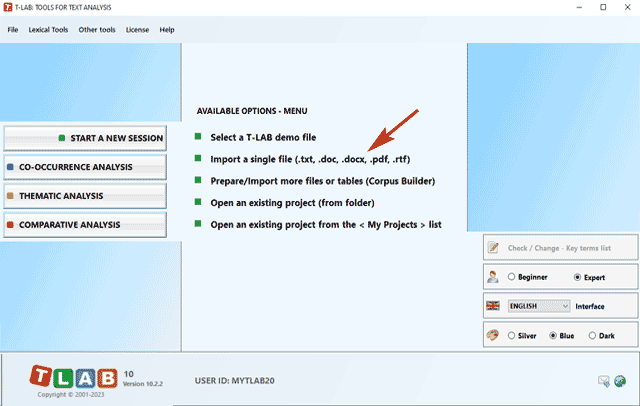
Then perform the following steps
(see the image below): (1) select any file; (2) choose the project
name; (3) select the language of your text; (4) click on
'Import'.
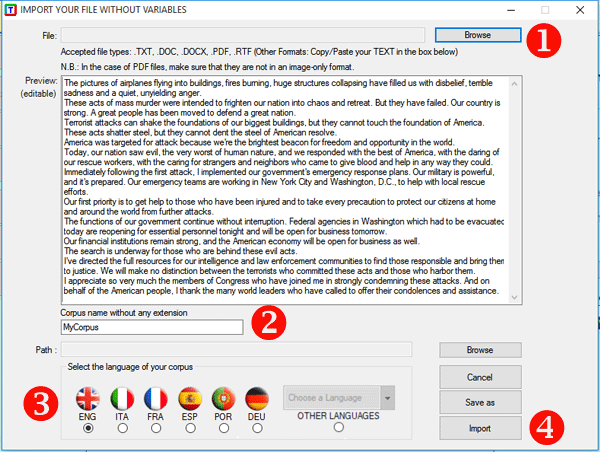
Subsequently
a setup form appears (see below) in which the user can make his
choices.
N.B.:
- As
the pre-processing options determine both the kind and the number
of analysis units (i.e. context units and lexical units), different
choices (see below the advanced options) determine different
analysis results. For this reason, all T-LAB
outputs (i.e. charts and tables) shown in the user’s
manual and in the on-line help are indicative only;
- All pre-processing steps are performed when importing any type of
corpus.
1 - AUTOMATIC LEMMATIZATION OR
STEMMING
Here is the complete list of the thirty (30) languages for which
the automatic lemmatization or the stemming process is supported by
T-LAB 10 .
LEMMATIZATION: Catalan, Croatian,
English, French, German, Italian, Latin, Polish, Portuguese,
Romanian, Russian, Serbian, Slovak , Spanish, Swedish,
Ukrainian.
STEMMING: Arabic, Bengali, Bulgarian,
Czech, Danish, Dutch, Finnish, Greek, Hindi, Hungarian, Indonesian,
Marathi, Norwegian, Persian, Turkish.
In any case, without automatic
lemmatization and / or by using customized dictionaries the user
can analyse texts in all languages, provided that words are
separated by spaces and / or punctuation.
The result of the lemmatization process can be verified by means of
the Vocabulary function and can be
modified by means of the Dictionary
Building function.
2 - TEXT SEGMENTATION (ELEMENTARY
CONTEXTS)
According to the user's choices, the elementary contexts for the
computation of co-occurrences can be
four: sentences, chunks of comparable length, paragraphs or short
texts (e.g. responses to open-ended questions).
The corpus_segments.dat file allows the user to verify the result
of corpus segmentation.
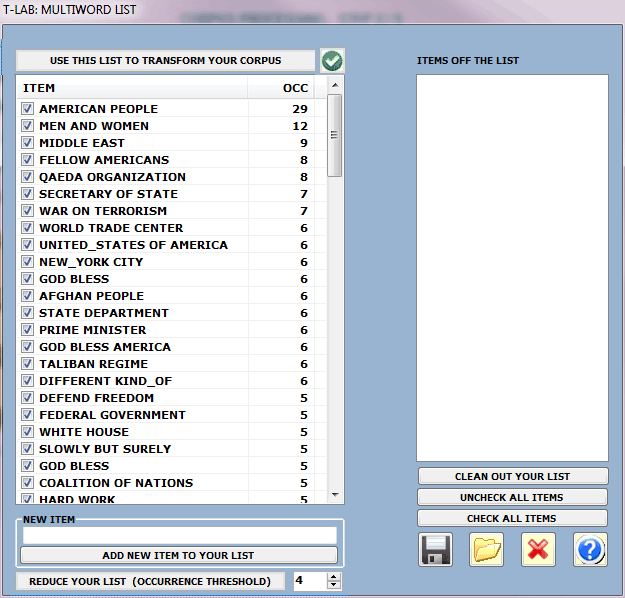
3 - MULTI-WORD CHECK
The "Basic" option activates the automatic use of
T-LAB
multi-word list.
Whereas the "Advanced" option, enabled with
automatic lemmatization only, allows the user:
- to verify and modify the list of multi-words not included in
the T-LAB
database;
- to import and use customized lists
(Multiwords.txt files).
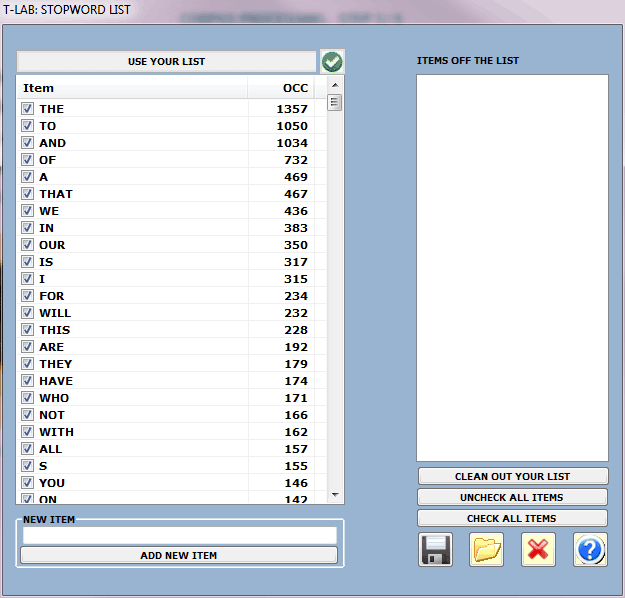
4 - STOP-WORD CHECK
The "Basic" option activates the automatic use of
T-LAB
stop-word list.
Differently the "Advanced" option
allows the user:
- to verify and modify the list of stop-words within the
corpus;
- to import and use customized lists
(StopWords.txt files).
5 - KEY-TERM SELECTION
Available options allow us to choose the selection method (TF-IDF or Chi-Square) and
the maximum number of lexical units to
be included in a list used by T-LAB
for analysing texts with automatic settings.
N.B.: When the importation process
is over, by using the customized
settings, the user can review the key-term selection and build
various lists to be applied.
|


